
Best Local LLM for Coding in 2025
If you're new to local LLMs, you might want to first read our guide on what is a local LLM for background. For coding specifically, these are the best models in 2025: Qwen3-Coder, GLM-4.5 / 4.5-Air, GPT-OSS (120B / 20B open-weights), Codestral-22B, StarCoder2, and DeepSeek-Coder-V2. Below I explain where each shines, what hardware they like, and how to run them today.
TL;DR (quick picks)
- Best bleeding-edge local coder (MoE + long context): Qwen3-Coder — 256K context, strong repo-level coding, two MoE sizes (480B A35B and 30B A3B). You’ll want optimized runtimes (vLLM/SGLang) and decent VRAM; quantized builds help.
- Best “fully open-weights from a big lab” you can run anywhere: GPT-OSS-20B (and 120B if you’ve got the GPUs). OpenAI released weights with broad ecosystem support (Ollama, vLLM, llama.cpp, LM Studio, Apple Metal, etc.).
- Best reasoning-forward Chinese/English coder, long context: GLM-4.5 (355B A32B) or GLM-4.5-Air (106B A12B) — both 128K context, good thinking-mode support, solid local serving via vLLM/SGLang.
- Best compact code specialist you can fit on a single high-end GPU: Codestral-22B — 32K context, strong long-range code tasks (RepoBench). Easy local use and now on Ollama.
- Proven open code models for smaller rigs & fine-tuning: StarCoder2 (3B/15B) and DeepSeek-Coder-V2 (Lite/16B). Great for on-device or lightweight servers; big community tooling.
What’s new in 2025?
Qwen3 & Qwen3-Coder (Alibaba)
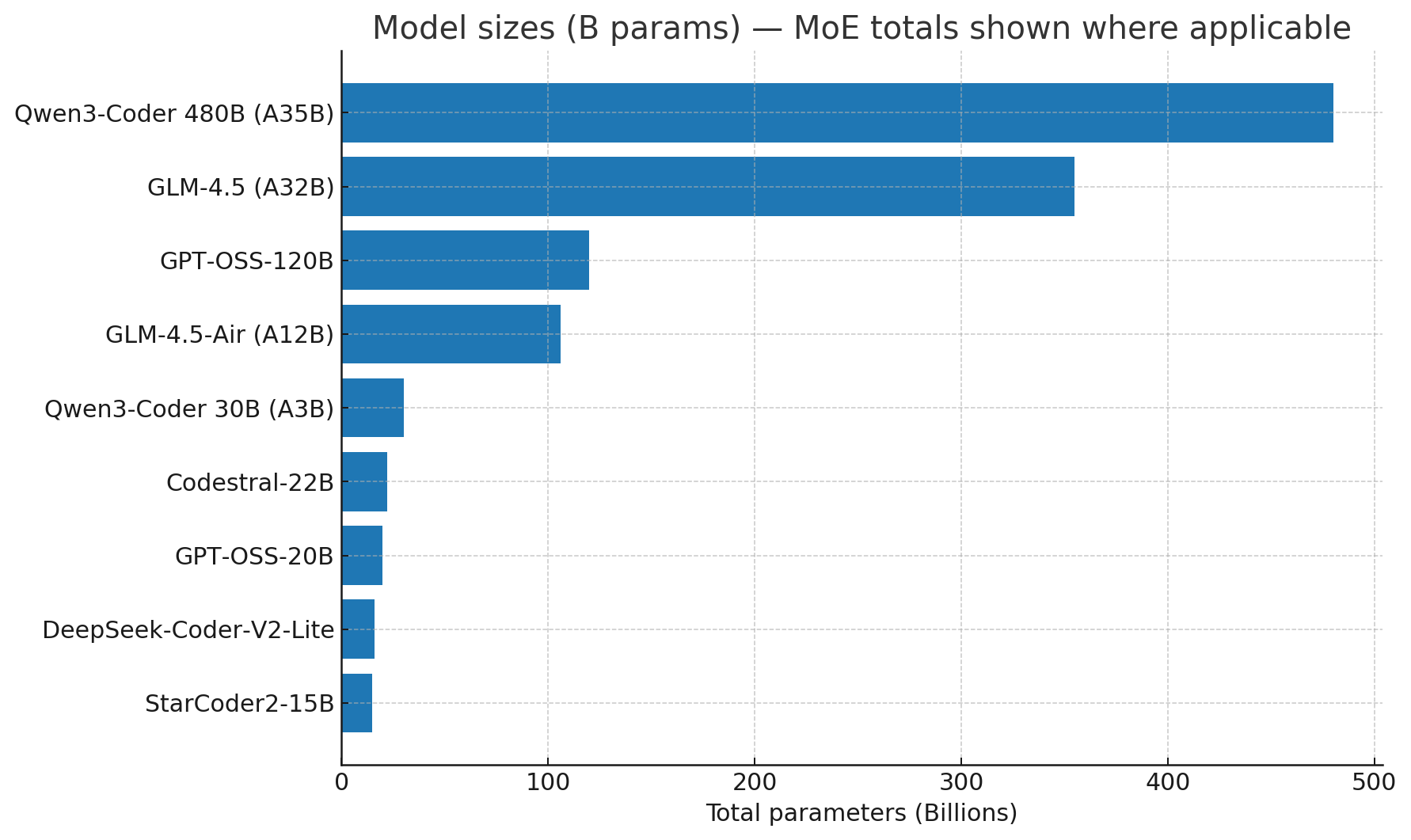
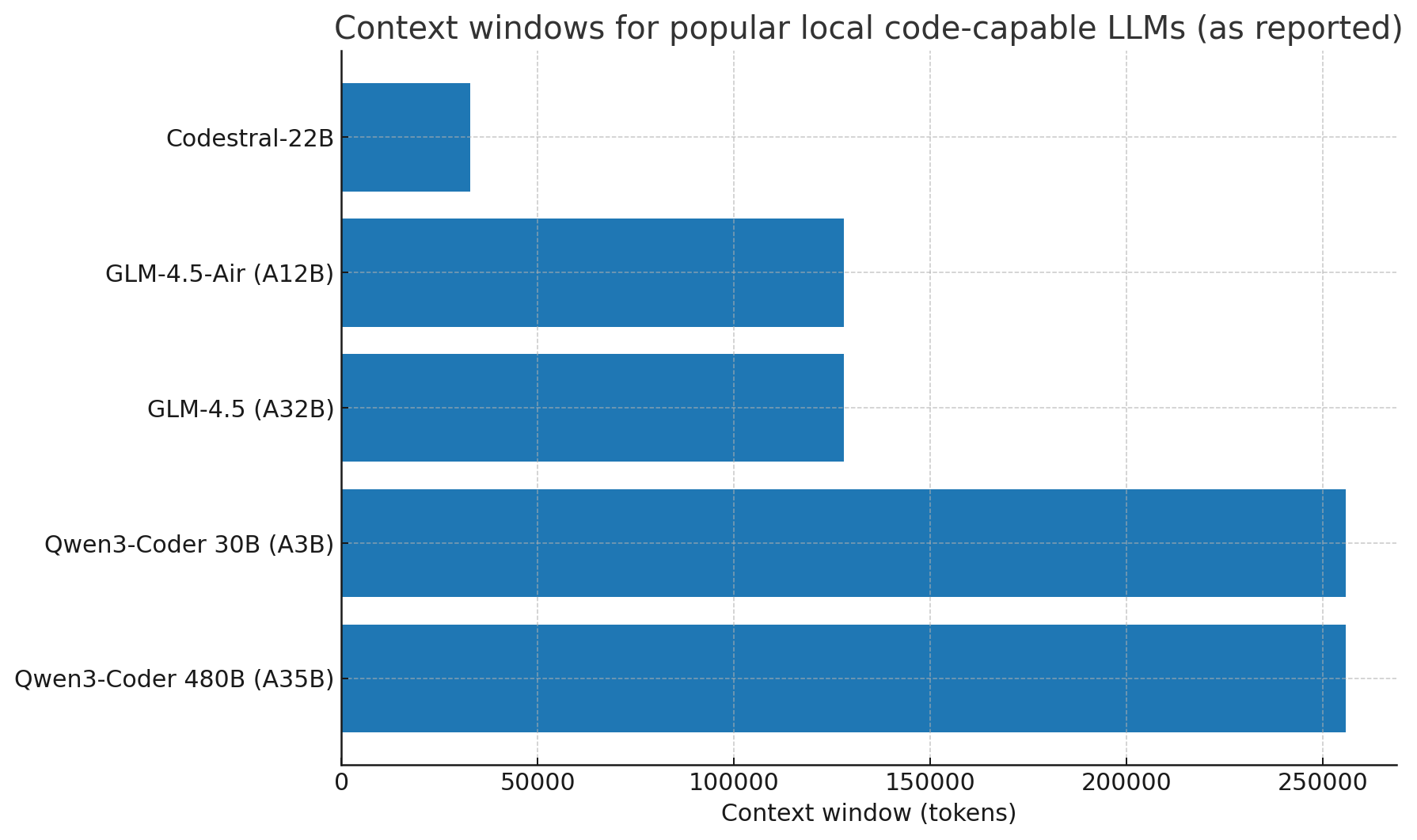
Qwen3 is the next-gen family (dense + MoE) from Alibaba; Qwen3-Coder is the code-specialist branch. The coder model ships in 480B (A35B) MoE and 30B (A3B) MoE variants with a 256K context window and impressive repository-level coding results.
The 480B configuration activates ~35B experts per token; the 30B activates ~3B — giving you large-model quality with more efficient compute at inference.
GLM-4.5 & GLM-4.5-Air (Zhipu AI)
GLM-4.5 introduces 355B (A32B), with GLM-4.5-Air at 106B (A12B). Both feature 128K context and “thinking mode” variants. Open report + docs, plus clear local serving guides.
The ecosystem includes vLLM/SGLang quick-starts; easy for self-hosting.
GPT-OSS (OpenAI)
Open-weights models from OpenAI: gpt-oss-120b and gpt-oss-20b. Trained with SFT + RL “o-series-style” post-training; designed to run anywhere (local, on-device, or 3rd-party). OpenAI partnered for vLLM, Ollama, llama.cpp, LM Studio, Apple Metal, etc., and Microsoft is shipping Windows-optimized builds for the 20B.
Codestral-22B (Mistral)
A focused, permissive 22B code model with 32K context and strong repo-level performance. Good balance of quality vs. latency; easy to run locally (and available via Ollama).
Also solid & widely used
- StarCoder2 (3B/7B/15B family) — open, well-documented, and popular for fine-tuning and IDE tooling.
- DeepSeek-Coder-V2 (Lite/16B/etc.) — multilingual code model family with repo-level tasks and open tooling.
What should you run locally?
If you have a single high-end GPU (24–48 GB VRAM)
- Codestral-22B (4-bit quantized) is a sweet spot for quality + latency + context (32K). Easy via Ollama/vLLM.
- GLM-4.5-Air (106B A12B) can be workable with tensor/kv-cache tuning on multi-GPU or compact quantization; consider SGLang/vLLM for throughput.
If you can go multi-GPU or have a small server
- Qwen3-Coder (30B A3B) for repo-level tasks with 256K context; use vLLM or SGLang and quantization.
- GPT-OSS-120B (if you’ve got the hardware) or the 20B on modest setups; both integrate across local toolchains.
If you’re on a laptop/M-series Mac or small desktop
- StarCoder2-15B or 3B, or DeepSeek-Coder-V2-Lite — great for on-device dev assistants and fast iterations.
How to run these locally (quick starts)
Tip: Prefer vLLM or SGLang for long-context coding and higher throughput; use Ollama for dead-simple desktop setups. For more on Ollama and alternatives, check out our complete guide to Ollama alternatives.
Ollama (desktop-friendly)
# Codestral (22B)
ollama run codestral
# (Ollama adds models over time; check the library for availability.)
Ollama’s public library includes codestral now; Qwen3-Coder entries are emerging in the ecosystem as well.
vLLM / SGLang (server-grade, long context, batching)
GLM-4.5/4.5-V docs show one-liners for vLLM and SGLang (very similar for text-only LMs).
# vLLM example (model name varies by checkpoint)
vllm serve zai-org/GLM-4.5V --tensor-parallel-size 4
# SGLang example
python3 -m sglang.launch_server --model-path zai-org/GLM-4.5V --tp-size 4
GPT-OSS (OpenAI open-weights)
OpenAI’s release states the 20B/120B weights run locally and are supported across Ollama, vLLM, llama.cpp, LM Studio, Apple Metal, and more.
Model snapshots (why you’d pick each)
- Qwen3-Coder — Long-context repo work, strong tool use, and MoE efficiency (A35B/A3B). Best for complex refactors, multi-file edits, and “read a large codebase, then implement.”
- GLM-4.5 / 4.5-Air — Reasoning-centric coding and 128K context. Thinking-mode settings and active-parameter MoE help performance/latency trade-offs.
- GPT-OSS (20B/120B) — First-party open-weights from OpenAI with broad local tooling support; a pragmatic “just works” option across operating systems.
- Codestral-22B — Purpose-built for code with 32K context and strong repo-bench results; excellent single-GPU choice.
- StarCoder2 — Community favorite for customization, permissive licensing, and IDE integrations.
- DeepSeek-Coder-V2 — Competitive multilingual coder family with clear repo-level tasks and open training details. For more on DeepSeek's capabilities, see our DeepSeek V3.1 review.
Frequently Asked Questions
What is the minimum VRAM required to run these coding LLMs locally?
For entry-level local coding assistance, you can run StarCoder2-3B or DeepSeek-Coder-V2-Lite with as little as 8GB VRAM. For better performance, Codestral-22B (4-bit quantized) requires 24GB VRAM, while larger models like Qwen3-Coder and GLM-4.5 need multiple GPUs or higher VRAM configurations.
Which local LLM is best for multi-language coding projects?
DeepSeek-Coder-V2 and StarCoder2 are specifically designed for multilingual coding support. They both handle multiple programming languages effectively and come with comprehensive documentation for various language-specific tasks.
Can these models work offline completely?
Yes, once downloaded, all these models can run completely offline. Tools like Ollama, vLLM, and SGLang enable fully local operation without any internet connection required for inference.
How do I choose between MoE and dense models for coding?
MoE (Mixture of Experts) models like Qwen3-Coder offer better efficiency by activating only relevant experts per token. Choose MoE models (like Qwen3-Coder) for complex, repo-level tasks if you have the hardware. For simpler coding tasks or limited hardware, dense models like Codestral-22B or StarCoder2 are more practical.
What's the advantage of models with longer context windows?
Longer context windows (like Qwen3-Coder's 256K or GLM-4.5's 128K) allow the model to understand larger codebases, multiple files, and longer discussions. This is particularly valuable for complex refactoring tasks or when working with large repositories.


