Best Local LLMs for PDF Chat, Analysis and RAG
A PDF is only as useful as the answers you can extract from it. "PDF RAG" (Retrieval-Augmented Generation applied to PDFs) means: extract and index the document, create embeddings, and let a local model answer queries using retrieved context. Keeping everything local means no sensitive files are uploaded to third-party APIs, a must for contracts, medical notes, IP, and any private corpus.
Beyond privacy, local setups let you optimize for cost and latency, experiment with multiple models and embeddings, and control citation behavior. But you'll only get accurate, useful answers if you treat ingestion and retrieval as first-class steps, we'll cover that below.
TL;DR
If you want a plug-and-play desktop PDF chat: try LM Studio or GPT4All (LocalDocs) and get started within 2 mins.
If you want a self-hosted web UI with strong RAG workflows: Open WebUI or AnythingLLM are excellent.
If you want a no-frills developer starter: PrivateGPT / LocalGPT get you a local PDF chat quickly.
Best practice: Fix PDF extraction first (use unstructured or Docling), pick a lightweight embedding model (nomic / BGE / mxbai variants) and store vectors in a local DB (Qdrant/Chroma/Postgres).
Why local PDF RAG matters (and why it's worth doing right)
Beyond privacy, local setups let you optimize for cost and latency, experiment with multiple models and embeddings, and control citation behavior. But you'll only get accurate, useful answers if you treat ingestion and retrieval as first-class steps, we'll cover that below.
Quick comparison - at a glance
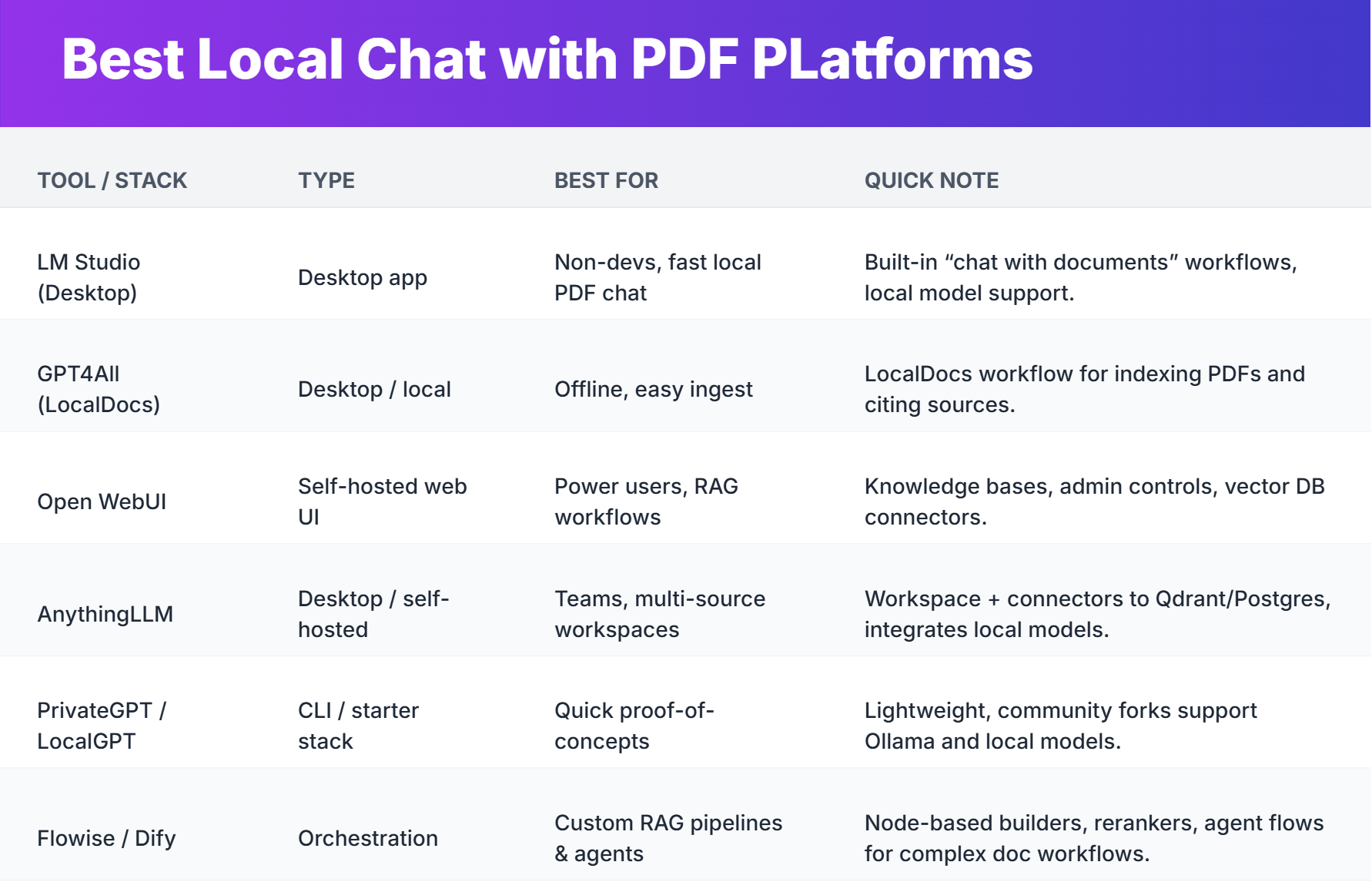
(Each recommendation below includes why I pick it and what to watch out for.)
Best picks
LM Studio - best for non-technical, fast local PDF chat
If you want to drop a PDF into a desktop app and immediately ask questions, without Docker, servers, or fiddly config, LM Studio is one of the cleanest experiences. It supports multiple local models and provides a focused "Chat with Documents" experience that handles ingestion and retrieval in one place. Perfect for researchers, lawyers, and anyone who prefers GUI over terminal.
GPT4All (LocalDocs) - best for offline-first workflows
GPT4All's LocalDocs mode is built for privacy: index your PDFs on the same machine and run everything locally. The workflow provides simple citation handling and is friendly for hobbyists or people running LLMs on a laptop.
Open WebUI - best free web UI with mature RAG UX
Open WebUI brings a full RAG knowledge workflow to self-hosters: knowledge bases, explicit document references, and connectors for local vector stores. If you want a browser UI to manage ingestion, search modes and model routing, Open WebUI is a top choice.
AnythingLLM - best for teams & multi-source workspaces
AnythingLLM focuses on "workspaces" - ingest PDFs, websites and external sources, connect to Qdrant/Postgres, and let teams manage data and models. If you need shared knowledge bases and multi-user flows, this is a solid pick.
PrivateGPT / LocalGPT - best no-friction developer starter
Want a minimal, reproducible stack? PrivateGPT and LocalGPT are community favorites for on-prem document chat. They're lightweight, scriptable, and great for proofs of concept, then you graduate to Open WebUI / Flowise once you need richer UX or pipelines.
How to choose the right local PDF RAG stack (the checklist I use)
With a decade of driving organic traffic and building content tools, I. I always ask the same five questions before picking a stack:
- Privacy needs: Are the PDFs sensitive? If yes → local only (no cloud embedding APIs).
- User skill level: Desktop GUI vs self-hosted server vs developer CLI.
- Scale & concurrency: One machine for personal use or a small server for a team?
- Accuracy budget: Is extraction quality more important than model size? (Hint: extraction often wins.)
- Operational complexity vs control: Do you want a managed UI or full control over retrieval, reranking and prompts?
Match answers to the rows in the quick comparison table above.
Practical setup recipes - three fast paths
Below are concise recipes that get you from zero to a working local PDF chat. These are intentionally pragmatic, adapt paths to your OS and hardware.
1) Desktop fast start - LM Studio (GUI)
- Download & install LM Studio for your OS.
- Open "Chat with Documents" → import PDF(s).
- Choose a local model (8–13B recommended for laptops).
- Configure retrieval: embedding model (on-device), vector DB (local disk).
- Start asking, use the app's citation feature to surface source pages.
Why pick this: zero DevOps, polished UI. Watch out for: large team workflows.
2) Self-hosted web UI - Ollama + Open WebUI (recommended for power users)
- Install Ollama (local model manager) and pull a model:
ollama pull llama-3-8b(example). - Install Open WebUI and point its knowledge connector to a local vector DB (Qdrant/Chroma).
- Ingest PDFs using unstructured or Docling to produce clean text chunks with metadata.
- Configure retrieval: choose an embeddings model (nomic-embed, BGE variants), set top_k = 4–8, chunk size ~300–800 tokens.
- Use the web UI to test queries and tune reranking/hybrid search.
Why pick this: full control, great for teams and customization. Watch out for: initial setup and vector DB config.
3) Developer quick starter - PrivateGPT / LocalGPT
- Clone PrivateGPT or LocalGPT repo (community forks lean on Ollama or llama.cpp).
pip install -r requirements.txt(includes unstructured, faiss/qdrant-client, and an embeddings wrapper).- Run
python ingest.py --pdfs ./docs --db qdrantthenpython chat.pyto start a local chat server. - Iterate: switch embedding model, tune chunking, enable OCR for scans (Tesseract).
Why pick this: fast, reproducible, scriptable. Watch out for: community forks - pick active ones with Ollama support.
PDF ingestion & parsing - the underrated MVP
If you skimp on ingestion, even the best model will hallucinate or miss context. Two reliable OSS tools in 2025:
- unstructured : partitions PDFs into semantic elements (headings, paragraphs, tables) that improve chunk quality.
- Docling (IBM) : focused on layout-aware extraction (useful for scientific papers, invoices, contracts).
Practical rules:
- Extract structure (title, headings, captions, tables) - store as metadata.
- Chunk to 300–1,000 tokens with ~10–20% overlap.
- For scanned PDFs, run Tesseract OCR first or use a vision LLM pipeline (LLaVA family) for diagrams, then index the resulting text.
Embeddings & vector databases - pick the right pair
Embeddings are the glue between documents and answers.
Local embedding models to consider: nomic-embed-text, mxbai-embed-large, BGE-M3, and small Jina models. Many of these are available via local model managers (Ollama, etc.).
Vector DB choices:
- Qdrant : strong, open, and popular for self-hosted RAG workflows.
- Chroma : lightweight and easy to run locally.
- Postgres + pgvector : excellent if you prefer a single relational store for everything.
Practical tip: If you don't have a GPU, choose CPU-friendly embeddings (nomic / MiniLM variants), they're fast and good enough for many corpora.
Models & hardware - what to run locally
Lightweight laptops (CPU or small GPU): 7–13B instruction models, Gemma-2-9B, Llama-3 8B, Mixtral 7B or Qwen 2.5 7B-instruct, are good tradeoffs for latency vs quality.
Servers / higher VRAM: You can run bigger 13–70B models (see our guide to the best GPUs for local LLMs), but often retrieval + a 13B reasoning model is better than huge models for doc Q&A.
Embeddings on CPU: nomic / all-MiniLM / Jina small perform well without GPUs.
Rule of thumb: Improve ingestion and retrieval before upgrading to a larger model, you'll get better ROI.
Retrieval tuning - small knobs that matter
- Chunk size: 300–800 tokens works for most PDFs.
- Top_k: 4–8 retrieved chunks is a good starting point.
- Overlap: 10–20% overlap reduces "split sentence" problems.
- Hybrid search: combine BM25/keyword search with vector search for long technical PDFs; rerank using a cross-encoder if available.
Scanned PDFs & diagrams - extra steps
- Run OCR (Tesseract or commercial engines) to get searchable text.
- For diagrams, flowcharts or images, either summarize them into text descriptions before indexing or use a vision LLM / multimodal model to extract meaning and index the extracted summary.
Security & privacy checklist (do this for sensitive docs)
- Keep embeddings, vectors and models on disk in encrypted volumes where possible.
- Lock down web UIs with authentication and network rules (don't expose to the public internet by default).
- Maintain access logs and rotate keys for any connectors.
- If team access is required, use role separation.
Closing: fast start checklist
- Choose stack: Desktop (LM Studio / GPT4All) or Self-hosted (Ollama + Open WebUI).
- Extract PDFs with unstructured or Docling.
- Create embeddings (nomic / BGE / mxbai) and index into Qdrant/Chroma.
- Tune retrieval: chunk size 300–800 tokens, top_k 4–8, overlap 10–20%.
- Choose a model: 8–13B for laptops, larger if you have heavy compute.
Frequently Asked Questions
What's the best desktop app for PDF chat without technical setup?
LM Studio offers the cleanest experience with built-in "Chat with Documents" workflows that handle ingestion and retrieval automatically. GPT4All's LocalDocs mode is also excellent for offline-first workflows with simple citation handling.
Which self-hosted solution provides the best RAG workflows?
Open WebUI and AnythingLLM are the top choices. Open WebUI offers mature knowledge bases with explicit document references and vector store connectors, while AnythingLLM focuses on team workspaces with multi-source ingestion and shared knowledge bases.
How important is PDF extraction quality compared to model size?
Extraction quality is more important than model size. Well-chunked, context-rich passages dramatically improve answer accuracy even with mid-sized models. Use tools like unstructured or Docling for layout-aware extraction before focusing on larger models.
Can I run PDF RAG entirely offline on a laptop?
Yes, using GPT4All LocalDocs or LM Studio with local models like Llama-3 8B or Gemma-2-9B. Choose CPU-friendly embeddings (nomic-embed, MiniLM variants) and local vector stores (Chroma, Qdrant) for complete offline operation.
What's the recommended chunk size and retrieval settings for PDFs?
Use 300-800 token chunks with 10-20% overlap, retrieve 4-8 chunks (top_k), and combine BM25/keyword search with vector search for technical documents. Enable reranking with cross-encoders if available for better relevance.
Can a local LLM read scanned PDFs?
Yes, but you must OCR first (Tesseract or similar) or use a vision LLM to extract text/semantics before indexing.
Which is more important: model size or extraction quality?
Extraction quality. Well-chunked, context-rich passages dramatically improve answer accuracy even with mid-sized models.
Can I run embeddings on CPU?
Yes. Choose CPU-friendly embed models (nomic, MiniLM, Jina small) and use Qdrant/Chroma for vectors.
Are there legal/privacy risks running local RAG?
Fewer than cloud services, but you still need to manage access controls, disk encryption, and secure backups.