The Best GPUs for Local LLM Inference in 2025
The landscape for running large language models (LLMs) locally has transformed dramatically in 2025, with new GPU architectures, improved quantization techniques, and more sophisticated understanding of VRAM usage patterns making high-performance AI inference both more accessible and more predictable. This comprehensive guide analyzes the latest GPU options, provides detailed performance benchmarks, and offers practical recommendations for different budgets and use cases.
TL;DR: Key Findings and Quick Recommendations
Top Performers: The NVIDIA RTX 5090 emerges as the new consumer champion for LLM inference, delivering up to 213 tokens/second on 8B models with its 32GB VRAM capacity. Understanding VRAM usage patterns, where memory splits between fixed model costs and variable context costs, is crucial for optimal performance.
Best Value: Intel Arc B580 ($249) for experimentation, RTX 4060 Ti 16GB ($499) for serious development, RTX 3090 ($800-900 used) for 24GB capacity, RTX 5090 ($1999) for cutting-edge performance.
Key Insight: VRAM usage follows a predictable pattern: Base model memory + linear context memory growth. The KV cache, not model size, becomes the limiting factor for long contexts.
Understanding LLM Hardware Requirements in 2025
Running large language models (LLMs) locally requires careful consideration of GPU memory (VRAM), memory bandwidth, and computational power. The fundamental challenge is that VRAM usage during inference consists of two distinct components:
Fixed Cost (Constant): Model weights, CUDA overhead, and system buffers
Variable Cost (Linear): KV cache that grows with context length
The Real VRAM Formula
VRAM usage follows this precise formula:
VRAM [GB] = (P × b_w) + (0.55 + 0.08 × P) + (B × N × 2 × L × (d / g) × b_kv) / 10^9
Where:
P = Parameters in billions
b_w = Bytes per weight (Q4_K_M ≈ 0.57 bytes)
0.55 = CUDA/system overhead (GB)
0.08 × P = Scratchpad activations (GB)
B = Batch size (number of concurrent requests)
N = Context length (tokens)
L = Transformer layers
d = Hidden dimension
g = GQA grouping factor (n_head / n_kv_head, e.g., 32 ÷ 8 = 4)
b_kv = Bytes per KV scalar (2 for FP16)
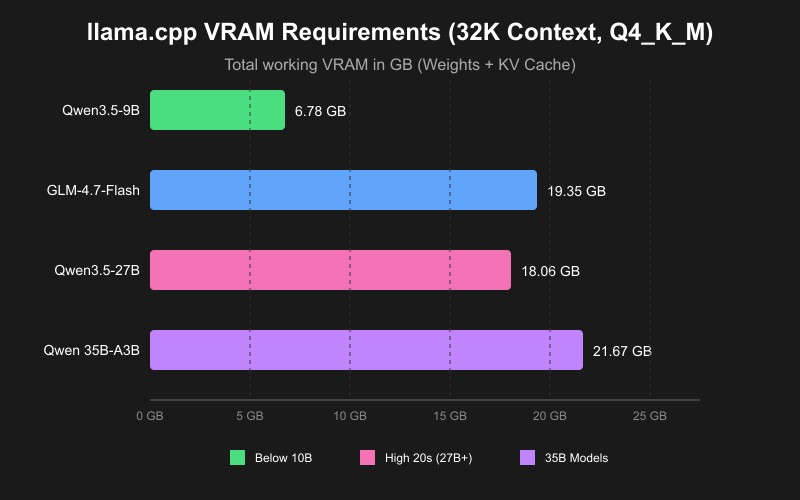
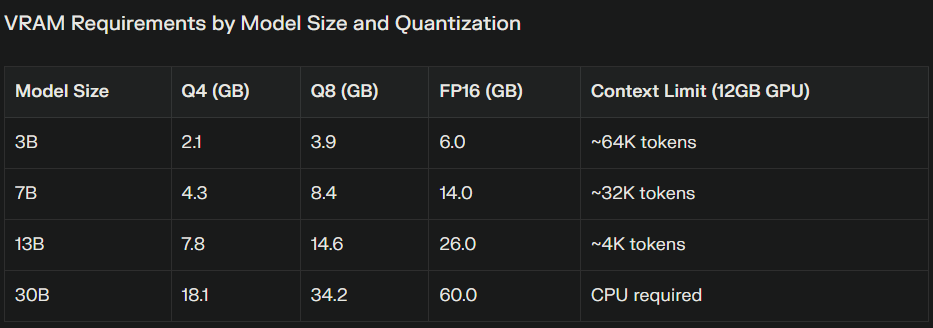
2025 VRAM Requirements by Model Size and Quantization: Complete Memory Usage Guide for MoE and Dense Models:
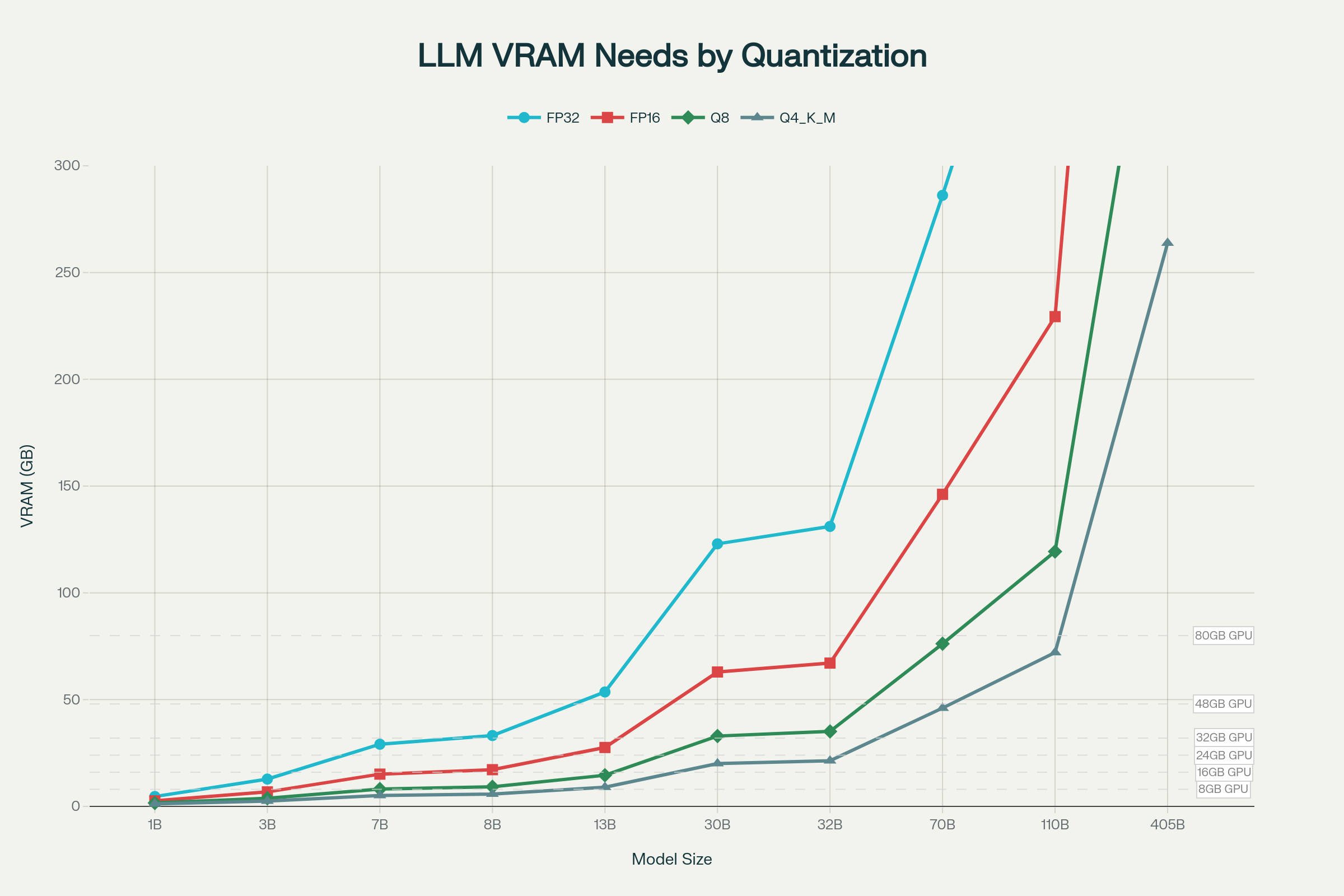
VRAM Requirements Table 2025: GPU Memory Usage for 3B, 7B, and 13B and 30B LLM Models with Various Quantization Levels:
The Context Length Trap
Many users focus on model size while overlooking context length impact. The KV cache grows linearly with every token, both input and output, and can quickly exceed model weight memory usage. For a 7B model, each 1,000 tokens typically consume ~0.11GB additional VRAM.
🧮 Use our VRAM Calculator to see exactly how context length affects your memory requirements and find the optimal balance for your hardware.
Memory Bandwidth and Performance
Memory bandwidth remains critical as model sizes grow. The RTX 5090's GDDR7 memory delivers 1.79TB/s bandwidth compared to the RTX 4090's 1.01TB/s, providing significant advantages for both inference speed and context handling.
Source for this section: Context Kills VRAM: How to Run LLMs on Consumer GPUs
GPU Performance Analysis for LLM Inference
Performance testing across various GPUs reveals clear performance tiers for local LLM inference. The following analysis uses LLaMA 3 8B Q4_K_M quantization as the primary benchmark, representing a common use case that balances model capability with hardware accessibility.
2025 GPU Inference Performance on various GPUs:
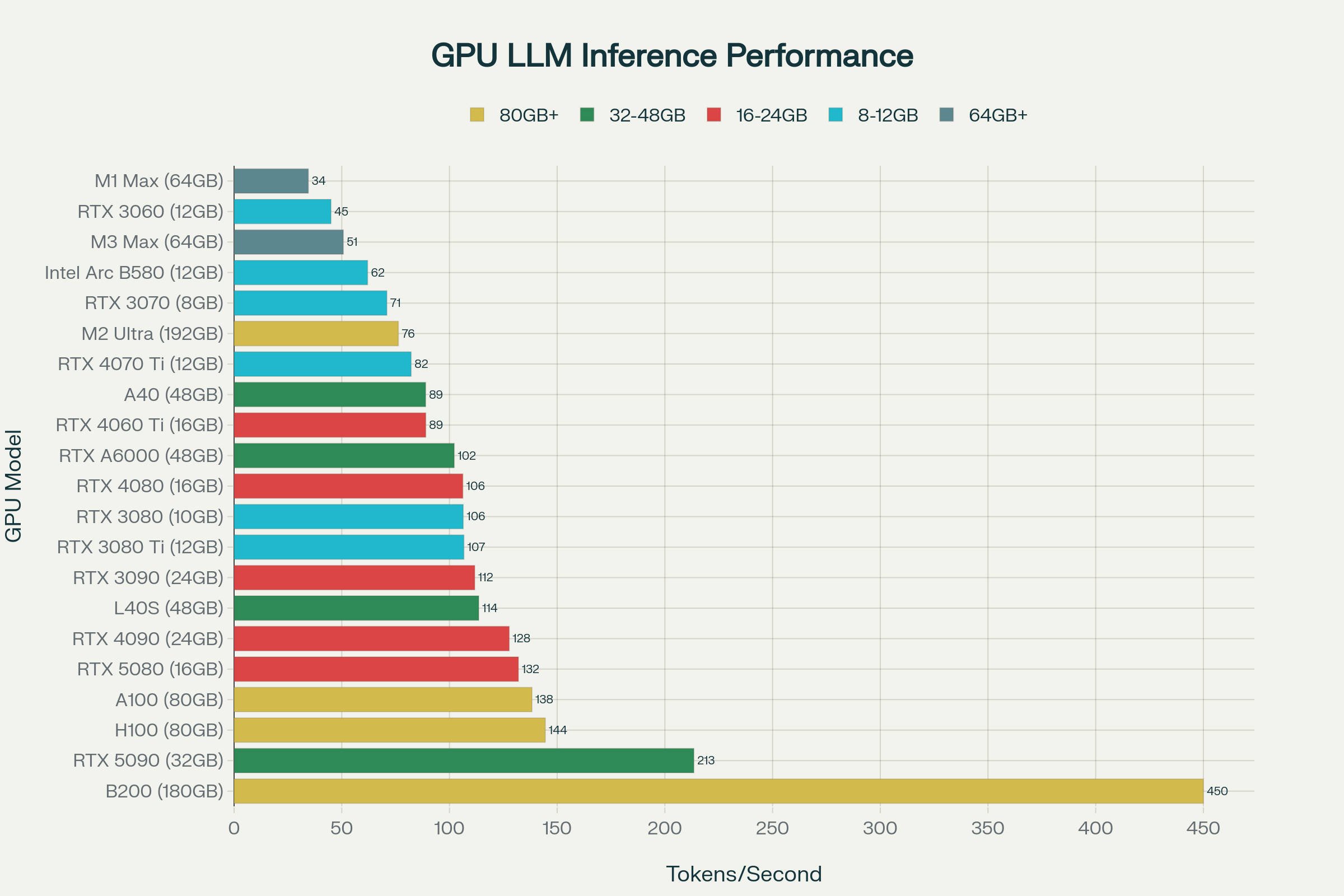
The performance ranking shows several key insights:
Enterprise Tier: The B200 dominates with 450 tokens/second, representing next-generation performance for large-scale deployments. The H100 and A100 provide solid enterprise performance at 144 and 138 tokens/second respectively.
Consumer Flagship: The RTX 5090 leads consumer GPUs with 213 tokens/second, representing a 67% improvement over the RTX 4090. This performance gain comes from both architectural improvements and increased memory bandwidth.
Consumer High-End: The RTX 4090 remains competitive at 128 tokens/second, while the RTX 5080 shows strong performance at 132 tokens/second despite having less VRAM.
Professional Workstations: Cards like the L40S (114 tokens/second) and RTX A6000 (102 tokens/second) offer large VRAM capacities for professional workflows, though at lower performance per dollar than consumer alternatives.
Budget Options: The Intel Arc B580 punches above its weight at 62 tokens/second for just $249, while the RTX 3060 provides entry-level performance at 45 tokens/second.
Popular 2025 MoE models include Qwen3-Coder series, GLM-4.5, and Mixtral variants. These models typically require 15-25% more bandwidth than equivalent dense models due to expert routing overhead, but enable much larger effective model sizes on the same hardware.
The Critical Memory Spill Issue
One of the most significant performance bottlenecks when running LLMs locally is VRAM overflow, when the combined size of model weights and KV cache exceeds GPU memory. Performance can drop dramatically from 50-100 tokens/second to just 2-5 tokens/second when spilling to CPU occurs.
⚠️ Avoid memory spill scenarios by using our Interactive VRAM Calculator to ensure your chosen model and context length fit comfortably within your GPU's memory capacity.
Hybrid GPU+CPU Performance:
Pure CPU: ~4.6 tokens/second
Low GPU usage (spill scenario): ~2.6 tokens/second (worse than CPU!)
High GPU usage: 32+ tokens/second
The lesson: Either fit everything in VRAM or use CPU entirely. Partial GPU utilization often performs worse than pure CPU due to PCIe transfer overhead.
Read more about this here: Context Kills VRAM: How to Run LLMs on Consumer GPUs
Top GPU Recommendations by Category
Consumer Flagship: NVIDIA RTX 5090 (32GB)
The RTX 5090 represents a paradigm shift in consumer GPU capabilities for local LLM inference. Built on the Blackwell architecture, it delivers exceptional performance with its 32GB of GDDR7 memory and 1.79TB/s bandwidth. The increased VRAM capacity enables comfortable handling of large models with extensive contexts.
Benchmark results show the RTX 5090 achieving 213 tokens/second on 8B models and 61 tokens/second on 32B models. At $1999, it offers a price-performance ratio of $9.38 per token/second.
Consumer High-End: NVIDIA RTX 4090 (24GB)
The RTX 4090 remains the most popular choice for serious local LLM deployment, delivering 128 tokens/second on 8B models with its 24GB VRAM capacity. The mature ecosystem, widespread availability, and proven reliability make the RTX 4090 ideal for developers working with various model architectures.
Real-world performance shows excellent stability across different quantization levels and context lengths, making it the reliable choice for production-level local inference.
Budget Champions: RTX 3090 and Intel Arc B580
For budget-conscious users, the RTX 3090 offers exceptional value in the used market at $800-900. Its 24GB VRAM capacity enables running the same large models as the RTX 4090, albeit with slightly lower performance at 112 tokens/second on 8B models.
The Intel Arc B580 deserves special recognition, offering 62 tokens/second at just $249. While limited to 12GB VRAM, it handles 7B models effectively and provides excellent price-performance for experimentation and development.
Price vs Performance Analysis
Understanding the value proposition across different GPU tiers helps optimize purchasing decisions for various use cases and budgets.
2025 GPU Price vs Performance Analysis: Best Value GPUs for Local LLM Inference - Compare RTX 5090 vs Budget Options Like Intel Arc B580
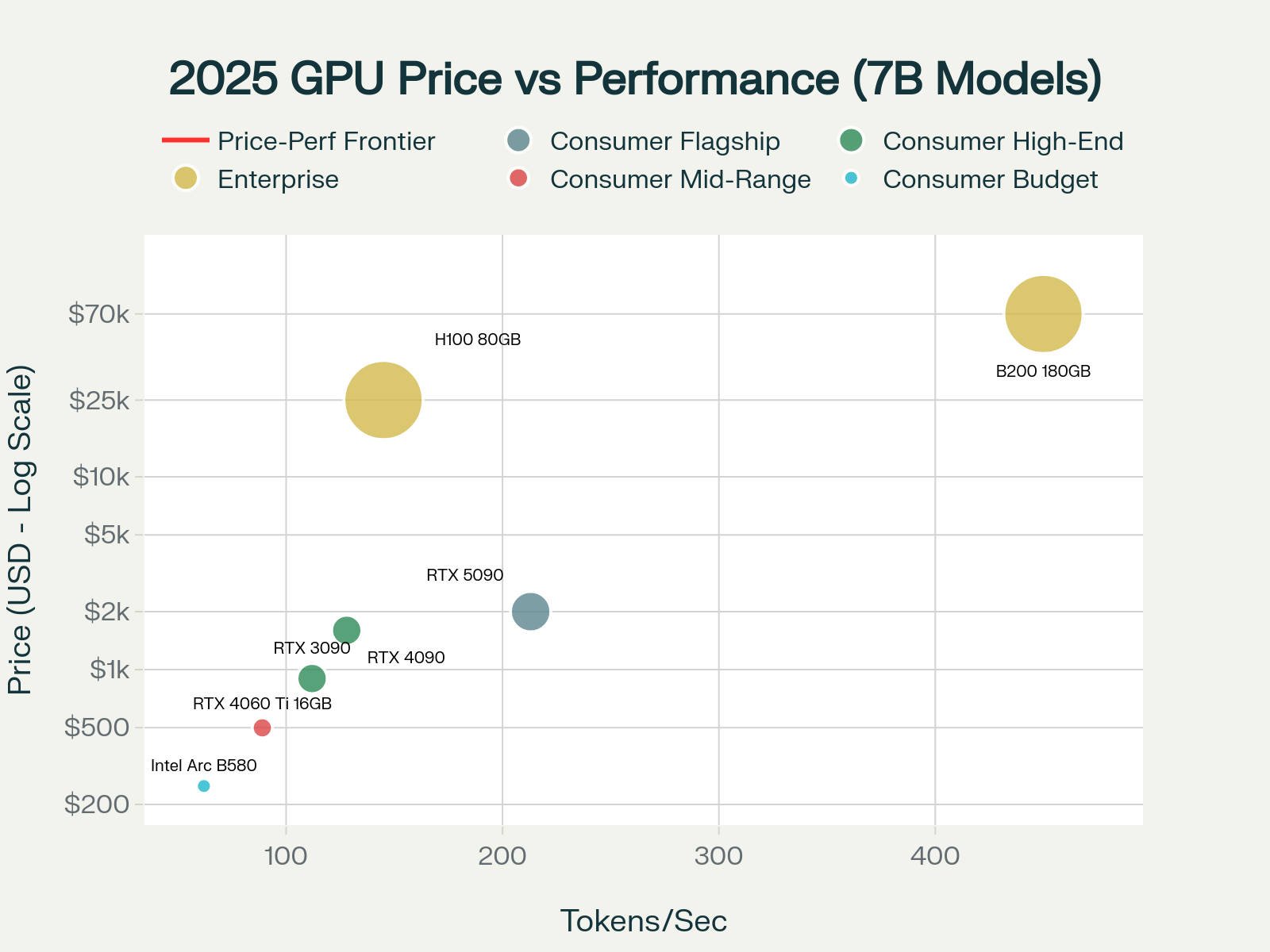
The price-performance analysis reveals several key insights:
Best Value Champions: The Intel Arc B580 and RTX 4060 Ti 16GB offer the best price-performance ratios for their respective capability tiers. The Arc B580's exceptional $4.02 per token/second makes it ideal for experimentation and light production use.
Flagship Performance: The RTX 5090, while expensive, provides reasonable value considering its cutting-edge capabilities and 32GB VRAM capacity. For users requiring maximum model capacity and context length, the premium is justified.
Enterprise Scaling: Enterprise GPUs like the H100 and B200 show their value in multi-user scenarios and maximum-capability deployments, though their high prices limit them to professional and research applications.
Sweet Spot Analysis: The RTX 4090 and RTX 3090 represent different sweet spots, the 4090 for users wanting current-generation performance and warranty coverage, the 3090 for budget-conscious users who prioritize VRAM capacity over absolute performance.
Model-Specific GPU Recommendations
The following image provides specific GPU recommendations for popular 2025 open-weight models, with special attention to MoE architectures and their unique requirements:
📊 For precise VRAM calculations tailored to your specific model, quantization, and context requirements, use our Interactive VRAM Calculator.
Best GPUs for MoE Models 2025: RTX 5090 vs RTX 4090 vs Intel Arc B580 Performance and VRAM Requirements for Qwen3-Coder, GLM-4.5, Mixtral, and More

The MoE Revolution: Changing the Local Inference Landscape
Mixture of Experts (MoE) architectures let model designers scale total parameter counts enormously while only activating a small working set for each token. The result: models with hundreds of billions of parameters that, for many use cases, cost far less per token than an equivalently large dense model.
MoE Model Considerations
When selecting GPUs for MoE models, several factors beyond raw VRAM capacity become important:
Expert Routing Efficiency: Cards with higher memory bandwidth handle expert switching more efficiently. The RTX 5090's GDDR7 provides significant advantages for complex MoE routing patterns.
Framework Optimization: Different inference engines show varying performance with MoE models. vLLM currently provides the best MoE optimization, while Ollama offers easier setup for experimentation.
Batch Size Sensitivity: MoE models often show more dramatic performance improvements with larger batch sizes, making GPUs with more VRAM advantageous even when the base model fits in less memory.
Why MoE matters for local inference
- Huge capacity, smaller per-token compute: Because routing activates only selected experts, MoE models can have much larger total parameter counts without multiplying per-token FLOPs.
- Specialization by design: Different experts can specialize on different domains, token patterns, or modalities, improving accuracy across diverse tasks.
- Scalable cost/performance tradeoffs: You can add experts to raise capacity without linearly growing the per-token compute; but hardware, routing, and engineering complexity increase too.
Common MoE caveats
- Unpredictable memory & data movement: Routing causes dynamic memory access and data movement that complicate batching, caching, and latency.
- Hot-experts & load balancing: Naïve routers can overuse some experts, creating runtime bottlenecks unless the routing or expert regularization is tuned.
- Tooling variability: Not all inference engines and quantization/offload stacks support MoE efficiently, performance varies widely between frameworks.
Popular MoE models in 2025 include Qwen3-Coder series, GLM-4.5, Mixtral-8x22B, and OpenAI's GPT-OSS models. Understanding their active parameter counts is essential for proper GPU selection. For detailed guidance on choosing the right software to run these models, check out our complete guide to Ollama alternatives.
Conclusion
The 2025 GPU landscape for local LLM inference offers compelling options across all price points and use cases. Understanding the fundamental VRAM formula, fixed model costs plus linear context costs, is crucial for making informed hardware decisions.
The RTX 5090 establishes new performance benchmarks with its 32GB capacity, while budget options like the Intel Arc B580 democratize access to local AI. Success in local LLM deployment requires matching hardware capabilities to specific model architectures and use cases, with careful attention to the critical balance between model size and context length.
Whether running coding assistants, reasoning models, or general-purpose chat systems, 2025 offers unprecedented opportunities for local AI deployment across all hardware budgets and requirements.
Frequently Asked Questions
What GPU do I need to run 8B models like Llama 3.1-8B locally?
For 8B models with Q4 quantization, you need at least 8GB VRAM. The Intel Arc B580 (12GB, $249) offers excellent value at 62 tokens/second, while the RTX 4060 Ti 16GB ($499) provides better performance at 89 tokens/second. For flagship performance, the RTX 5090 delivers 213 tokens/second.
Can I run 32B models on consumer GPUs in 2025?
Yes, 32B models require approximately 19-20GB VRAM with Q4 quantization. The RTX 4090 (24GB) and RTX 5090 (32GB) can handle these models comfortably. The RTX 3090 (24GB) also works well and offers excellent value in the used market at $800-900.
Which GPU offers the best value for local LLM inference?
The Intel Arc B580 provides exceptional value at $4.02 per token/second for just $249, making it ideal for 8B models and smaller MoE architectures. For higher performance needs, the RTX 4060 Ti 16GB offers $5.61 per token/second, while the used RTX 3090 provides 24GB VRAM for around $900.
Do I need enterprise GPUs like H100 for local LLM deployment?
Enterprise GPUs are only necessary for the largest models (70B+ dense models) or high-throughput production deployments. Consumer GPUs like RTX 5090 can handle most use cases, including large MoE models. The H100 is primarily beneficial for serving multiple users simultaneously or running 70B+ models.
How does context length affect VRAM usage?
Context length has a linear impact on VRAM through the KV cache. Each 1,000 tokens typically consume ~0.11GB additional VRAM for a 7B model. This means you can run either large models or long contexts, but rarely both on consumer hardware. Use our Interactive VRAM Calculator to see the exact impact for your specific model and context requirements.
What happens when I exceed my VRAM limit?
When model weights plus KV cache exceed VRAM, performance drops dramatically from 50-100 tokens/second to just 2-5 tokens/second due to CPU spill. It's better to use a smaller model that fits entirely in VRAM than a larger model that spills to CPU. Check your memory requirements with our VRAM Calculator to avoid this performance cliff.
Sources
Primary Data Sources
GPU-Benchmarks-on-LLM-Inference Repository
URL
This GitHub repository provided the foundational benchmark data for LLaMA 3 8B Q4_K_M performance across multiple GPU models including RTX 3070, 3080, 3090, 4090, and professional cards. The repository contains comprehensive testing results with standardized methodologies, making it the most reliable source for cross-GPU performance comparisons used in the analysis.RTX 5090 LLM Benchmarks - RunPod
URL
This source provided crucial performance data for the RTX 5090, including detailed benchmarks showing 213 tokens/second performance on 8B models and comprehensive comparisons with previous generation cards. The article includes real-world testing scenarios and quantization performance analysis that informed the RTX 5090 recommendations in the guide.