What Is a Local LLM: The Complete 2025 Guide to Running AI Models on Your Own Hardware
Running large language models locally has become the cornerstone of private, cost-effective AI deployment in 2025, offering organizations and individuals unprecedented control over their artificial intelligence workflows. Unlike cloud-based solutions that process data on remote servers, local LLMs operate entirely on your own hardware, providing enhanced privacy, reduced long-term costs, and customizable performance that's revolutionizing how we interact with AI technology.
Understanding Local Large Language Models
A local LLM (Large Language Model) is an artificial intelligence system that runs directly on your personal computer, server, or local infrastructure, rather than relying on cloud-based services. These models perform identical functions to their cloud counterparts—generating text, answering questions, writing code, and processing natural language—but execute all computations locally on your hardware.
The fundamental distinction lies in data processing location. When you use ChatGPT or similar cloud services, your prompts travel across the internet to remote servers where processing occurs before results return to your device. Local LLMs eliminate this external dependency entirely, processing everything on your local hardware.
The Open Source and Open-Weight Foundation
Most local LLMs are built upon open source or open-weight models, which represent the backbone of the local AI ecosystem. These models have their parameters (weights) publicly accessible, allowing users to download, modify, and redistribute them without restrictions. The landscape has evolved dramatically in 2025 with groundbreaking releases:
Latest Flagship Models (2025):
- Meta's Llama 3.1/3.2 series - ranging from 8B to 405B parameters with enhanced reasoning capabilities
- Alibaba's Qwen3 - featuring hybrid reasoning models from 0.6B to 235B parameters with 119 language support
- Google's Gemma 3 - multimodal models (1B-27B) with 128K context and 140+ language support
- Zhipu AI's GLM-4.5 - MoE architecture with 355B total/32B active parameters, specialized for agentic tasks
- Moonshot AI's Kimi K2 - 1 trillion parameter MoE model with exceptional coding capabilities
- OpenAI's GPT-OSS - recently released 20B and 120B parameter models under Apache 2.0 license
- Microsoft's Phi-4 series - including Phi-4 (14B), Phi-4-mini (3.8B), and Phi-4-mini-flash-reasoning with 10x throughput improvements
Open-weight models differ from fully open-source projects in that they provide access to trained model weights but may not include the complete training code or datasets. This distinction is important for understanding licensing and modification capabilities.
Core Benefits of Local LLM Deployment
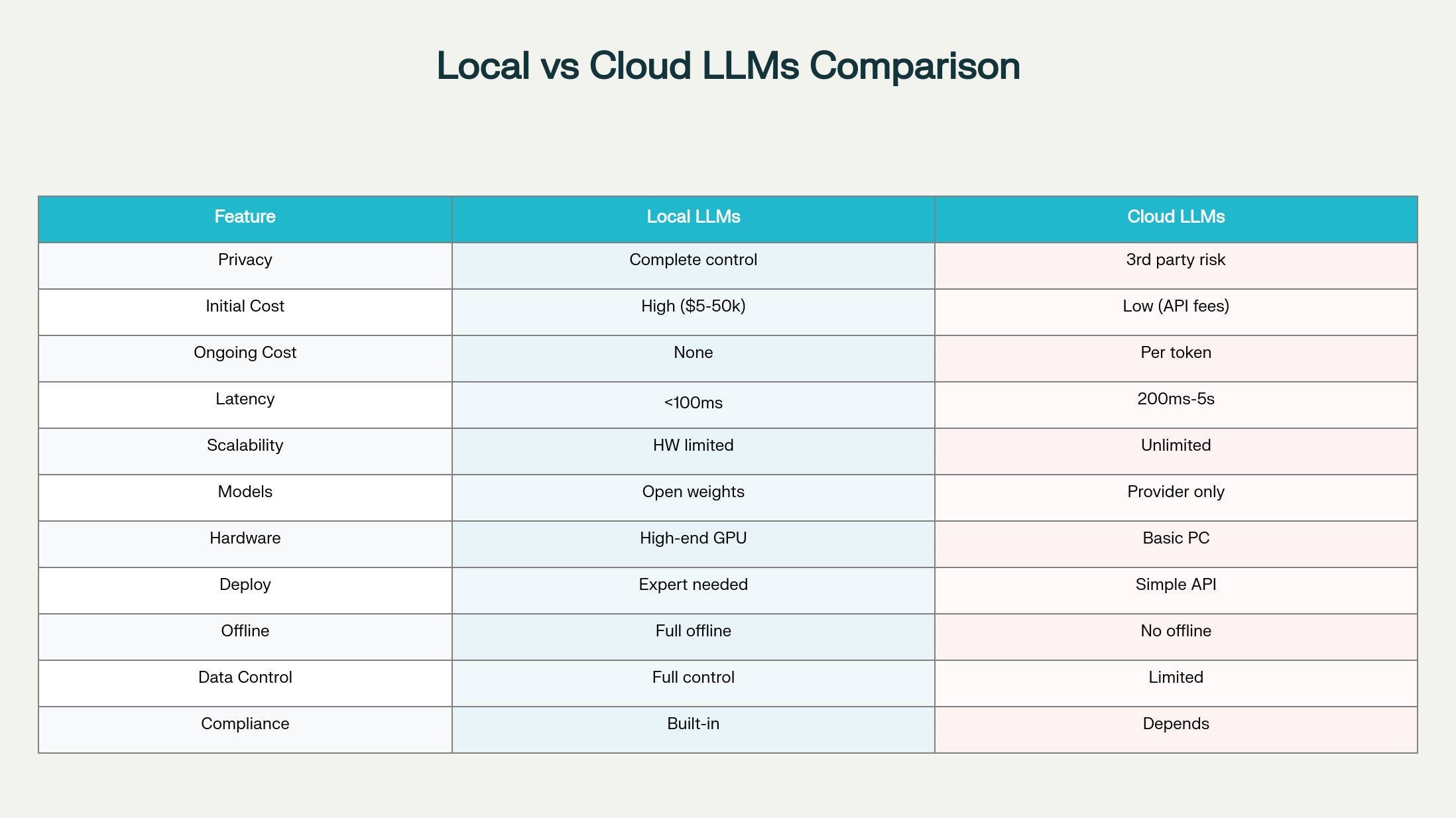
Enhanced Privacy and Security
The most compelling advantage of local LLMs is complete data sovereignty. Every prompt, document, and piece of sensitive information remains within your infrastructure, eliminating risks of data breaches during transmission or unauthorized access by third-party providers. This approach is particularly crucial for industries handling sensitive information such as healthcare, finance, and legal services.
For businesses operating under strict regulatory frameworks like GDPR, HIPAA, or FERPA, local LLMs provide compliance-by-design solutions. Patient records, financial data, and proprietary business information never leave the organization's controlled environment, significantly simplifying regulatory adherence.
Cost-Effectiveness for High-Volume Usage
While local LLMs require substantial upfront hardware investment, they often prove more economical for organizations with consistent AI processing demands. Cloud-based solutions typically charge per token processed—costs that can escalate rapidly with high usage volumes.
Updated 2025 analysis indicates that local deployments can deliver 30-70% cost savings over 18-24 months when utilization exceeds moderate usage levels. For enterprises processing thousands of queries daily, eliminating recurring API fees represents significant long-term savings. Current cloud pricing ranges from $0.15 to $75 per million tokens, while local hardware costs $5K-50K upfront depending on requirements.
Ultra-Low Latency Performance
Local processing eliminates network-dependent delays inherent in cloud solutions. Response times improve dramatically when models process requests directly on local hardware rather than sending data across internet connections to remote servers.
This performance advantage proves critical for real-time applications such as:
- Live customer support chatbots
- Voice assistants requiring instant responses
- Code completion tools used during development
- Real-time translation services
- Edge AI applications in autonomous vehicles
Studies show local LLMs can achieve response times under 100ms compared to 200ms-5s for cloud-based alternatives depending on network conditions.
Complete Offline Functionality
Local LLMs operate independently of internet connectivity, providing reliable AI capabilities in remote locations or during network outages. This offline functionality ensures business continuity and enables AI deployment in environments with limited or unreliable internet access.
The on-device AI market has exploded in 2025, reaching $8.60 billion and projected to grow at 27.8% CAGR through 2030. This growth reflects increasing demand for privacy-first, offline-capable AI solutions across industries.
Popular Tools and Platforms for Local LLM Deployment
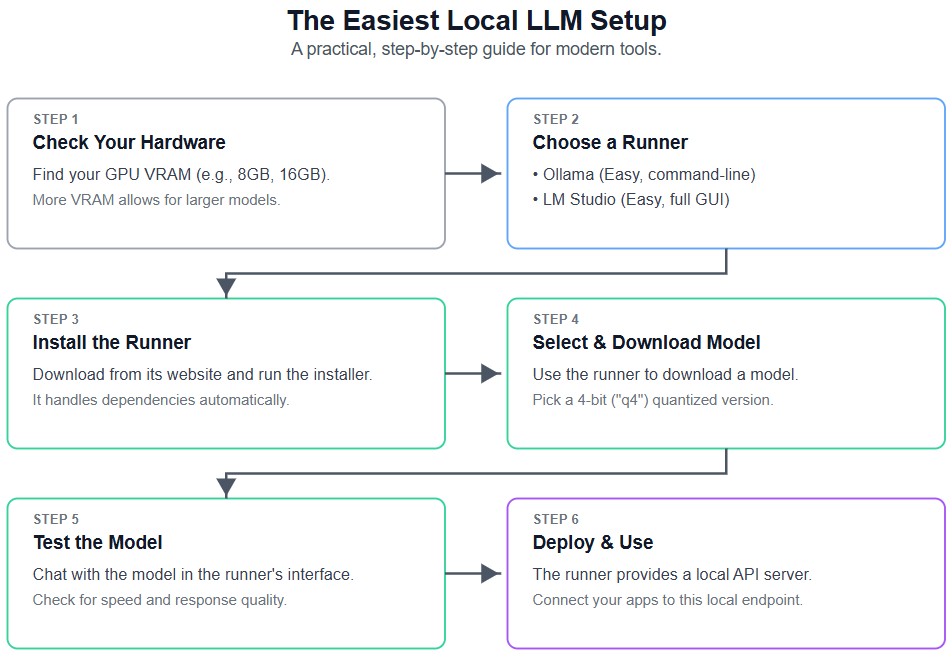
For detailed installation guides and step-by-step instructions, see our comprehensive How to Run a Local LLM Guide.
Ollama: Streamlined Command-Line Deployment
Ollama has emerged as the most user-friendly platform for local LLM deployment in 2025, offering one-line commands to download and run powerful models. The platform supports over 50 models including the latest Qwen3, Gemma 3, and GLM-4.5 releases, with cross-platform compatibility across Windows, macOS, and Linux.
Installation remains minimal:
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Run latest models
ollama run qwen3:4b
ollama run gemma3:8b
ollama run glm-4.5:32b
Ollama provides an OpenAI-compatible API, enabling easy integration with existing applications while maintaining local processing.
LM Studio: Comprehensive GUI Solution
LM Studio continues to excel as the premier graphical interface for users preferring visual model management. The 2025 version features enhanced model discovery, integrated performance monitoring, and improved batch processing capabilities.
Key 2025 features include:
- Support for the latest GGUF formats and quantization methods
- Built-in model comparison and benchmarking tools
- Advanced parameter tuning with real-time feedback
- Integrated development environment for model testing
- Support for multimodal models including vision capabilities
LM Studio particularly excels on systems with NVIDIA RTX GPUs, leveraging GPU acceleration for enhanced performance.
llama.cpp: The Performance Foundation
llama.cpp represents the foundational technology powering most local LLM tools, providing optimized C++ inference for maximum performance. The 2025 version includes native support for the latest model architectures and quantization formats.
Key capabilities include:
- Native support for OpenAI's GPT-OSS models with MXFP4 format
- Optimized inference for Apple Silicon, NVIDIA, AMD, and Intel hardware
- Advanced quantization options (1.5-bit to 8-bit integer quantization)
- CPU+GPU hybrid inference for models larger than VRAM capacity
- OpenAI-compatible API server functionality
Installation options range from simple package managers to custom compilation:
# Simple installation
brew install llama.cpp
# Or compile from source with GPU support
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
GPT4All: Desktop-First Approach
GPT4All provides a refined desktop application designed for everyday users seeking local AI capabilities. The 2025 version includes enhanced model curation, improved performance monitoring, and streamlined user experience.
The platform emphasizes ease of use with guided model selection, automatic dependency management, and integrated chat interfaces. GPT4All supports multiple architectures and offers Python bindings for developers.
LocalAI: OpenAI API Compatibility
LocalAI functions as a comprehensive drop-in replacement for OpenAI's API, supporting multiple model architectures including the latest Transformers, GGUF, and multimodal formats. This compatibility enables seamless migration of existing applications from cloud services to local deployment.
The 2025 platform supports diverse AI capabilities including:
- Text generation with latest language models
- Image generation and understanding
- Audio synthesis and processing
- Voice recognition and cloning
- Autonomous agent orchestration with MCP support
Hardware Requirements and Optimization for 2025
Updated System Specifications
Successfully running local LLMs in 2025 requires updated hardware considerations, with GPU capabilities remaining the primary limiting factor. Essential requirements have evolved:
Graphics Processing Unit (GPU):
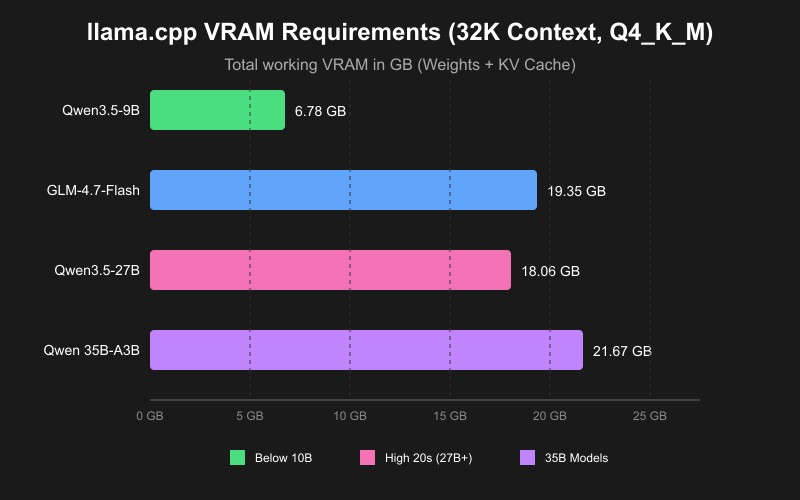
- Entry Level: RTX 3060 Ti (16GB VRAM) - suitable for 7B-13B models
- Recommended: RTX 4090 (24GB VRAM) - handles 30B+ models efficiently
- High Performance: H100 (80GB VRAM) - enterprise deployment for largest models
- Alternative: Multiple RTX 3090 (24GB each) for cost-effective scaling
For detailed GPU recommendations and performance benchmarks, see our comprehensive GPU buying guide for local LLM inference.
Use our Interactive VRAM Calculator to determine the exact hardware requirements for your specific model choices.
System Memory (RAM):
- 16GB minimum for basic 7B models
- 32GB recommended for 13-30B parameter models
- 64GB for 70B+ parameter models
- 128GB+ for production deployments with multiple concurrent users
Processor Requirements:
- AVX2 instruction support (standard on modern CPUs)
- Multi-core processors for efficient parallel processing
- AMD Ryzen 9 7950X3D or Intel Core i9-13900K recommended
- Server-grade AMD EPYC or Intel Xeon for enterprise use
Storage Configuration:
- NVMe SSD mandatory for model loading and inference
- Minimum 1TB capacity for model storage
- Separate OS and model drives recommended
- High-speed networking for distributed deployments
Model Quantization and GGUF Format Evolution
Model quantization remains crucial for local deployment optimization. The GGUF (GPT-Generated Unified Format) has evolved as the definitive standard for quantized model distribution, with improved compression techniques in 2025.
GGUF quantization levels have been refined:
- Q2_K: Extreme compression for resource-constrained devices
- Q4_K_M: Optimal balance for most users - recommended for 2025
- Q5_K_M: Higher quality with moderate size increase
- Q6_K: Near-original quality for critical applications
- Q8_0: Maximum quality retention for production use
Advanced quantization methods introduced in 2025 include MXFP4 (mixed precision) and specialized formats for different model architectures.
Latest Model Landscape and Performance
Breakthrough Models of 2025
The local LLM landscape transformed dramatically in 2025 with several groundbreaking releases:
Qwen3 Series (Alibaba): Released in April 2025, featuring hybrid reasoning capabilities and MoE architecture. The flagship Qwen3-235B-A22B model delivers competitive performance with GPT-4 class models while maintaining open-weight availability. Key innovations include seamless switching between thinking and non-thinking modes, support for 119 languages, and exceptional coding capabilities.
Gemma 3 (Google): Launched in March 2025, representing Google's most advanced open model family. Features include multimodal capabilities (vision + text), 128K context window, and support for 140+ languages. The models range from 1B to 27B parameters with official quantized versions for efficient deployment.
GLM-4.5 (Zhipu AI): Released in July 2025 with 355B total parameters and 32B active parameters. Specifically designed for agentic applications with dual-mode reasoning, exceptional tool-calling capabilities (90.6% success rate), and MIT licensing for commercial use.
Kimi K2 (Moonshot AI): Released in July 2025 as a 1 trillion parameter MoE model with exceptional coding performance. Notable for open-source availability and extremely competitive pricing ($0.15/$2.50 per million tokens), representing a significant challenge to proprietary alternatives.
OpenAI GPT-OSS: Released in August 2025 as OpenAI's first open-weight models under Apache 2.0 license. The GPT-OSS-120B model achieves parity with OpenAI's o4-mini while running on a single 80GB GPU, while GPT-OSS-20B operates on 16GB memory devices.
Microsoft Phi-4 Series: Enhanced in 2025 with Phi-4-mini-flash-reasoning featuring 10x higher throughput and new SambaY architecture. Optimized for mathematical reasoning and edge deployment with significantly improved efficiency.
Compare these models side-by-side using our Model Comparison Tool to find the best fit for your specific requirements.
Enterprise Use Cases and Real-World Applications
Internal Knowledge Management and Document Processing
Organizations deploy local LLMs to create intelligent knowledge bases that understand proprietary terminology, processes, and institutional knowledge. These systems process internal documents, answer employee questions, and provide contextual information without exposing sensitive data externally.
The 2025 enterprise adoption rate has reached 67% globally, with organizations investing over $250,000 annually in LLM technologies. Law firms utilize local LLMs to analyze legal documents and case files while maintaining attorney-client privilege. Healthcare organizations process patient records and research data locally to ensure HIPAA compliance.
Advanced Code Generation and Development Support
Development teams increasingly rely on local LLMs for comprehensive coding assistance, with 2025 models showing dramatic improvements in code generation accuracy. Unlike cloud-based coding assistants, local models can analyze proprietary codebases without data leaving the organization.
Companies report 20-40% productivity improvements when developers use local AI assistants for routine coding tasks. The latest models like Kimi K2 and GLM-4.5 excel at generating complex code, debugging applications, and providing architectural guidance based on internal standards.
Customer Service and Intelligent Automation
Local LLMs power sophisticated chatbots and virtual assistants that handle customer inquiries while keeping interaction data private. These systems can be trained on product documentation, support tickets, and company-specific knowledge to provide accurate, contextual responses.
Organizations report 70-90% query resolution rates with local AI assistants, significantly reducing human support workload while maintaining data security. The ability to operate offline ensures continuous service availability regardless of internet connectivity.
Performance Optimization and Production Deployment
Advanced Inference Optimization
Maximizing local LLM performance in 2025 requires strategic optimization across multiple dimensions. Key performance metrics include:
Time to First Token (TTFT): Critical for interactive applications, optimized through:
- Tensor parallelism across multiple GPUs
- Advanced quantization reducing memory bandwidth requirements
- Optimized prompt processing algorithms
- Speculative decoding for faster generation
Throughput Optimization: Total tokens generated per second, enhanced by:
- Dynamic batching for multiple concurrent requests
- Memory optimization maximizing concurrent users
- Hardware-specific optimizations for different GPU architectures
- Load balancing across distributed deployments
Infrastructure Scaling and Management
Enterprise deployments require sophisticated infrastructure management. Critical considerations for 2025 include:
- Memory bandwidth optimization: DDR5-5600+ RAM significantly improves performance
- Storage architecture: NVMe RAID configurations for model loading
- Network topology: High-speed interconnects for distributed inference
- Cooling and power: Efficient thermal management for continuous operation
Market Trends and Future Outlook
Explosive Market Growth
The local AI market is experiencing unprecedented growth in 2025. Edge AI market size reached $20.78 billion in 2024 and is projected to reach $269.82 billion by 2032 at 33.3% CAGR. On-device AI specifically grew from $8.60 billion in 2024 to a projected $36.64 billion by 2030 at 27.8% CAGR.
This growth reflects fundamental shifts in enterprise priorities, with 72% of organizations increasing their LLM investments in 2025. Security and privacy concerns drive 44% of adoption decisions, while cost optimization motivates long-term deployment strategies.
Emerging Technological Trends
Several key trends are shaping the 2025 local LLM landscape:
Hardware Innovation: Specialized NPUs (Neural Processing Units) and AI accelerators are becoming standard in consumer devices. Companies like Qualcomm, MediaTek, and Samsung are integrating dedicated AI processing units into smartphones and edge devices.
Model Efficiency: Advanced architectures like MoE (Mixture of Experts) enable larger models to run efficiently on consumer hardware. Hybrid reasoning capabilities allow models to dynamically allocate computational resources based on task complexity.
Integration Platforms: Comprehensive development frameworks like Microsoft's Foundry Local, Apple's Foundation Model framework, and Google's Edge Gallery are democratizing local AI deployment.
Regulatory Alignment: The EU's Artificial Intelligence Act and similar regulations are driving demand for privacy-compliant local solutions. Data residency requirements increasingly favor local deployment over cloud alternatives.
Challenges and Mitigation Strategies
Technical Complexity and Solutions
While local LLM deployment has become more accessible in 2025, technical challenges remain. Key issues and solutions include:
Installation Complexity: Mitigated by improved tools like Ollama's one-line installation and LM Studio's guided setup processes. Container-based deployments using Docker and Kubernetes simplify enterprise adoption.
Model Selection: Overwhelming choice of models resolved through comprehensive benchmarking platforms and community-driven rankings. Automated model recommendation systems based on use case and hardware constraints.
Performance Optimization: Complex tuning simplified through automated configuration tools and performance monitoring dashboards. Cloud-based optimization services for local deployment parameter tuning.
Resource Requirements and Scaling
Hardware investment barriers are being addressed through innovative approaches:
Cost Reduction: GPU sharing platforms, leasing options, and tiered deployment strategies make high-end hardware more accessible. Cloud-to-edge migration tools enable gradual transition from cloud services.
Scalability Solutions: Distributed inference frameworks enable horizontal scaling across multiple lower-tier GPUs. Model sharding techniques allow large models to run on commodity hardware clusters.
Conclusion
Local LLMs have evolved from experimental technology to production-ready solutions in 2025, offering organizations unprecedented control over their AI capabilities while addressing critical concerns around privacy, security, and long-term costs. The release of groundbreaking models like Qwen3, Gemma 3, GLM-4.5, Kimi K2, and OpenAI's GPT-OSS series has democratized access to frontier AI capabilities.
The decision between local and cloud deployment increasingly favors local solutions for privacy-sensitive applications, cost-conscious enterprises, and performance-critical use cases. With over 67% of organizations now deploying LLMs and the on-device AI market projected to reach $36.64 billion by 2030, local deployment has become a strategic imperative rather than a technical curiosity.
As we progress through 2025, the local LLM ecosystem continues maturing with improved tools, more efficient models, and better hardware integration. The foundation established by open-source initiatives, enhanced by commercial innovation, and driven by regulatory requirements ensures that local LLMs will remain the preferred solution for organizations prioritizing data sovereignty, operational efficiency, and long-term AI strategy.
The future of artificial intelligence is increasingly local, private, and under user control—representing not just a technological shift, but a fundamental realignment of power in the AI ecosystem toward users and organizations rather than centralized cloud providers.
Ready to Get Started?
Ready to deploy your own local LLM? Check out our comprehensive setup guide for step-by-step instructions, use our VRAM Calculator to plan your hardware, and explore our Model Comparison Tool to choose the perfect model for your needs.