Best Local LLMs for 8GB VRAM: Real Hardware Benchmarks (2026)
8GB VRAM cards make up a huge share of the consumer GPU market. The RTX 4060, RTX 3070, and RTX 3060 Ti all sit in this tier, and tens of millions of people own them. The problem is that model selection advice for this tier is largely guesswork, blog posts compare benchmark scores without ever running the models, and token counts on Hugging Face tell you the file size but not how much VRAM the model actually consumes once the inference engine loads it. New to local LLMs? Our introduction to local LLMs is a good starting point.
We fixed that. We ran five of the highest ranked open weight models in the 7B–14B range through a structured benchmark on RTX 3070: four context sizes (4K, 8K, 16K, 32K), Q4_K_M quantization. We measured GPU VRAM consumed down to the megabyte, decode speed in tokens per second, prefill speed, and time-to-first-token at every context size. Then we asked each model to write a functional smart-home dashboard in a single HTML file, a practical test that separates instruction-following from raw benchmark score. Since Ollama and LM Studio both use llama.cpp under the hood, every number in this guide applies directly to your Ollama chatbot or desktop assistant setup.
The results are striking. Two models, Qwen3.5-9B and GLM-4.6V-Flash, fit entirely in GPU memory and deliver around 55–58 tokens per second flat across all context sizes up to 16K. The three 12B–14B models all spill layers to system RAM, cutting decode speed to 4–11 tokens per second. And Phi-4 14B at 32K context limped along at just 1.8 tokens per second, making a 32K conversation a 7-minute ordeal.
TL;DR: Best Local LLMs for 8GB VRAM in 2026
After benchmarking five models on an RTX 3070 with llama.cpp, the verdict is clear: Qwen3.5-9B (Q4_K_M) is the best local LLM for 8GB VRAM by a significant margin. It is faster, smarter, and the only model that runs entirely in GPU memory at all four tested context sizes including 32K. As per our empirical testing, it is even capable of operating at a massive 200K+ context window with minimal performance penalty on 8GB cards. GLM-4.6V-Flash matches it at shorter contexts but hits a wall at 32K. Everything else involves a serious performance compromise.
- Winner: Qwen3.5-9B Q4_K_M (Vision-capable) - Full GPU offload at all contexts (4K–32K), 200K+ context capable with minimal penalty, 54–58 t/s decode, 6.96 GB peak at 32K, top intelligence index in its weight class, and the best frontend code in the practical test.
- Runner-up: GLM-4.6V-Flash Q4_K_M (Vision-capable) - Slightly faster prefill than Qwen at short contexts (2,376 vs 1,932 t/s at 4K), full GPU up to 16K, but decode speed collapses 70% to 17.4 t/s at 32K as it spills 4 layers to CPU.
- Nemotron Nano 12B v2 Q4_K_M - Technically fits (7.75 GB at 32K) but always partially CPU-offloaded, delivering 6.6–10.9 t/s. Choose if you need the higher intelligence ceiling and can tolerate slower output.
- Gemma 3 12B Q4_K_M (Vision-capable) - Heavy partial offload at all contexts (10.02 GB total at 32K), 4.3–8.6 t/s decode. A functional fallback if you specifically need Google's architecture.
- Phi-4 14B Reasoning Plus Q4_K_M - Included purely as a hardware scaling reference point. Released roughly a year ago, this older 14B parameter architecture is deeply CPU-bound on an 8GB card, bottlenecking at a near-unusable 1.8 t/s at 32K context.
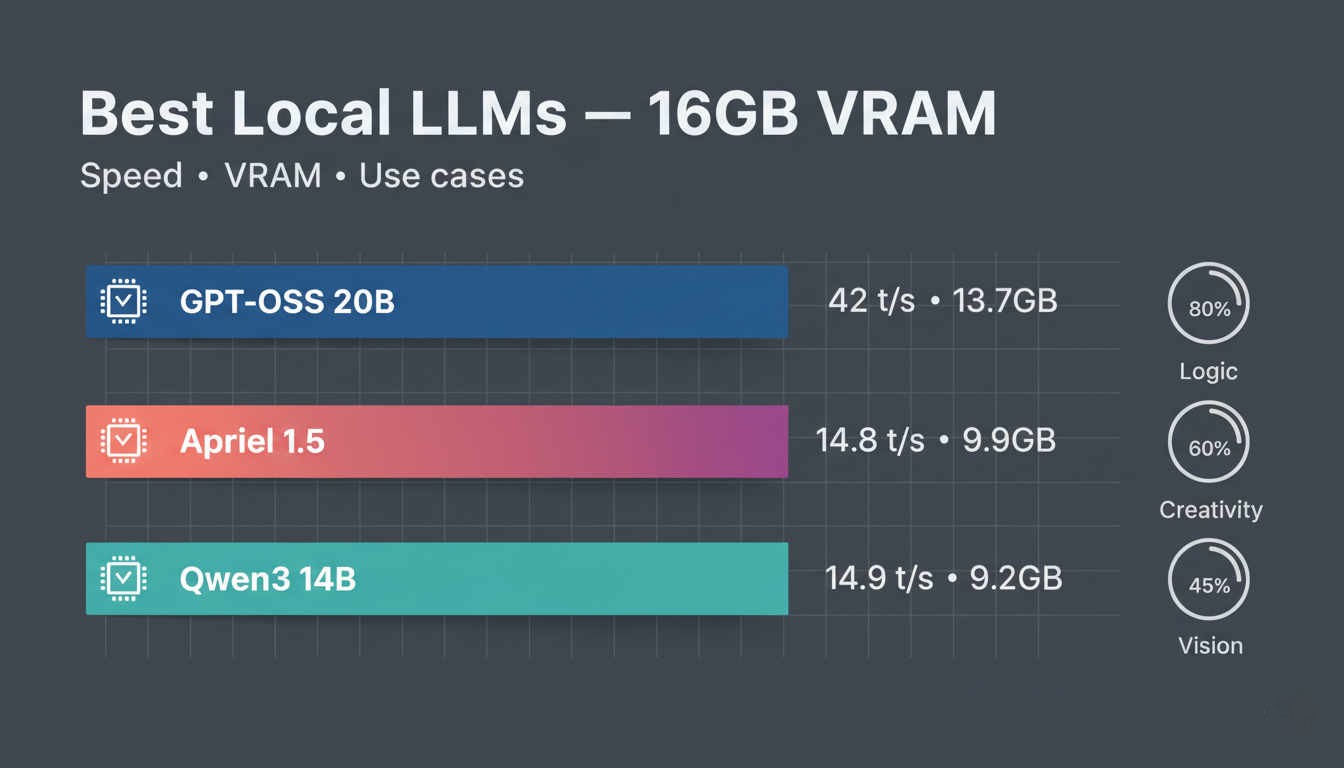
Choosing your GPU? See our complete GPU comparison for LLM inference. Running 16GB VRAM? Check best local LLMs for 16GB VRAM where larger MoE models open up.
Intelligence Benchmarks for 8GB VRAM Models
Before testing hardware performance, it is worth establishing which models are actually intelligent enough to be worth running. The chart below compares our full 15-model shortlist (curated from the Artificial Analysis leaderboard) across three composite indices: overall intelligence, coding, and math. We ultimately benchmarked the five models that achieved the best coverage of the 7B–14B VRAM-safe range.
AI Model Performance Comparison
| Model Name | Creator | Release Date | Artificial Analysis Intelligence Index | Artificial Analysis Coding Index | Artificial Analysis Math Index | MMLU-Pro (Reasoning & Knowledge) | GPQA Diamond (Scientific Reasoning) | Humanity's Last Exam (HLLE) | LiveCodeBench (Coding) | SciCode (Scientific Coding) | Math 500 | AIME (Competition Math) | AIME 2025 | IFBench (Instruction Following) | LCR (Logical & Common-sense Reasoning) | TerminalBench Hard | TAU2 (Tool-use & Agentic) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3.5 9B (Reasoning) | Alibaba | N/A | 32.4% | 25.3% | N/A | N/A | 80.6% | 13.3% | N/A | 27.5% | N/A | N/A | N/A | 66.7% | 59.0% | 24.2% | 86.8% |
| Qwen3.5 9B (Non-reasoning) | Alibaba | N/A | 27.3% | 21.4% | N/A | N/A | 78.6% | 8.6% | N/A | 27.7% | N/A | N/A | N/A | 37.8% | 38.0% | 18.2% | 85.1% |
| GLM-4.6V (Reasoning) | Zhipu AI | N/A | 23.4% | 19.7% | 85.3% | 79.9% | 71.9% | 8.9% | 16.0% | 30.4% | N/A | N/A | 85.3% | 30.1% | 40.3% | 14.4% | 31.6% |
| Motif-2 12.7B Reasoning | Motif | N/A | 19.1% | 11.9% | 80.3% | 79.6% | 69.5% | 8.2% | 65.1% | 28.2% | N/A | N/A | 80.3% | 57.0% | 13.0% | 3.8% | 46.5% |
| GLM-4.6V (Non-reasoning) | Zhipu AI | N/A | 17.1% | 11.1% | 26.3% | 75.2% | 56.6% | 3.7% | 41.1% | 27.2% | N/A | N/A | 26.3% | 27.9% | 12.3% | 3.0% | 30.7% |
| DeepSeek R1 0528 Qwen3 8B | DeepSeek | N/A | 16.4% | 7.8% | 63.7% | 73.9% | 61.2% | 5.6% | 51.3% | 20.4% | 93.2% | 65.0% | 63.7% | 19.9% | 13.0% | 1.5% | 0.0% |
| Falcon-H1R 7B | TII | N/A | 15.8% | 9.8% | 80.0% | 72.5% | 66.1% | 10.8% | 72.4% | 24.9% | N/A | N/A | 80.0% | 54.4% | 8.7% | 2.3% | 27.8% |
| Nemotron Nano 12B v2 (Reasoning) | NVIDIA | N/A | 14.9% | 11.8% | 75.0% | 75.9% | 57.2% | 5.3% | 69.4% | 26.2% | N/A | N/A | 75.0% | 31.9% | 40.0% | 4.5% | 21.3% |
| Nemotron Nano 9B V2 (Reasoning) | NVIDIA | N/A | 14.8% | 8.3% | 69.7% | 74.2% | 57.0% | 4.6% | 72.4% | 22.0% | N/A | N/A | 69.7% | 27.6% | 21.0% | 1.5% | 21.9% |
| Nemotron Nano 9B V2 (Non-reasoning) | NVIDIA | N/A | 13.2% | 7.5% | 62.3% | 73.9% | 55.7% | 4.0% | 70.1% | 20.9% | N/A | N/A | 62.3% | 27.1% | 22.7% | 0.8% | 23.4% |
| DeepSeek R1 Distill Llama 8B | DeepSeek | N/A | 12.1% | N/A | 41.3% | 54.3% | 30.2% | 4.2% | 23.3% | 11.9% | 85.3% | 33.3% | 41.3% | 17.6% | 0.0% | N/A | N/A |
| Llama 3.1 Instruct 8B | Meta | N/A | 11.8% | 4.9% | 4.3% | 47.6% | 25.9% | 5.1% | 11.6% | 13.2% | 51.9% | 7.7% | 4.3% | 28.6% | 15.7% | 0.8% | 16.4% |
| Phi-4 14B (Reasoning Plus) | Microsoft | N/A | 10.4% | 11.2% | 18.0% | 71.4% | 57.5% | 4.1% | 23.1% | 26.0% | 81.0% | 14.3% | 18.0% | 23.5% | 0.0% | 3.8% | 0.0% |
| Nemotron Nano 12B v2 (Non-reasoning) | NVIDIA | N/A | 10.1% | 5.9% | 26.7% | 64.9% | 43.9% | 4.5% | 34.5% | 17.6% | N/A | N/A | 26.7% | 25.9% | 17.0% | 0.0% | 19.3% |
| Gemma 3 12B Instruct | N/A | 8.8% | 6.3% | 18.3% | 59.5% | 34.9% | 4.8% | 13.7% | 17.4% | 85.3% | 22.0% | 18.3% | 36.7% | 6.7% | 0.8% | 10.8% |
Key Benchmark Insights
Qwen3.5 Dominates Across the Board
Qwen3.5-9B scores 32.4 on the AA Intelligence Index, a commanding 38% lead over the runner-up GLM-4.6V (23.4). While it currently lacks a published AA Math Index score, its exceptionally high coding and general reasoning metrics suggest it performs on par with, or better than, the larger 12B models in mathematical logic. Alibaba's architecture improvements and training data quality have largely invalidated the "bigger is always smarter" rule in the sub-10B tier.
Larger Models Provide Diminishing Returns
Raw parameter count does not guarantee better reasoning. Despite taking up drastically more VRAM, Gemma 3 12B scores a dismal 8.8 on the intelligence index. Similarly, the older generation Phi-4 14B (included here purely to demonstrate the hardware penalty of running 14B architectures on 8GB VRAM) scores just 10.4. While Microsoft's new Phi-4-reasoning-vision-15B family promises a massive leap in capability, we omitted it here due to a lack of formalized benchmarks. Ultimately, pushing past 9B parameters on an 8GB GPU offers little reward for the massive throughput penalty incurred.
How We Tested: Inference Benchmark Methodology
We built llama.cpp from source to ensure correct CUDA 13.1 compatibility with the RTX 3070 (Compute Capability 8.6).
Hardware Configuration
| GPU | NVIDIA GeForce RTX 3070 |
| GPU VRAM | 8 GB (7,842 MiB usable) |
| Memory Bandwidth | 385.7 GB/s |
| GPU TFLOPs | 19.8 TFLOPS (FP32) |
| CPU | Intel Core i7-8700K (6 cores / 12 threads) |
| System RAM | 64 GB DDR4 |
| Storage | WD_BLACK SN850X NVMe (3,358 MB/s read) |
| CUDA Version | 13.1 |
| llama.cpp build | b1 (0a524f2), GNU 13.3.0 |
Benchmark Settings
Every model was benchmarked with identical core flags to ensure a fair, apples-to-apples comparison. The inference engine was started via the command line like so:
llama-server \
-m /path/to/model.Q4_K_M.gguf \ # The quantized model file (Q4_K_M for all variants)
--fit on \ # Automatically calculates and loads max layers into VRAM
--flash-attn on \ # Enables Flash Attention to reduce KV cache memory usage
-c 4096 \ # Context window size (tested at 4096, 8192, 16384, and 32768)A note on Ollama and LM Studio: llama.cpp is the inference engine that both Ollama and LM Studio use under the hood. The VRAM consumption figures in this article apply directly to both frontends. You are running the same binary either way. Inference speed may differ slightly depending on which flags each frontend exposes, but the memory behaviour is consistent.
Watch out for hidden Vision Encoders: If "Vision" is listed under a model's capabilities in LM Studio, or if "Text, Image" are both listed on an official Ollama library page (like ollama.com/library/qwen3.5), the default download will quietly include massive vision projectors that bloat your VRAM even when you are just performing text inference. To bypass this hardware penalty on 8GB VRAM cards, you must explicitly download text-only GGUFs (for example, by running ollama run hf.co/unsloth/Qwen3.5-9B-GGUF:Q4_K_M to pull directly from Unsloth's stripped-down Hugging Face repository).
The 8GB VRAM Reality: What Actually Fits (Text-Only)
Caveat: No Vision Encoders. All benchmark throughput and memory footprints in this primary llama.cpp test are strictly derived from text-only GGUFs. Real-world multimodal vision models carry an enormous baseline memory footprint that drastically alters what hardware they can fit onto. To see exactly how much VRAM the vision transformer commands (and how it harms prefill speeds), jump to our separate Vision Overhead Benchmark below.
The RTX 3070 has 7,842 MiB of usable VRAM. When llama.cpp loads a text-only model, it allocates three pools: model weights (fixed), KV cache (grows linearly with context), and a compute buffer (fixed overhead for attention calculations). If the sum exceeds your available VRAM, llama.cpp automatically reduces the number of GPU layers, spilling the remainder to system RAM over PCIe, and decode speed tanks accordingly (note that this auto-offload only happens if you use --fit on with llama.cpp, but it is the default behavior in both Ollama and LM Studio).
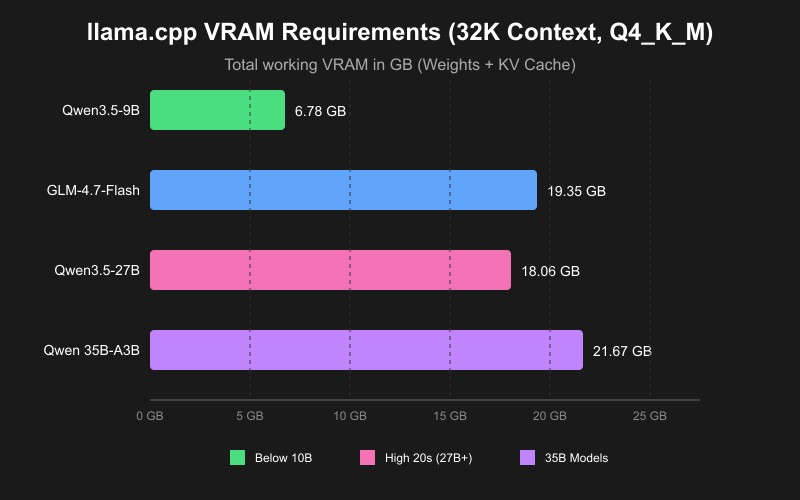
The table below shows the exact VRAM breakdown llama.cpp reported for every text-only model at every tested context size. Total Mem (VRAM + RAM) is the sum of GPU model weights, KV cache, and roughly 500-1500 MiB of variable compute buffer necessary for calculations. Physical VRAM Used includes the CUDA runtime baseline (~200 MiB). Models shown in bold achieved full GPU offload.
| Model | Context | GPU Layers | Weights (GPU) | KV Cache | Total Mem (VRAM + RAM) | Physical VRAM Used |
|---|---|---|---|---|---|---|
| Qwen3.5-9B | 4K | 33/33 | 5,061 MiB | 128 MiB | 6,236 MiB (6.09 GB) | 6,117 MiB |
| Qwen3.5-9B | 8K | 33/33 | 5,061 MiB | 256 MiB | 6,364 MiB (6.21 GB) | 6,245 MiB |
| Qwen3.5-9B | 16K | 33/33 | 5,061 MiB | 512 MiB | 6,612 MiB (6.46 GB) | 6,493 MiB |
| Qwen3.5-9B | 32K | 33/33 | 5,061 MiB | 1,024 MiB | 7,132 MiB (6.96 GB) | 7,013 MiB |
| GLM-4.6V-Flash | 4K | 41/41 | 5,539 MiB | 160 MiB | 6,336 MiB (6.19 GB) | 6,227 MiB |
| GLM-4.6V-Flash | 8K | 41/41 | 5,539 MiB | 320 MiB | 6,496 MiB (6.34 GB) | 6,387 MiB |
| GLM-4.6V-Flash | 16K | 41/41 | 5,539 MiB | 640 MiB | 6,843 MiB (6.68 GB) | 6,735 MiB |
| GLM-4.6V-Flash | 32K | 37/41 GPU, 4 CPU | 4,993 MiB | 1,152 MiB | 7,336 MiB (7.16 GB) | 6,683 MiB |
| Nemotron 12B | 4K | 48/63 GPU, 15 CPU | 5,143 MiB | 80 MiB | 7,510 MiB (7.33 GB) | 6,171 MiB |
| Nemotron 12B | 8K | 48/63 GPU, 15 CPU | 5,143 MiB | 160 MiB | 7,594 MiB (7.42 GB) | 6,255 MiB |
| Nemotron 12B | 16K | 46/63 GPU, 17 CPU | 5,019 MiB | 256 MiB | 7,682 MiB (7.50 GB) | 6,199 MiB |
| Nemotron 12B | 32K | 44/63 GPU, 19 CPU | 4,816 MiB | 512 MiB | 7,938 MiB (7.75 GB) | 6,229 MiB |
| Gemma 3 12B | 4K | 34/49 GPU, 15 CPU | 5,004 MiB | 1,056 MiB | 9,319 MiB (9.10 GB) | 6,805 MiB |
| Gemma 3 12B | 8K | 32/49 GPU, 17 CPU | 4,763 MiB | 1,284 MiB | 9,547 MiB (9.32 GB) | 6,791 MiB |
| Gemma 3 12B | 16K | 30/49 GPU, 19 CPU | 4,506 MiB | 1,504 MiB | 9,767 MiB (9.54 GB) | 6,755 MiB |
| Gemma 3 12B | 32K | 26/49 GPU, 23 CPU | 4,009 MiB | 2,000 MiB | 10,263 MiB (10.02 GB) | 6,753 MiB |
| Phi-4 14B | 4K | 28/41 GPU, 13 CPU | 5,759 MiB | 540 MiB | 9,396 MiB (9.18 GB) | 6,745 MiB |
| Phi-4 14B | 8K | 26/41 GPU, 15 CPU | 5,361 MiB | 1,000 MiB | 9,856 MiB (9.63 GB) | 6,807 MiB |
| Phi-4 14B | 16K | 22/41 GPU, 19 CPU | 4,588 MiB | 1,680 MiB | 10,536 MiB (10.29 GB) | 6,715 MiB |
| Phi-4 14B | 32K | 17/41 GPU, 24 CPU | 3,606 MiB | 2,560 MiB | 11,492 MiB (11.22 GB) | 6,687 MiB |
The table reveals a critical feature in action: Whenever the model and its KV cache require more than 8GB of VRAM, the engine packs the GPU as full as it safely can to circumvent a crash, and dumps the overflow into standard system CPU RAM. This automatic layer splitting is triggered entirely because of the --fit on flag we used in our benchmark settings (which is also the default fail-safe behavior in both Ollama and LM Studio). Without this flag, using -ngl 99 would have resulted in a simple out-of-memory crash on load. "--fit on" rescues usability, but the price is paid in speed: every decode step requires fetching the layers across the PCIe bus, which is what causes that dramatic throughput collapse.
Decode Speed: The Real-World Performance Gap
Decode speed, the rate at which a model generates output tokens, is the metric users feel most directly. A model at 10 t/s produces roughly one word every 0.7 seconds; at 55 t/s, responses stream in faster than most people read. The difference between 55 t/s and 5 t/s is the difference between a snappy coding assistant and an experience that makes you reach for the phone.
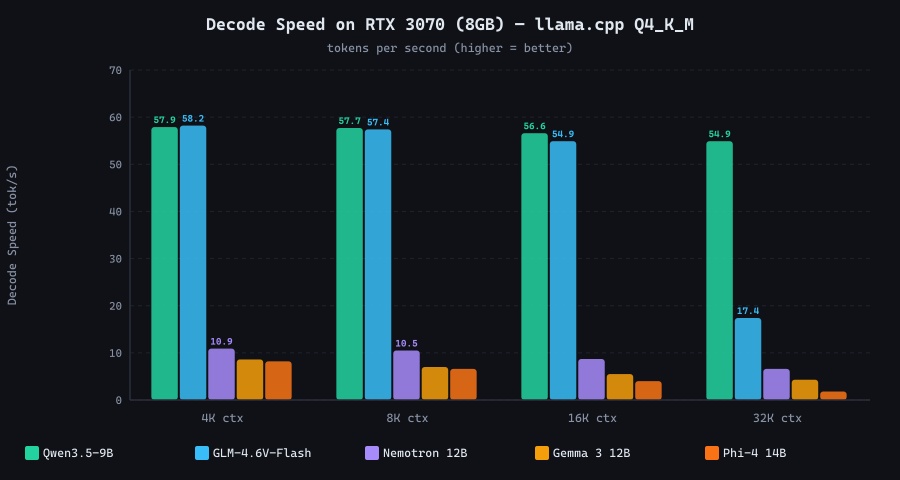
Decode speed (tokens/sec) across all 5 benchmarked models at four context sizes. RTX 3070 · llama.cpp · Q4_K_M · Flash Attention ON
| Model | 4K ctx (t/s) | 8K ctx (t/s) | 16K ctx (t/s) | 32K ctx (t/s) | GPU offload |
|---|---|---|---|---|---|
| Qwen3.5-9B | 57.9 | 57.7 | 56.6 | 54.9 | Full (33/33) |
| GLM-4.6V-Flash | 58.2 | 57.4 | 54.9 | 17.4 ⚠️ | Full → Partial at 32K |
| Nemotron Nano 12B v2 | 10.9 | 10.5 | 8.7 | 6.6 | Partial (48–44/63) |
| Gemma 3 12B | 8.6 | 7.0 | 5.5 | 4.3 | Partial (34–26/49) |
| Phi-4 14B | 8.2 | 6.6 | 4.0 | 1.8 🔴 | Partial (28–17/41) |
The GLM-4.6V-Flash result at 32K deserves special attention. At 16K it matched Qwen3.5-9B almost exactly (54.9 t/s), but at 32K it spilled just 4 out of 41 layers to CPU. This seemingly minor change cut decode speed from 55 t/s to 17.4 t/s. This is the PCIe bottleneck in action: even one or two CPU layers force the decode path to synchronise across the bus on every single token, creating a serialisation penalty that dwarfs the compute cost.
Phi-4 14B at 32K context (1.8 t/s) generated 719 tokens in 422 seconds, just under 7 minutes for a single response. Because it is a reasoning model that typically generates extended chain-of-thought traces, real usage at 32K context on 8GB VRAM is effectively impractical.
The CPU Spill Penalty — and Why Full GPU Offload Is Non-Negotiable
Why does spilling even a few layers to CPU hurt so badly on what is otherwise a fast system? The i7-8700K has 64 GB of DDR4 RAM with roughly 40 GB/s bandwidth. The RTX 3070 has 385.7 GB/s memory bandwidth, nearly 10× faster. During the decode phase, each new token requires reading every model weight that participates in that token's forward pass. If some weights live in GPU memory and others in system RAM, the decode loop must repeatedly transfer data across the PCIe 3.0 x8 interface (theoretical ~8 GB/s effective, far less in practice with latency). The GPU sits idle waiting for RAM. This creates a bottleneck that is architectural. No tuning flag can fix it.
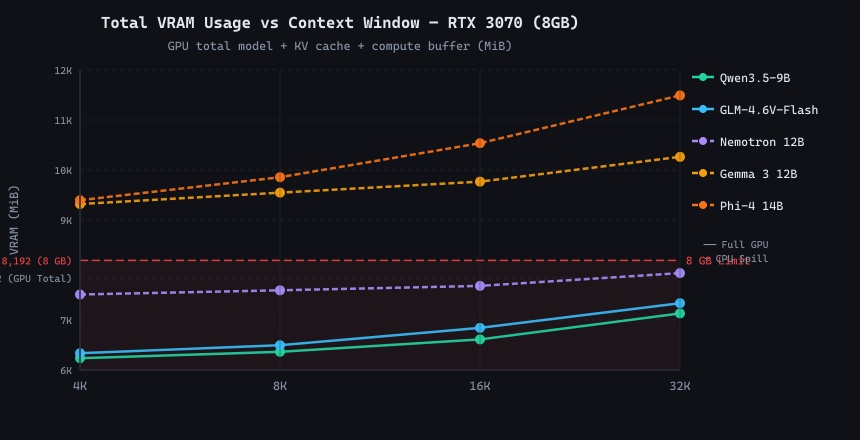
Total VRAM vs context window. The red dashed line marks the RTX 3070's 8 GB limit. Models above the line require CPU spill, and the performance penalty is severe.
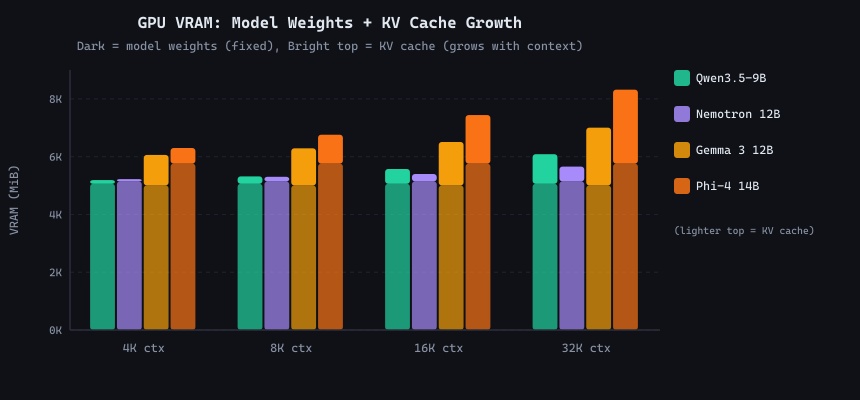
GPU model weights (dark) plus KV cache (bright top segment) per model at each context size. The KV cache doubles with every context doubling, a predictable linear growth.
Prefill Speed: Prompt Processing Rate
Prefill speed (tokens processed per second during prompt ingestion) determines how long you wait before the model begins streaming output. For short prompts it is imperceptible, but for long RAG contexts or document analysis tasks with thousands of input tokens it becomes significant. Unlike decode speed, prefill is parallelisable across GPU and CPU simultaneously, which is why even partially-offloaded models show respectable prefill rates.
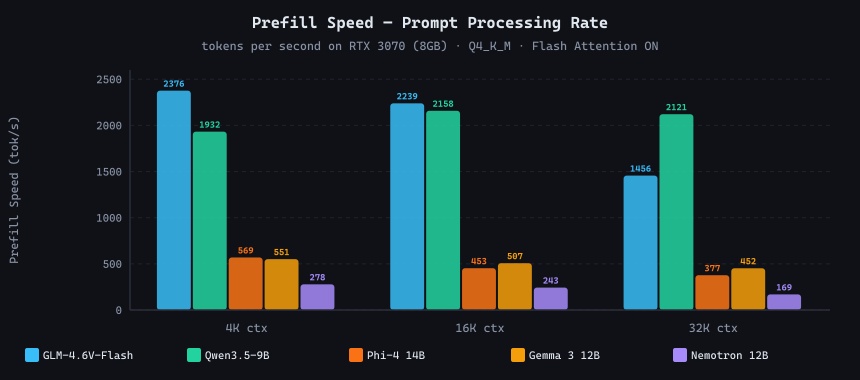
Prefill speed (prompt tokens/sec) at 4K, 16K, and 32K context. Higher means shorter wait before the first generated token appears.
GLM-4.6V-Flash and Qwen3.5-9B both exceed 2,000 t/s at 4K context, meaning a 2,000-token prompt is processed in under one second. The 12B and 14B models land in the 170–570 t/s range at 32K, translating to 20–70 seconds of prefill delay before the model begins replying. For a 12,000-token code review, that is a meaningful UX difference.
Model Deep Dives
Qwen3.5-9B Q4_K_M - The Clear Winner
File size: 5.68 GB | AA Intelligence Index: 32.4 | Peak VRAM (32K): 6.96 GB
Qwen3.5-9B is the only model in this test that fits entirely in GPU memory at every context size tested, including 32K. Its 33 transformer layers load completely onto the RTX 3070, leaving the PCIe bus uninvolved in the decode loop. The result is a consistent 55–58 t/s across all context sizes, barely degrading as context grows because KV cache reads are served from GDDR6 (385.7 GB/s) rather than system DDR4 RAM.
The secret to this "punching above its weight" hardware footprint lies in its efficient hybrid architecture. Qwen3.5 deploys Gated Delta Networks combined with sparse Mixture-of-Experts, allowing it to deliver high-throughput inference with minimal latency and drastically reduced VRAM overhead for the KV cache compared to traditional architectures. As per our empirical testing, Qwen3.5-9B is uniquely capable of operating at a full 200K+ context window with minimal performance penalty even on 8GB cards without KV cache quantization!
The secret to expanding beyond the 32K limits lies in the architecture itself, which reduces the memory cost of increasing context length. To further reduce memory requirements or to improve inference performance with longer contexts, the Qwen engineering team officially states: The Qwen3.5 series maintains near-lossless accuracy under 4-bit weight and KV cache quantization.
Because of this exceptionally resilient architecture, you can aggressively quantize the KV cache (starting with 8-bit, and dropping to 4-bit depending on practical performance) to drastically reduce memory overhead without the severe degradation seen in other models.
The intelligence story is equally strong. Qwen3.5-9B tops the AA Intelligence Index for the sub-10B category with a score of 32.4, decisively outperforming 12B models from NVIDIA and Google. Its reasoning mode supports natively generating chain-of-thought inference via the /think tag. A 32K context window in practice requires 6.96 GB VRAM, leaving just 850 MiB headroom. This is tight but stable on a headless GPU instance.
For 8GB VRAM setups, this is unequivocally the default choice.
GLM-4.6V-Flash Q4_K_M - Fast to 16K, Cliff at 32K
File size: 6.17 GB | AA Intelligence Index: 23.4 | Math Index: 85.3 | Peak VRAM (32K): 7.16 GB total
GLM-4.6V-Flash is the fastest prefill model in this test, reaching 2,376 t/s at 4K context — 23% faster than Qwen3.5-9B at the same context. It also leads on the math index (85.3), making it the best choice for quantitative reasoning tasks among the models tested. At 4K, 8K, and 16K context it matches Qwen3.5-9B closely on decode speed (54.9–58.2 t/s). However, at 32K the KV cache growth pushes total required memory just past what the RTX 3070 can hold with all 41 layers in GPU. llama.cpp spills just 4 layers to CPU, and decode speed collapses 70% to 17.4 t/s. For workflows under 16K context, GLM-4.6V-Flash is an excellent Qwen alternative. For 32K, stick with Qwen3.5-9B.
Nemotron Nano 12B v2 Q4_K_M - High Ceiling, Slow Output
File size: 7.49 GB | AA Intelligence Index: 14.9 | Math Index: 75.0 | Peak VRAM (32K): 7.75 GB total system
Nemotron Nano 12B v2 has an unusually deep architecture at 63 transformer layers, and llama.cpp consistently offloads 15–19 layers to CPU regardless of context size. Physical VRAM Used stays at approximately 6.2 GB flat, but CPU RAM absorbs 2–2.3 GB of weights. Decode ranges from 6.6–10.9 t/s. Its math index of 75.0 makes it worth considering if quantitative reasoning is your priority over generation speed. At 10.9 t/s it is conversational at short contexts; at 32K it drops to 6.6 t/s, roughly one word every 0.7 seconds.
Gemma 3 12B Q4_K_M - Functional but Outclassed
File size: 7.30 GB | AA Intelligence Index: 8.8 | Peak VRAM (32K): 10.02 GB total system
Gemma 3 12B is the most CPU-spilled model in this test. At 32K context, only 26 of its 49 layers remain on GPU (the majority of model weight sits in system RAM), and total system memory reaches 10.02 GB. Decode degrades from 8.6 t/s at 4K to 4.3 t/s at 32K, approximately 2 minutes per 500-token response. Combined with an intelligence index of just 8.8, there is no compelling reason to choose Gemma 3 12B for an 8GB VRAM system. It is a good model on 16GB+ VRAM where all 49 layers fit comfortably in GPU memory.
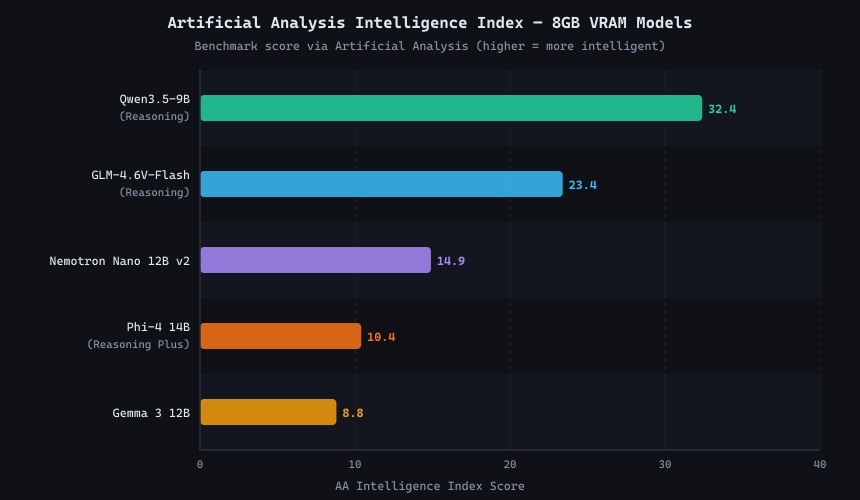
AA Intelligence Index for the 5 benchmarked models. Qwen3.5-9B scores 32.4, nearly 4× Gemma 3 12B (8.8), despite being the physically smallest model tested.
Practical Test: Smart Home Dashboard Challenge
Benchmarks measure what a model knows. Practical tests measure what it can do. We gave each model a single identical prompt: write a complete, functional smart-home dashboard in a single self-contained HTML file with dark mode, sidebar navigation, interactive light buttons, a temperature slider, and a lock/unlock toggle with all CSS and JavaScript inline, and no external libraries. The output had to open directly in a browser with no build step.
We recorded a full video walkthrough of each model's output. Watch to see the quality gap between first and last place:
| Model | UI Polish | Lights | Slider | Lock | Notable Feature | Issues | Score |
|---|---|---|---|---|---|---|---|
| Qwen3.5-9B | Excellent | 3 rooms, icon+label, glow on active | Live °C display, color-coded by temp range | Proper CSS toggle switch with animation | Inline SVGs, CSS variables, card hover lift, user profile header, grid layout | None found | ★★★★★ |
| Phi-4 14B | Good | 1 button, toggles on/off text | Functional, live °C label | Checkbox + text span (unconventional) | Consolidated status panel - most informative display (all states at once) | Gold hover too subtle on dark bg | ★★★★☆ |
| GLM-4.6V-Flash | Good | 3 rooms, yellow on active | Custom styled, yellow thumb | Button toggles green/red with text | 3 independent light buttons, terminal aesthetic | Missing DOCTYPE; lock UX inverted (green = locked) | ★★★☆☆ |
| Gemma 3 12B | Adequate | 2 rooms, yellow on active | Functional, unstyled | Button toggles red when locked | Clean, readable code structure | No live slider readout; minimal visual feedback | ★★★☆☆ |
| Nemotron 12B | Basic | 1 button only | Unstyled, no readout | Div rotation animation, no state text | — | FontAwesome not loaded (broken icons throughout) | ★★☆☆☆ |
Qwen3.5-9B is the clear winner for frontend coding. Despite being the smallest model tested (9B parameters), it produced the most complete, polished, and bug-free output. It utilizes inline SVGs for icons, a proper CSS toggle switch with animation, a colour-coded temperature display that shifts between warning states, card hover animations, a user profile header, and a full CSS variable design system. Phi-4 14B earns second place with the most informative status display, but is noticeably simpler in visual design. GLM-4.6V-Flash and Gemma 3 12B are roughly tied. Both are functional with minor issues. Nemotron is the weakest entry, shipping with a broken FontAwesome dependency, just one light button, and no status text on the lock toggle. The ranking confirms that for single-file frontend coding tasks, Qwen3.5-9B punches well above its weight class, outperforming models with 1.3–1.6× more parameters.
Quick Start: Run Qwen3.5-9B on Google Colab
If you want to test the official multimodal Qwen3.5-9B (which includes vision encoders) but don't have enough local VRAM, you can easily run it on a free Google Colab T4 GPU instance. Just drop these commands into sequential notebook cells:
Cell 1: Install Dependencies
!sudo apt-get update
!sudo apt-get install zstdCell 2: Install Ollama
!curl -fsSL https://ollama.com/install.sh | shCell 3: Start the Backend Server
# Run in the background so Colab doesn't block
!nohup ollama serve &Cell 4: Pull the Multimodal Model
# This downloads the official tag, which includes the vision projectors
!ollama pull qwen3.5:9bCell 5: Run Inference
# The --verbose flag prints throughput tokens/sec after generating
!ollama run qwen3.5:9b --verbose "How are you"For precise VRAM estimates for your specific model and context window, use our interactive VRAM calculator. For a full explanation of how context length affects memory, see our llama.cpp VRAM requirements guide.
Special Test: The Hidden Memory Cost of Vision Encoders
A common point of confusion is the VRAM difference between a standard text-only model and its multimodal (vision) equivalent. To measure this exactly, we ran a secondary benchmark using Ollama on a 16GB Tesla T4 GPU. We compared a strictly text-only unsloth compile of Qwen3.5-9B-Q4_K_M against the official multimodal qwen3.5:9b tag from the Ollama registry.
The results show that the vision encoder and its projector layers consume an enormous amount of VRAM simply by existing in memory, even when only processing text prompts.
| Model Variant (Q4_K_M) | Context | Physical VRAM Used | Prefill Speed | Decode Speed |
|---|---|---|---|---|
| Text-Only (Unsloth) | 4,096 | 6,549 MiB | 751.5 t/s | 27.9 t/s |
| Multimodal (Ollama) | 4,096 | 7,929 MiB | 738.2 t/s | 25.9 t/s |
| Text-Only (Unsloth) | 8,192 | 6,685 MiB | 757.5 t/s | 26.3 t/s |
| Multimodal (Ollama) | 8,192 | 8,089 MiB | 712.7 t/s | 25.4 t/s |
| Text-Only (Unsloth) | 32,768 | 7,501 MiB | 675.0 t/s | 24.8 t/s |
| Multimodal (Ollama) | 32,768 | 9,077 MiB | 681.7 t/s | 25.1 t/s |
The vision encoder adds a massive 1.38 GB (1,380 MiB) of fixed VRAM overhead across all context sizes. Furthermore, passing an actual image through the multimodal model at a 4K context dropped the prefill speed from 738 t/s to 569 t/s, and nearly doubled the Time to First Token (from 3.8s to 6.7s) as the vision transformer processed the image patches. If your workflow does not strictly require image analysis, downloading text-only GGUFs saves a massive amount of VRAM, especially on an 8GB card.
Conclusion
The 8GB VRAM tier is genuinely capable for local LLM inference in 2026, but it demands model selection discipline. The RTX 3070 delivers 55+ tokens per second on the right model. On the wrong model pushed past its memory limit, it degrades to 1.8 tokens per second: a 30× performance collapse caused entirely by PCIe bandwidth constraints between GPU and system RAM.
- Always check total VRAM requirement, not just file size. A 7.5 GB GGUF file does not mean 7.5 GB of VRAM. The FP16 KV cache at 32K context adds another 1–2 GB depending on architecture.
- Full GPU offload is non-negotiable on 8GB. Even 4 layers spilling to CPU (GLM-4.6V-Flash at 32K) cuts decode speed by 70%. Either the model fits entirely in VRAM, or you accept a severe performance penalty.
- Stick to Q4_K_M for 8GB cards. It provides the perfect balance of model intelligence and memory footprint, allowing Qwen3.5-9B to comfortably run a 32K context inside 6.96 GB VRAM.
- Qwen3.5-9B is the benchmark to beat until a sub-10B model surpasses it on the AA Intelligence Index while maintaining full GPU offload at 32K on 8GB VRAM.
One area where this class of models genuinely shines, and which is easy to overlook, is long-document workflows. Tasks like RAG (Retrieval-Augmented Generation), chatting with PDFs, summarising research papers, and reviewing lengthy codebases are all excellent fits for Qwen3.5-9B on an 8GB card. Its ability to operate at 200K+ context fully in GPU memory means it can hold an entire document in its attention window and reason over it at 55+ tokens per second. For knowledge-base Q&A, local document assistants, and private research tools, this model-hardware combination is arguably the best price-to-capability option available in 2026.
On the coding front, 8GB models are excellent for generating code snippets, short utility functions, boilerplate scaffolding, and explaining existing code. However, if your goal is true agentic coding - multi-file edits, autonomous debugging loops, architectural refactoring, or long-horizon tool-use, this weight class will hit its intelligence ceiling. Tasks of that complexity benefit significantly from 20B+ parameter models that can maintain coherent reasoning across very large contexts and multi-step plans. We have covered the best options for that tier in our Best Local LLMs for 24GB VRAM guide and the llama.cpp VRAM requirements guide, which maps model sizes to hardware configurations across the full range.
Frequently Asked Questions
What is the best local LLM for 8GB VRAM in 2026?
Qwen3.5-9B (Q4_K_M) is the clear winner. In our RTX 3070 benchmarks it delivered 54–58 tokens per second across all context sizes, fits entirely in GPU memory at 32K context (6.96 GB), and topped the Artificial Analysis Intelligence Index for sub-10B models. GLM-4.6V-Flash is a strong alternative at contexts up to 16K, but its decode speed collapses from 55 to 17.4 t/s at 32K when it spills to system RAM.
How much VRAM does a 9B model actually use with llama.cpp?
With Q4_K_M quantization, Qwen3.5-9B uses approximately 6.09 GB at 4K context, 6.21 GB at 8K, 6.46 GB at 16K, and 6.96 GB at 32K on the RTX 3070. Model weights (5.06 GB on GPU) stay fixed; only the KV cache grows linearly, doubling every time the context size doubles.
Can I run a 12B model on 8GB VRAM?
Yes, but performance suffers significantly. Nemotron 12B and Gemma 3 12B both ran on our RTX 3070, but llama.cpp spilled 15–23 layers to system RAM. Decode speeds dropped to 4–11 t/s versus 55–58 t/s for fully-offloaded 9B models. A 9B model at full GPU speed produces substantially more useful output per hour than a 12B model throttled by PCIe bandwidth.
What context length can I use with 8GB VRAM?
For a standard 9B model running Q4_K_M (with default FP16 KV Cache), 32K context is comfortably achievable, as our benchmarks confirmed 6.96 GB at 32K for Qwen3.5-9B. For larger 12B models, practical context is limited to 4K–16K on 8GB VRAM before forcing a massive CPU-spill penalty.
However, if you are running Qwen3.5 specifically, their engineering team has officially confirmed the model maintains "near-lossless accuracy" under aggressive KV cache quantization. By dropping your KV cache to 8-bit or 4-bit precision, you can safely scale Qwen3.5 up to 200K+ context windows natively inside 8GB VRAM. Use our interactive VRAM calculator to estimate your specific configuration and quantization levels.
What is the best vllm, llama.cpp, LM Studio and Ollama model for 8GB VRAM chatbot or assistant?
Qwen3.5-9B (Q4_K_M) is the best model for an 8GB VRAM chatbot or local assistant, and it works perfectly with vllm, llama.cpp, LM Studio, and Ollama. It delivers 55+ tokens per second fully in GPU memory, which translates to a smooth, near-instant conversational experience on a single RTX 3070. Its 32K+ context window means it can hold a long multi-turn conversation without losing earlier context, and it supports a /think reasoning mode for harder queries. GLM-4.6V-Flash is a strong second choice for shorter conversations. Both models run identically in Ollama, LM Studio, or directly via llama.cpp since all three use the same underlying inference engine.
What quantization should I use for 8GB VRAM?
Q4_K_M is the recommended baseline. It compresses a 9B model to approximately 5 GB while retaining around 95% of capability. This enables full GPU offload for deep long-context reasoning workflows. For a deeper explanation of the math, see our quantization explained guide.