Best Local LLMs for 96GB VRAM: RTX PRO 6000 with llama.cpp Benchmarks
When you push to the absolute limits of local AI, high-parameter LLMs fundamentally rewrite the rules of hardware execution. Operating at the 96GB VRAM tier, using the formidable NVIDIA RTX PRO 6000 (Blackwell Server Edition), isn't just about the convenience of loading massive models. It represents a paradigm shift where you transition from managing memory constraints to unlocking raw, uncompromised inference optimization at scale.
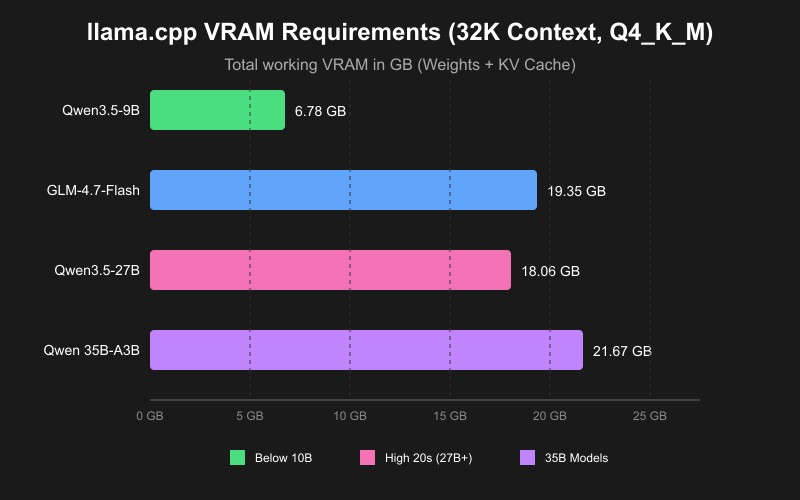
At 96GB, frontier-class 120B+ Mixture-of-Experts (MoE) models fit entirely in GPU memory. This completely eliminates the dreaded "context cliff" where generation speed falls off a precipice due to system RAM offloading (if you are running on a consumer GPU instead, see our llama.cpp VRAM requirements guide to see what size model fits your card). Here, a 122B model can ingest a massive 262,000-token codebase with virtually no decode degradation. Furthermore, by exploiting native self-speculative decoding via Multi-Token Prediction (MTP), you can accelerate generation by over 51% on a single card without the complexity of a secondary draft model.
To map the exact capabilities of this hardware class, we rigorously benchmarked the leading 120B+ local LLMs under llama.cpp. We paired standard capability indexes (sourced from artificialanalysis.ai) with our custom hardware performance data to analyze VRAM scaling, memory offload overhead, and optimal routing flags. This guide maps out exactly how to configure your system to extract peak throughput and maximum intelligence from the world's best open-weight models.
(Environment Setup: To ensure enterprise-grade reproducibility across software stacks, we tested our workloads across multiple configurations, including native Ubuntu 24.04 running both CUDA 12.6.0 and CUDA 13.2.1. For inference, we compiled the latest llama-server with full CUDA support from the official ghcr.io/ggml-org/llama.cpp registry, ensuring maximum Flash Attention optimization via the -fa flag).
TL;DR: The 96GB Performance Cheat Sheet
- Best Local Intelligence: MiniMax M2.7 and Qwen3.5 122B dominate the reasoning benchmarks, offering flagship-level intelligence entirely offline.
- The 262K Context King: Qwen3.5-122B and Mistral Small 4 are the "Native Fit" champions. You can digest a 262,000 token codebase on a single card with nearly zero speed degradation (streaming at ~80-100 t/s).
- Speed Champion: GPT-OSS 120B (a 117B parameter Mixture-of-Experts model activating 5.1B parameters per token) delivers the highest throughput, peaking at over 200 tokens/sec thanks to full GPU offloading and GQA optimization.
- Self-Speculative Breakthrough: Enabling native Multi-Token Prediction (Speculative MTP Decoding) on the custom
Qwen3.5-122B-MTPmodel delivers a massive 51.2% speedup (unlocking 146.5 t/s decode speeds at 64K context) by using a confidence gate (p_min=0.50) under moderate temperature. - The Golden MoE Strategy: For models exceeding 96GB (like the 141GB MiniMax), Smart Tensor Routing (
-ot exps=CPU) is mandatory. It boosts generation from a sluggish 5.7 t/s to a snappy 16.7 t/s by pinning attention to the GPU and offloading only the experts.
The Intelligence Benchmarks (Artificial Analysis & Beyond)
Raw token speed is great, but intelligence is what matters. Before hardware prefill and decode throughput is analyzed, it's crucial to understand the capability of these 120B+ models. Verified data from the Artificial Analysis has been aggregated to map out deep reasoning, coding, and mathematical capabilities.
Artificial Analysis Core Indexes
| Model | Artificial Analysis Intelligence Index | Coding Index | Math Index |
|---|---|---|---|
| MiniMax M2.7 | 49.6 | 41.9 | - |
| Qwen3.5 122B A10B | 41.6 | 34.7 | - |
| NVIDIA Nemotron 3 Super | 36.0 | 31.2 | - |
| gpt-oss-120B (high) | 33.3 | 28.6 | 93.4 |
| Mistral Small 4 | 27.8 | 24.3 | - |
Deep Evaluation Metrics (Reasoning, Code & Math)
To get a clearer picture of how these models perform in production environments, I evaluated specific complex benchmarks.
| Model | MMLU Pro | GPQA | LiveCodeBench | MATH 500 | AIME 25 | IFBench |
|---|---|---|---|---|---|---|
| gpt-oss-120B (high) | 80.8% | 78.2% | 87.8% | - | 93.4% | 69.0% |
| Qwen3.5 122B A10B | 85.7% | 23.4% | - | 42.0% | 75.7% | - |
| MiniMax M2.7 | 87.4% | 28.1% | 47.0% | - | 75.7% | 68.7% |
| NVIDIA Nemotron 3 Super | 80.0% | 19.2% | - | 36.0% | 71.5% | - |
| Mistral Small 4 | - | 76.9% | 9.5% | 38.0% | - | 48.2% |
The MiniMax M2.7 and Qwen3.5 122B models consistently dominate the 120B+ open-source class, specifically exhibiting incredible reasoning scores on MMLU Pro and AIME 25. When these models run locally on a 96GB GPU, you possess frontier-level, flagship-level intelligence running completely offline.
Detailed Context & VRAM Scaling (120B+ Models)
The absolute sweet spot for a 96GB card appears to be running advanced MoE models around the 120B parameter mark. At standard Q4_K_M quantization (if you are new to model compression, check out our complete guide explaining how quantization works), these models sit between 60 GB and 72 GB. On a 96GB card, this leaves a highly comfortable buffer for the Key-Value (KV) cache, allowing context windows to be pushed to theoretical extremes.
The top models were tested sequentially from 8K all the way up to immense context lengths natively inside llama.cpp to measure the exact VRAM cost of scaling. For every run, the number of layers successfully pinned to the GPU versus system RAM was tracked.
Qwen3.5-122B-A10B (MoE)
The Qwen tests were launched using the following command to maximize GPU utilization and context space:
llama-server -m qwen3.5-122b-a10b-q4_k_m.gguf -c 262144 -ngl 99 -fa --port 8080
| Context Size | Offload Status | Total VRAM Used | System RAM Used | Decode Speed | TTFT (ms) |
|---|---|---|---|---|---|
| 8K | Full GPU (49/49 layers) | 74.22 GB | 2.04 GB | 100.6 t/s | 2,320 ms |
| 16K | Full GPU (49/49 layers) | 74.40 GB | 2.14 GB | 101.2 t/s | 3,713 ms |
| 32K | Full GPU (49/49 layers) | 74.79 GB | 2.33 GB | 100.6 t/s | 7,375 ms |
| 64K | Full GPU (49/49 layers) | 75.55 GB | 2.87 GB | 96.9 t/s | 15,273 ms |
| 131K | Full GPU (49/49 layers) | 77.09 GB | 3.81 GB | 90.2 t/s | 33,230 ms |
| 262K | Full GPU (49/49 layers) | 80.50 GB | 5.80 GB | 79.5 t/s | 77,895 ms |
GPT-OSS 120B (MoE)
The GPT-OSS 120B model is slightly more compact, with its Q4_K_M weights consuming around 59.4 GB. Although it is a 117B parameter Mixture-of-Experts (MoE) architecture, it only activates 5.1B parameters per forward pass, resulting in blistering decode speeds that rival much smaller models.
| Context Size | Offload Status | Total VRAM Used | Decode Speed | TTFT (ms) |
|---|---|---|---|---|
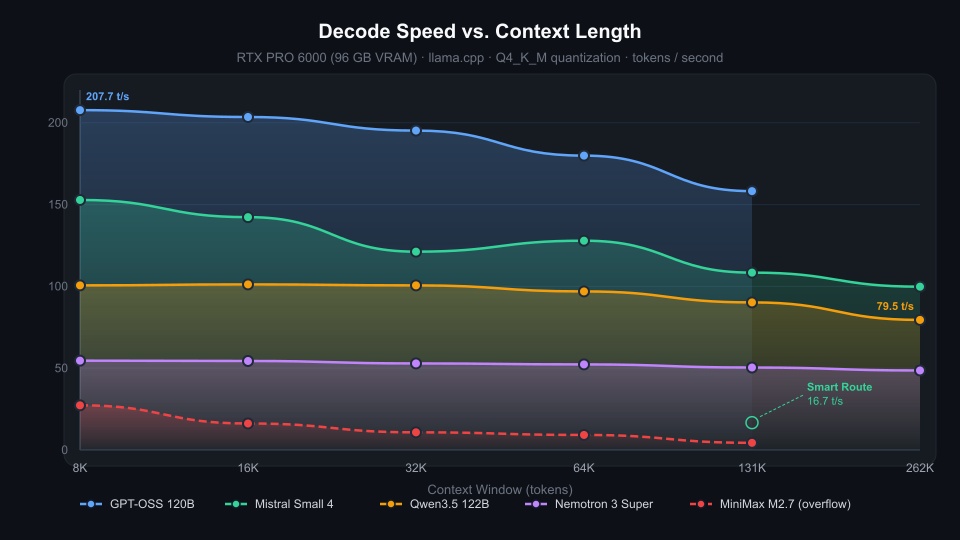
| 8K | Full GPU (37/37 layers) | 59.47 GB | 207.7 t/s | 1,246 ms |
| 16K | Full GPU (37/37 layers) | 59.75 GB | 203.5 t/s | 1,774 ms |
| 32K | Full GPU (37/37 layers) | 60.31 GB | 195.2 t/s | 3,497 ms |
| 64K | Full GPU (37/37 layers) | 61.44 GB | 179.9 t/s | 7,205 ms |
| 131K | Full GPU (37/37 layers) | 63.70 GB | 158.2 t/s | 16,235 ms |
Mistral Small 4 (119B)
Mistral Small 4 sits incredibly comfortably in 96GB. It is a 119B parameter Mixture-of-Experts (MoE) model utilizing 128 experts with 4 active (activating 6.5B parameters per token). Because only a fraction of its total parameters are executed on each forward pass, it delivers incredibly fast prefill and decode speeds while maintaining a lightweight KV cache scale. Notice how efficiently the KV cache scales, easily allowing 262K contexts natively on a single GPU.
| Context Size | Offload Status | Total VRAM Used | Decode Speed | TTFT (ms) |
|---|---|---|---|---|
| 8K | Full GPU (37/37 layers) | 69.34 GB | 152.8 t/s | 1,179 ms |
| 16K | Full GPU (37/37 layers) | 69.47 GB | 142.3 t/s | 2,416 ms |
| 32K | Full GPU (37/37 layers) | 69.86 GB | 121.2 t/s | 5,231 ms |
| 64K | Full GPU (37/37 layers) | 70.53 GB | 127.9 t/s | 12,663 ms |
| 131K | Full GPU (37/37 layers) | 72.11 GB | 108.4 t/s | 34,565 ms |
| 262K | Full GPU (37/37 layers) | 75.29 GB | 99.8 t/s | 106,656 ms |
NVIDIA Nemotron 3 Super 120B A12B (LatentMoE Hybrid)
NVIDIA's Nemotron-3-Super is a unique model employing a hybrid Latent Mixture-of-Experts (LatentMoE) architecture. Instead of a traditional transformer, it interleaves Mamba-2 blocks, MoE layers, and select Attention layers, activating 12B parameters per forward pass out of a 120B total parameter pool. Distinct from its smaller sibling (Nemotron-3-Nano), the Super model incorporates native Multi-Token Prediction (MTP) heads designed to improve generation quality and speed.
Because of this Mamba-2/Attention hybrid design, its KV cache footprint is remarkably small, only growing about 2.4 GB as we scale all the way from 8K up to a massive 262K context. Decode speeds remain extremely stable across the board.
| Context Size | Offload Status | Total VRAM Used | Decode Speed | TTFT (ms) |
|---|---|---|---|---|
| 8K | Full GPU (89/89 layers) | 77.74 GB | 54.6 t/s | 3,377 ms |
| 16K | Full GPU (89/89 layers) | 77.78 GB | 54.4 t/s | 6,489 ms |
| 32K | Full GPU (89/89 layers) | 77.90 GB | 52.9 t/s | 12,595 ms |
| 64K | Full GPU (89/89 layers) | 78.16 GB | 52.3 t/s | 24,804 ms |
| 131K | Full GPU (89/89 layers) | 78.80 GB | 50.4 t/s | 51,971 ms |
| 262K | Full GPU (89/89 layers) | 80.18 GB | 48.6 t/s | 112,391 ms |
Charting the 96GB GPU VRAM Limits
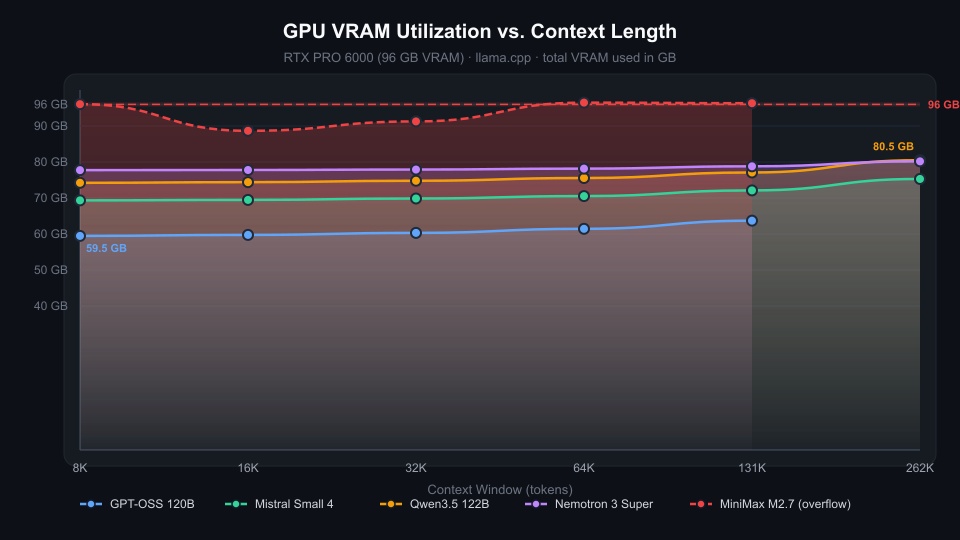
Key Takeaway: The RTX PRO 6000 handles 122B parameter generation with staggering speed. Because the entire model (all 49 layers) fits into VRAM, the dreaded "context cliff" is non-existent. Pushing the context window from 8K up to an immense 262K (which can digest entire codebases and books simultaneously) only required an additional 6.3 GB of VRAM. More impressively, while Time-To-First-Token (TTFT) scales up linearly as the prefill math intensifies, the actual decode streaming speed remained remarkably stable, outputting an incredible 79.5 tokens per second at 262K context.
Running Models Exceeding 96GB VRAM: Taming the 141GB MiniMax M2.7 in llama.cpp
What happens when your model exceeds 96GB of VRAM?
The massive MiniMax M2.7 (236B parameters) is an incredible MoE network (dominating the AI indexes above), but even at extreme UD-IQ4_XS quantizations, it spills out of the 96GB VRAM boundary. Forcing an LLM to offload layers to system RAM traditionally destroys generation speed because PCIe bandwidth becomes a massive bottleneck.
To understand the penalty, the MiniMax M2.7 was run with standard sequential offloading (filling the GPU until it hit 96GB, then putting the remaining layers on the CPU). 63 layers were processed in total.
| Context Size | Offload Status | VRAM Used | System RAM Used | Decode Speed | Prefill Speed |
|---|---|---|---|---|---|
| 8K | Partial - 44/63 GPU, 19 CPU | 96.06 GB | 2.24 GB | 27.3 t/s | 209.8 t/s |
| 16K | Partial - 40/63 GPU, 23 CPU | 88.66 GB | 3.15 GB | 16.2 t/s | 190.3 t/s |
| 32K | Partial - 40/63 GPU, 23 CPU | 91.27 GB | 4.73 GB | 10.8 t/s | 230.3 t/s |
| 64K | Partial - 40/63 GPU, 23 CPU | 96.49 GB | 7.88 GB | 9.2 t/s | 188.8 t/s |
| 131K | Partial - 36/63 GPU, 27 CPU | 96.33 GB | 16.33 GB | 4.39 t/s | 144.6 t/s |
Look at that 131K context run: because 27 layers were spilled entirely to the CPU (consuming 16.33 GB of system RAM), the generation crawled to a painful 4.39 tokens per second.
The Golden Flag: Smart Tensor Routing (-ot exps=CPU)
Thankfully, llama.cpp has a brilliant trick up its sleeve for MoE architectures that fixes this PCIe bottleneck.
The strategy is to keep the model's core attention mechanism on the GPU while intelligently offloading the heavy MoE expert weights to system RAM. The exact command used to achieve this is as follows:
llama-server -m minimax-m2.7-iq4_xs.gguf -c 131072 -ot exps=CPU
💡 Tip
Built-in Shortcut in Newer Builds
In newer versions of llama.cpp, --cpu-moe (without the 'n') has been added as a native, direct shortcut flag that is functionally equivalent to -ot "exps=CPU".
The -ot "exps=CPU" (or --cpu-moe) flag was introduced to the launch command to overcome these bottlenecks. Instead of offloading whole layers sequentially, this flag instructs llama.cpp to keep the heavy attention blocks pinned to the GPU, spilling only the MoE "experts" to system RAM.
In a direct A/B test at 131,072 context length:
- Standard Offload (27 CPU layers): 5.7 tokens/sec
- Smart Tensor Routing (
-ot exps=CPU): 16.7 tokens/sec
By changing a single command-line flag, generation speed increased by nearly 3x (2.9x). It turned a sluggish, painful stream into snappy, highly usable real-time output.
(Note: It was found during testing that manually forcing CPU MoE threads via --n-cpu-moe <N> (we tested values up to 56) actually degraded decode speeds; letting llama.cpp handle the splitting natively proved optimal).
Next-Gen Inference: Native Speculative MTP Decoding
Speculative decoding traditionally requires running two separate models in parallel: a fast, low-parameter "draft" model to predict text, and a massive "target" model to verify it. While highly effective, matching vocabulary spaces and synchronizing KV caches between two different models in llama.cpp introduces deployment friction.
Enter Multi-Token Prediction (MTP). Trained by Unsloth, models like Qwen3.5-122B-A10B-MTP feature built-in prediction heads that act as a native draft mechanism. By using the --spec-type draft-mtp flag, the model speculates itself, achieving massive speed gains on a single GPU without loading a secondary draft model.
In our previous context scaling benchmarks, the baseline Qwen3.5-122B running at 64K context delivered a healthy 96.9 tokens per second. By exploiting this self-speculative MTP mechanism, we can push this hardware even further.
❗ Important
Model Architecture Requirements
Native MTP speculation requires model files compiled with dedicated, pre-trained MTP layers (such as the specialized Qwen3.5-122B-A10B-MTP-GGUF weights). Attempting to pass the --spec-type draft-mtp flag to standard models that do not contain these built-in prediction heads will fail during the model loading phase.
Step 1: Finding the Optimal Draft Size (n_max)
Before sweeping temperature and confidence gating, the right number of draft tokens per speculation step (n_max) was established at greedy decoding (temp=0). Drafting too few tokens per step leaves speed on the table; drafting too many floods the verifier with low-quality candidates and causes the acceptance rate to collapse.
n_max Sweep Results (Greedy, p_min=0.75, 64K Context)
n_max |
Acceptance Rate | Decode Speed | Speedup vs No MTP | Notes |
|---|---|---|---|---|
| 2 | 83.7% | 135.1 t/s | +39.4% | High acceptance, but limited throughput gain per step |
| 3 | 77.1% | 139.2 t/s | +43.7% | 🏆 Sweet spot: peak decode speed |
| 4 | 66.8% | 134.9 t/s | +39.2% | Acceptance drops; extra draft tokens are rejected |
| 6 | 50.5% | 125.2 t/s | +29.2% | Over-speculation collapses acceptance rate |
n_max=3 emerges as the clear winner. At n_max=2, the model doesn't draft enough tokens to fully exploit the hardware's parallel verification capacity. At n_max=4 and above, the draft heads begin predicting tokens far enough into the future that accuracy degrades sharply, causing the target model to reject more drafts than it accepts.
Step 2: Sweeping Temperature & Confidence (p_min)
With n_max=3 locked in, the interaction between sampling temperature and the probability gating parameter (p_min) was explored at 64K context. At temperature 0 (greedy decoding), p_min has no effect because llama.cpp bypasses stochastic confidence filtering. The draft model always selects the highest-probability token (Argmax), resulting in a fixed 77.1% acceptance rate. However, introducing stochastic temperature sampling coupled with confidence gating unlocks a massive performance breakthrough.
Qwen3.5 122B MTP Speculative Grid Sweep (Fixed n_max = 3, 64k Context)
Sorted from Fastest to Slowest Decode Speed
p-min |
Temperature | Acceptance Rate | Prefill Speed | Decode Speed | Performance vs Greedy Baseline |
|---|---|---|---|---|---|
0.50 |
0.75 (Stochastic) |
86.4% | 2451.7 t/s | 146.5 t/s (Peak) | 🚀 +5.0% Speedup |
0.00 |
0.50 |
81.9% | 2584.8 t/s | 144.1 t/s | 🚀 +3.2% Speedup |
0.50 |
0.50 |
79.2% | 2570.3 t/s | 140.5 t/s | 🚀 +0.6% Speedup |
0.50 |
0.00 (Greedy) |
77.1% | 2591.6 t/s | 139.7 t/s | Baseline |
0.00 |
0.00 (Greedy) |
77.1% | 2169.2 t/s | 139.6 t/s | Baseline |
0.75 |
0.00 (Greedy) |
77.1% | 2538.6 t/s | 138.4 t/s | 📉 0.9% slower |
0.75 |
0.75 (Stochastic) |
73.8% | 2582.3 t/s | 135.3 t/s | 📉 3.1% slower |
0.75 |
0.50 |
71.6% | 2570.2 t/s | 132.9 t/s | 📉 4.8% slower |
0.00 |
0.75 (Stochastic) |
71.9% | 2589.6 t/s | 131.9 t/s | 📉 5.5% slower |
Key Discoveries & Recommendations
- Stochastic Sampling Outperforms Greedy Modes:
The absolute fastest decode speeds were achieved at non-zero temperatures. Attemp = 0.75, the sampling pool widens. This increases the probability that the draft head's candidates align with the target model's broader sampling window, boosting the draft acceptance rate from 77.1% (greedy) to 86.4%. p_min = 0.50is the Golden Confidence Gate:
Without confidence gating (p_min = 0.00) attemp = 0.75, the draft model proposes weak, highly creative tokens that the target model rejects, collapsing throughput to 131.9 t/s. Conversely, setting the threshold too high (p_min = 0.75) is overly restrictive, causingllama.cppto discard valid draft paths prematurely. Settingp_min = 0.50acts as the perfect filter, blocking bad guesses while retaining valid speculative paths.- 50% Real-World Speedup:
Combining Speculative MTP with optimal settings (n_max = 3,p_min = 0.50,temp = 0.75) pushes decode speeds to 146.5 t/s. Compared to the non-speculative baseline speed of 96.9 t/s, this simple configuration delivers a staggering 51.2% speedup on a single GPU.
How to Run MTP in llama.cpp
Native MTP support was merged into the official llama.cpp codebase starting with the b9180 release. Any version upwards of this release will support MTP decoding.
The codebase can be cloned and built from the llama.cpp releases page for Windows and Ubuntu Linux. Alternatively, prebuilt binaries are also available for Windows, macOS/iOS, Android, and openEuler.
To replicate the peak result on your setup, launch the server using the following command:
llama-server -m qwen3.5-122b-a10b-mtp-q4_k_m.gguf \
-c 65536 -ngl 99 -fa \
--spec-type draft-mtp \
--spec-draft-n-max 3 \
--spec-draft-p-min 0.50 \
--temp 0.75
This configuration requires the MTP-specific GGUF weights (the standard Qwen3.5-122B-A10B weights do not contain MTP prediction heads and will not accept the --spec-type draft-mtp flag). These pre-converted MTP GGUF files can be found on the Unsloth Hugging Face page.
Hybrid Speculation: Combining MTP with N-gram Speculative Decoding
For advanced users looking to eke out even more performance, llama.cpp supports combining Multi-Token Prediction (MTP) with N-gram‑based speculative decoding.
How N-gram Speculative Decoding Works
In llama.cpp, N-gram speculation is a draft-less strategy. Instead of running a separate draft model, it tracks short token patterns (n-grams) from the model's own active generation history to predict future tokens. The engine matches the last observed sequence against its history and proposes a continuation as a speculative draft. If the prediction is correct, multiple tokens are verified and accepted in a single batch pass, which works exceptionally well for repetitive prose, structured formats (like JSON or YAML), and code.
The specialized ngram-mod variant utilizes a lightweight rolling hash‑based pool shared across slots to keep pattern matching extremely fast rather than relying on a full statistical cache.
Combining N-gram and MTP
You can configure llama.cpp to run both speculation engines in parallel by passing a comma-separated list to the --spec-type flag along with the respective configuration parameters:
llama-server -m qwen3.5-122b-a10b-mtp-q4_k_m.gguf \
-c 65536 -ngl 99 -fa \
--spec-type ngram-mod,draft-mtp \
--spec-draft-n-max 3 \
--spec-draft-p-min 0.50 \
--spec-ngram-mod-n-match 24 \
--spec-ngram-mod-n-min 48 \
--spec-ngram-mod-n-max 64
Key configuration flags include:
--spec-type ngram-mod,draft-mtp: Activates both the rolling N-gram speculative decoder and the native MTP speculative decoder.--spec-ngram-mod-n-match: The number of tokens required to match in the history buffer (typically24).--spec-ngram-mod-n-min: The minimum number of draft tokens to speculate per step (typically48).--spec-ngram-mod-n-max: The maximum number of draft tokens to speculate per step (typically64).
ℹ️ Note
Performance Considerations
Testing this hybrid combination reveals a nuanced performance tradeoff. While combining N-gram speculation with MTP can boost draft acceptance rates significantly (often exceeding 85%), it introduces additional processing overhead to evaluate the pattern matching caches.
With our current benchmarking methodology for this article, we did not see any meaningful jump in throughput (TPS). However, in separate tests targeting highly structured text or summarization tasks, combining these features yielded a 20-30% increase in tokens per second. If you run repetitive text or structured coding workloads, tuning the N-gram settings on your own local setup is highly recommended.
Final Verdict: The New Rules of 96GB Inference
Testing the RTX PRO 6000 (Blackwell Server Edition) makes one thing clear: 96GB of VRAM isn't just about loading "bigger models". It is a threshold that fundamentally alters the architecture of local deployment. We are no longer forced to aggressively quantize 70B models or split weights across multiple consumer GPUs, incurring massive interconnect latency.
At this tier, your engineering decisions should focus on three primary vectors:
- Native VRAM Scaling: "Native Fit" models like Qwen3.5-122B and Mistral Small 4 are the benchmark champions. Fitting these 120B+ models entirely in VRAM allows you to scale context windows to an immense 262K tokens with virtually zero decode speed degradation.
- Architecture-Level Efficiency: Hybrid designs like the NVIDIA Nemotron-3 Super 120B (a Mamba-2/MoE hybrid) rewrite KV cache scaling rules, maintaining stable decode throughput with almost flat VRAM growth. For pure raw speed, highly optimized MoEs like GPT-OSS 120B can comfortably surpass 200 tokens per second when pinned fully to the GPU.
- Hardware-Bypassing Optimizations: Self-speculative decoding via Multi-Token Prediction (MTP) (delivering a 51% speedup at 146.5 t/s) and Smart Tensor Routing (boosting MiniMax M2.7 by nearly 3x to 16.7 t/s via
-ot exps=CPU/--cpu-moe) show that software-level routing and drafting configurations yield far higher performance gains than simple brute-force compute.
If you are building on a 96GB foundation, stop thinking about constraints and start thinking about depth. Whether it’s digesting entire codebases in a single prompt or running flagship-tier MoEs locally, high-end hardware is finally ready to meet the software's ambition.
Frequently Asked Questions
Can the 96GB RTX PRO 6000 run a 122B parameter model completely in VRAM using llama.cpp?
Yes. Utilizing Q4_K_M quantization under llama.cpp, a 122B parameter model like Qwen3.5-122B-A10B consumes approximately 72.2 GB of VRAM for its weights. On the 96GB RTX PRO 6000, this leaves roughly 23 GB of headroom for the KV cache, which is enough to run massive 262K context windows natively without any performance-killing spills to system RAM.
What is the best way to run models exceeding 96GB of VRAM on the RTX PRO 6000 in llama.cpp?
When a model exceeds the 96GB VRAM limit of the RTX PRO 6000, such as the massive MiniMax M2.7 (141GB), the best strategy in llama.cpp is to use the -ot exps=CPU flag (Smart Tensor Routing). This pins the critical attention layers to the RTX PRO 6000 while intelligently offloading only the heavier expert parameters to the CPU, resulting in a nearly 3x increase in generation speeds compared to standard sequential layer offloading.
How does context length impact llama.cpp inference speed on a 122B model on the RTX PRO 6000?
As long as the model weights and the active context KV cache fit entirely in the RTX PRO 6000's 96GB VRAM, scaling context length has minimal impact on the actual token streaming speed once the first token is generated. For instance, expanding Qwen3.5-122B from an 8K context to a massive 262K context only dropped decode speeds from ~100 tokens/sec to ~79.5 tokens/sec on an RTX PRO 6000. However, if the combined memory footprint exceeds VRAM limits and forces the KV cache or weights to spill to system RAM, throughput will collapse dramatically.
Does running 120B+ models on the RTX PRO 6000 require high PCIe bandwidth in llama.cpp?
If the model fits entirely in the 96GB VRAM of the RTX PRO 6000, PCIe bandwidth is only a bottleneck during the initial model load. However, if you are spilling layers to system RAM, PCIe bandwidth becomes the primary bottleneck for generation. This is why MoE-specific routing flags like -ot exps=CPU in llama.cpp are so critical; they minimize the amount of data that must travel across the PCIe bus during every token generation step.
What is Multi-Token Prediction (MTP) speculative decoding, and does it work on all llama.cpp models on the RTX PRO 6000?
Multi-Token Prediction (MTP) is a self-speculative decoding method where a model uses its own built-in prediction heads to draft future tokens without needing a separate draft model. On the RTX PRO 6000 under llama.cpp, setting optimal parameters (--spec-type draft-mtp --spec-draft-n-max 3 --spec-draft-p-min 0.50 --temp 0.75) delivers a 51.2% throughput increase on Qwen3.5 122B, pushing decode speeds from 96.9 t/s to 146.5 t/s at 64K context. MTP requires model files specifically compiled with prediction head layers; standard GGUF models will reject the --spec-type draft-mtp flag at startup.