How to Run Local LLMs: The Ultimate Guide for 2025
The landscape of artificial intelligence has undergone a dramatic transformation in 2025, with local Large Language Models (LLMs) becoming increasingly accessible and powerful. Running LLMs locally offers unprecedented privacy, cost savings, and control over your AI infrastructure, making it an attractive alternative to cloud-based solutions for individuals, developers, and organizations alike.
This comprehensive guide explores the latest methods, hardware requirements, and best practices for running local LLMs in 2025, incorporating the most recent developments in model optimization, quantization techniques, and deployment tools. If you're new to local LLMs, start with our foundational guide to understand the basics.
Understanding Local LLMs: The Foundation
Local LLMs represent a paradigm shift from cloud-dependent AI services to self-hosted solutions that run entirely on your hardware. Unlike cloud-based models that require internet connectivity and raise privacy concerns, local LLMs provide complete data sovereignty and offline functionality. In 2025, the ecosystem has matured significantly, with models like Llama 3.1, Qwen 2.5, DeepSeek R1, and Phi-4 offering remarkable capabilities while remaining efficient enough for consumer hardware. For a deeper understanding of what local LLMs are and their benefits, see our complete introduction to local LLMs.
The advantages of local deployment extend beyond privacy. Organizations can achieve substantial cost savings by eliminating recurring API fees, particularly for high-volume applications involving document processing, code generation, or conversational AI. Additionally, local deployment provides complete control over model behavior, enabling fine-tuning and customization impossible with cloud services.
Hardware Requirements: Navigating the Specifications
GPU Considerations
The most critical component for local LLM deployment is the Graphics Processing Unit (GPU), specifically its Video Random Access Memory (VRAM) capacity. In 2025, VRAM requirements vary significantly based on model size and precision.
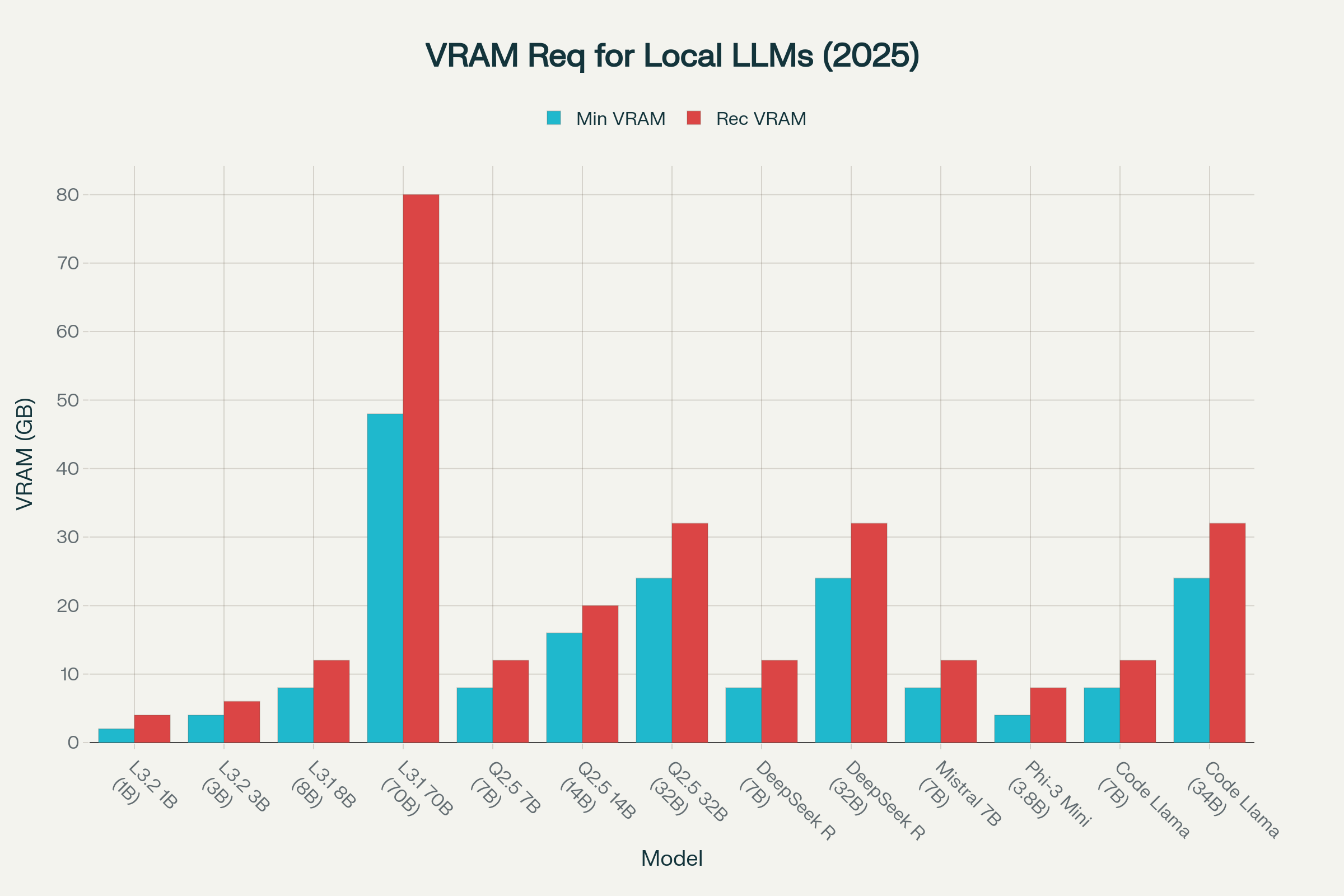
VRAM requirements comparison showing minimum and recommended memory for popular local LLMs in 2025
For entry-level deployment, 8-12GB VRAM accommodates most 7-8B parameter models like Llama 3.1 8B or Qwen 2.5 7B, suitable for general-purpose applications. Professional users requiring larger models should consider 16-24GB VRAM configurations, enabling 14-32B parameter models like Qwen 2.5 14B or DeepSeek R1 32B. Enterprise deployments often necessitate 48GB+ VRAM for models like Llama 3.1 70B, typically requiring multiple high-end GPUs or specialized hardware.
The rule of thumb for VRAM calculation follows the formula: M = (P × Q/8) × 1.2, where M represents required memory in GB, P is the parameter count in billions, Q is precision in bits, and 1.2 accounts for overhead. For example, a 70B model in 16-bit precision requires approximately 168GB of VRAM, while 4-bit quantization reduces this to roughly 42GB. Use our Interactive VRAM Calculator for precise calculations based on your specific model choices.
CPU Performance and Memory Bandwidth
Recent developments in 2025 have highlighted the importance of CPU performance for local LLM inference. Modern CPUs with optimized instruction sets like AVX-512 can achieve surprising performance levels, particularly for smaller models. AMD's Ryzen AI 9 HX 375 processor demonstrates up to 50.7 tokens per second with Llama 3.2 1B, showcasing the viability of CPU-only deployments.
System RAM requirements typically range from 32GB minimum for smaller models to 128GB or more for large model deployment on CPU. High memory bandwidth becomes crucial for CPU inference, with multi-channel configurations significantly outperforming dual-channel setups.
Performance Benchmarks
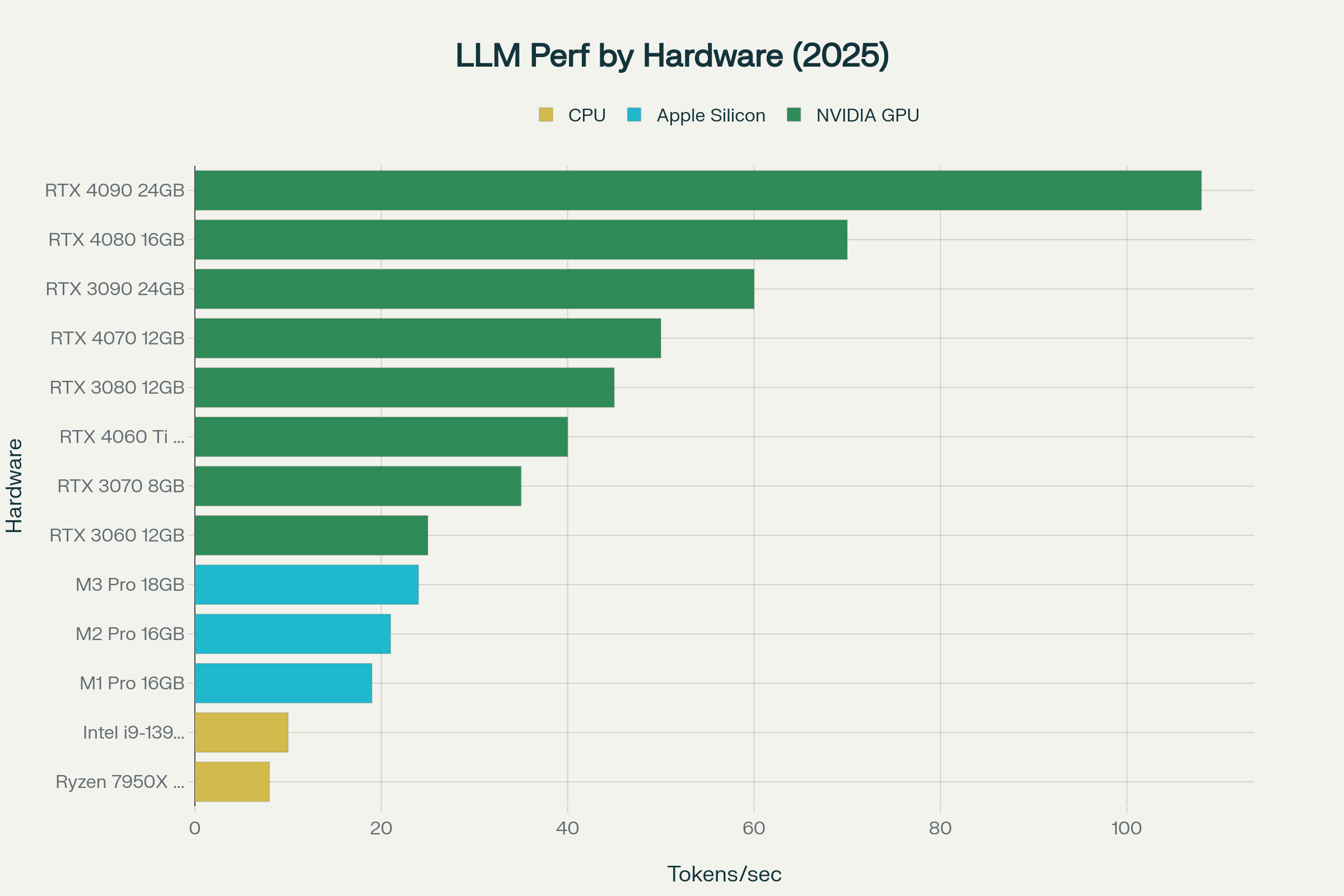
Performance comparison showing tokens per second across different hardware configurations for local LLM inference
Performance varies dramatically across hardware configurations. High-end GPUs like the RTX 4090 achieve over 100 tokens per second with 7B models, while more modest hardware like the RTX 3060 provides 25-30 tokens per second—still adequate for most interactive applications. Apple Silicon demonstrates competitive performance with excellent power efficiency, making MacBooks viable platforms for local LLM deployment.
Popular Local LLM Frameworks and Tools
Ollama: The User-Friendly Champion
Ollama has emerged as the most popular tool for local LLM deployment in 2025, combining ease of use with powerful functionality. Its Docker-like approach to model management makes installation and operation straightforward:
# Install Ollama (Linux/macOS) curl -fsSL https://ollama.com/install.sh | sh # Pull and run a model ollama pull llama3.1:8b ollama run llama3.1:8b
Ollama automatically handles model quantization, memory management, and GPU acceleration, making it ideal for users who want immediate functionality without technical complexity. The platform supports over 30 models and provides OpenAI-compatible APIs for easy integration.
LM Studio: The Graphical Interface
LM Studio provides the most polished graphical user interface for local LLM deployment, particularly appealing to non-technical users. Its key advantages include direct Hugging Face integration, built-in chat interfaces, and comprehensive model management through an intuitive GUI.
The platform excels in model discovery and testing, allowing users to easily download, configure, and experiment with different models without command-line interaction. However, it trades some flexibility for user-friendliness compared to command-line alternatives.
llama.cpp: The Performance Powerhouse
For users prioritizing maximum performance and customization, llama.cpp remains the gold standard. This C++ implementation provides state-of-the-art optimization techniques, including advanced quantization methods and hardware-specific optimizations.
Recent developments in 2025 include improved ARM CPU optimizations, particularly benefiting Snapdragon X and Apple Silicon platforms. The framework supports multiple backends including CUDA, Metal, and Vulkan, ensuring optimal performance across diverse hardware configurations.
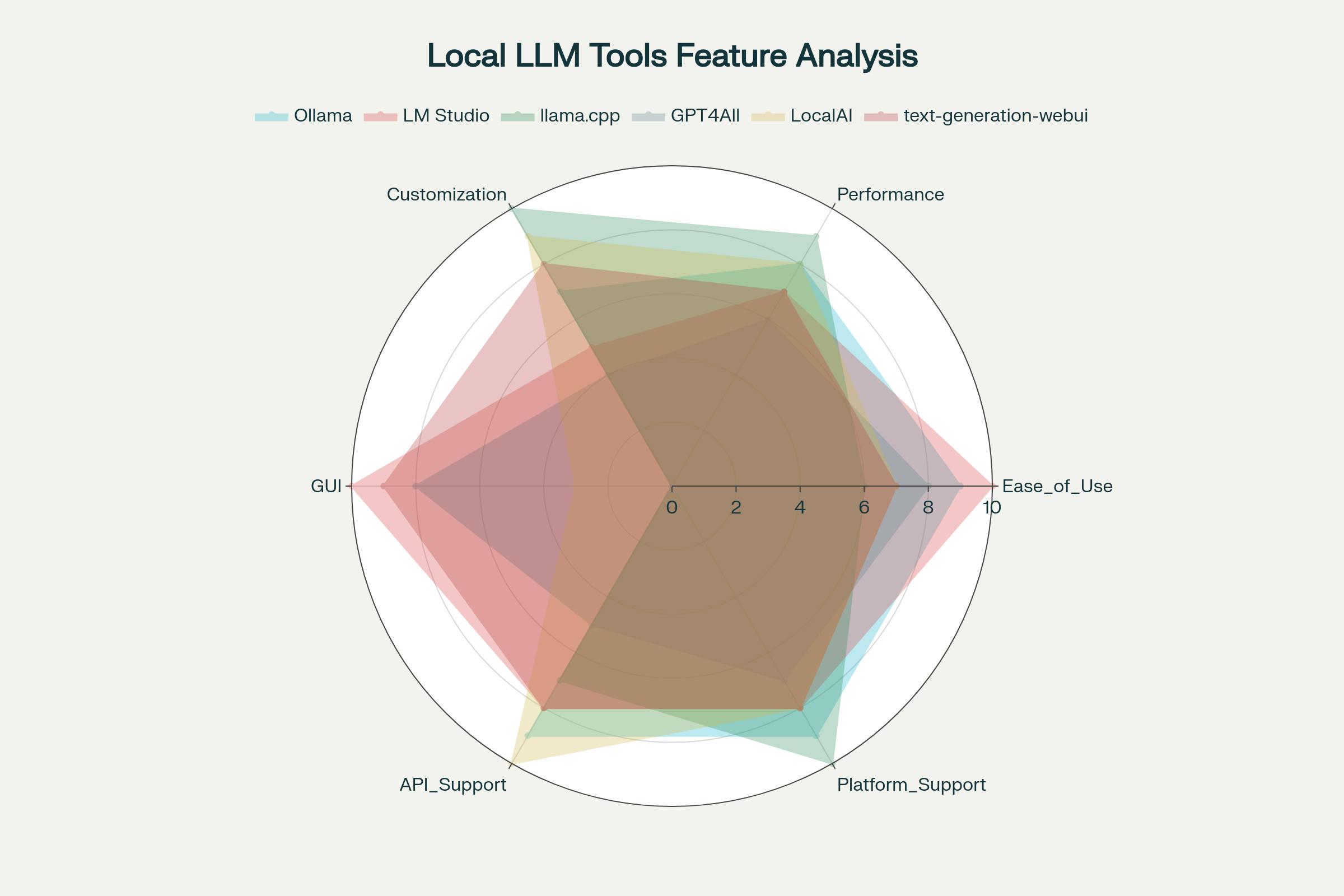
Comprehensive comparison of popular local LLM tools across key features and capabilities
Installation and Setup Process
Step 1: System Preparation
Before installation, ensure your system meets minimum requirements:
- Operating System: Windows 10+, macOS 12+, or modern Linux distribution
- RAM: 16GB minimum (32GB+ recommended)
- Storage: 50GB+ free space for models
- GPU: Optional but recommended for optimal performance
Step 2: Choose Your Framework
Select the appropriate tool based on your needs:
- Ollama: Best for beginners and quick deployment
- LM Studio: Ideal for GUI preference and model experimentation
- llama.cpp: Optimal for advanced users seeking maximum performance
- GPT4All: Good balance of features with desktop application
- LocalAI: Excellent for API-first deployments
Step 3: Model Selection and Download
Model selection depends on your hardware capabilities and use case requirements. Use our Model Comparison Tool to find the perfect model for your needs. Popular choices in 2025 include:
- Lightweight models (1-3B parameters): Phi-3 Mini, Llama 3.2 1B for resource-constrained environments
- General purpose (7-8B parameters): Llama 3.1 8B, Qwen 2.5 7B for balanced performance
- Professional grade (14-32B parameters): Qwen 2.5 14B, DeepSeek R1 32B for advanced applications
- Enterprise level (70B+ parameters): Llama 3.1 70B for demanding tasks
Step 4: Optimization and Configuration
Modern frameworks automatically handle quantization and optimization, but manual tuning can improve performance:
- Quantization: 4-bit quantization typically provides the best balance of size and quality
- Context length: Adjust based on your application needs and available memory
- Batch size: Optimize for throughput vs. latency requirements
- GPU layers: Configure offloading for hybrid CPU/GPU deployments
Advanced Deployment Strategies
Quantization Techniques
Quantization has evolved significantly in 2025, with new methods providing better quality at lower bit-widths. 4-bit quantization (Q4_K_M) offers excellent compression with minimal quality loss, while 8-bit quantization (Q8_0) provides near-native quality with 50% memory reduction.
Recent innovations like Q4_0_4_8 quantization specifically optimize ARM architectures, providing 2-3x performance improvements on Snapdragon and Apple Silicon platforms.
Multi-GPU and Distributed Deployment
For enterprise applications, multiple GPU configurations enable deployment of very large models. Tensor parallelism allows distribution of 70B+ models across multiple GPUs, with frameworks like vLLM and text-generation-webui providing built-in support for multi-GPU setups.
Cost-Performance Optimization
Local deployment offers significant cost advantages over cloud services, particularly for high-volume applications. While cloud APIs charge per token, local deployment involves only initial hardware costs and ongoing electricity consumption. For businesses processing millions of tokens monthly, local deployment can reduce costs by 80-90% after the initial hardware investment.
Troubleshooting and Performance Optimization
Common Issues and Solutions
Memory limitations represent the most frequent challenge in local LLM deployment. Solutions include:
- Reducing model size through quantization
- Adjusting context length to fit available memory
- Implementing model offloading between CPU and GPU
- Using gradient checkpointing for memory efficiency
Performance bottlenecks often relate to memory bandwidth rather than compute power. Optimizations include:
- Ensuring adequate cooling for sustained performance
- Using high-speed memory (DDR5-5600+)
- Configuring optimal thread counts for CPU inference
- Implementing proper GPU memory management
Monitoring and Metrics
Key performance indicators for local LLM deployment include:
- Tokens per second: Primary throughput metric
- Time to first token: Latency measurement for responsiveness
- Memory utilization: VRAM and system RAM usage
- Power consumption: Important for mobile and cost-conscious deployments
Future Outlook and Emerging Trends
The local LLM landscape continues evolving rapidly in 2025. Emerging trends include:
- Mixture of Experts (MoE) models offering improved efficiency through sparse activation patterns
- Multimodal integration enabling vision, audio, and code understanding in unified models
- Edge optimization bringing LLM capabilities to mobile devices and embedded systems
Specialized hardware development, including dedicated inference accelerators and optimized mobile processors, promises to further democratize local LLM deployment.
Production Deployment Architecture
Conclusion
Running local LLMs in 2025 has become remarkably accessible, offering compelling advantages in privacy, cost-effectiveness, and customization. Whether you're a developer seeking offline AI capabilities, an organization requiring data sovereignty, or an enthusiast exploring AI possibilities, local LLM deployment provides practical solutions across a wide range of hardware configurations.
The maturity of tools like Ollama, LM Studio, and llama.cpp, combined with increasingly efficient models and optimization techniques, makes local deployment viable for most users. As the ecosystem continues evolving, local LLMs represent not just an alternative to cloud services, but often the superior choice for many applications.
Success in local LLM deployment requires careful consideration of hardware requirements, tool selection, and optimization strategies. However, with proper planning and the guidance provided in this comprehensive guide, anyone can harness the power of large language models running entirely on their own hardware, ensuring privacy, reducing costs, and maintaining complete control over their AI infrastructure.
Frequently Asked Questions
What are the minimum hardware requirements for running local LLMs?
For basic usage, you need at least 16GB RAM, 50GB storage, and preferably a GPU with 8GB+ VRAM. Entry-level models (7-8B parameters) can run on GPUs like RTX 3060 with 8GB VRAM, while larger models require 16-24GB VRAM or more. CPU-only operation is possible but significantly slower.
Which framework should I choose as a beginner?
Ollama is currently the most beginner-friendly framework, offering a Docker-like experience with simple commands for installation and model management. LM Studio is another excellent choice for beginners, providing a graphical interface and intuitive model management.
How much can I save by running LLMs locally?
Organizations can save 80-90% on costs compared to cloud APIs, particularly for high-volume applications. While there's an initial hardware investment, local deployment eliminates per-token charges, making it highly cost-effective for continuous usage.
Can I run large models like 70B parameter LLMs locally?
Yes, but they require significant hardware resources. A 70B model typically needs 48GB+ VRAM even with 4-bit quantization. Multi-GPU setups or specialized hardware may be necessary. Alternatively, smaller 7-14B models offer good performance with more modest hardware requirements.
What's the best quantization method for local LLMs?
4-bit quantization (Q4_K_M) typically provides the best balance between model size and performance in 2025. It reduces VRAM requirements by 75% with minimal quality loss. For ARM architectures, the new Q4_0_4_8 quantization offers additional optimization.
How do I choose the right model for my needs?
Consider your hardware capabilities, use case, and performance requirements. For general-purpose tasks, 7-8B models like Llama 3.1 8B or Qwen 2.5 7B work well on consumer hardware. For advanced applications, larger models like DeepSeek R1 32B or Llama 3.1 70B offer superior capabilities but require more powerful hardware.
Can I run local LLMs completely offline?
Yes, once models are downloaded, all major frameworks support completely offline operation. This makes local LLMs ideal for privacy-sensitive applications or environments without internet access.
What about API compatibility with existing applications?
Many frameworks now offer OpenAI-compatible APIs, allowing you to migrate existing applications to local deployment with minimal code changes. Tools like vLLM and LocalAI provide drop-in replacements for OpenAI's API endpoints.
Ready to Get Started?
Explore our Interactive VRAM Calculator to determine the perfect hardware setup for your needs, or check out our Model Comparison Tool to find the ideal model for your use case.