TL;DR: How to Fix Cline Ollama Timeout Issues
- Increase Request Timeout: Change from default 30 seconds to 90-120 seconds for 13-14B models on mid-range hardware (8GB VRAM)
- Enable Compact Prompt: Reduces prompt size for faster processing, disabling some advanced features but ideal for local models
- Check Model Loading: Ensure your model is loaded in Ollama (
ollama ps) before use - Hardware Matters: 7B models on decent hardware work with 60s timeout; 30B+ models may need 180s+. Use our interactive VRAM calculator to calculate precise VRAM requirements for local models
If you're here, you've probably just encountered this frustrating error message while trying to use Cline with your local Ollama models:
API Request Failed
Ollama request timed out after 30 seconds
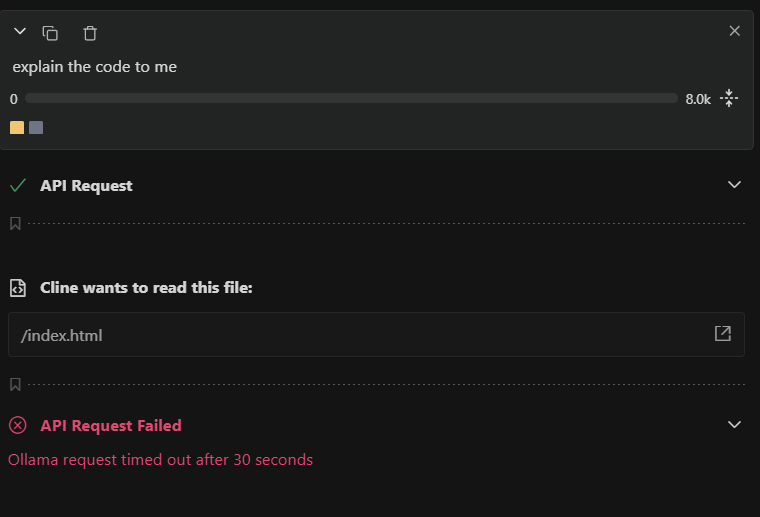
I know the feeling. After spending time setting up Ollama, downloading a 14B parameter model, and getting everything configured, the last thing you want is a timeout error ruining your coding flow. Let me share my experience and the solution that actually worked.
My Setup and The Problem
I'm running Qwen 3 14B on my machine with the following specs:
GPU: RTX 4060 (8GB VRAM)
CPU: 12th Gen Intel Core i7-12700H
RAM: 16GB
Model: qwen3:14b (11GB size)
Here's what my Ollama status looked like:
PS C:\Users\alok-pc> ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
qwen3:14b bdbd181c33f2 11 GB 49%/51% CPU/GPU 8000 4 minutes from now
The model was working perfectly fine when I tested it directly:
- Running
ollama run qwen3:14bin the terminal? Worked flawlessly. - Using the Ollama GUI app? No issues at all.
But the moment I integrated it with Cline and asked it to do something simple, like "explain this code to me" for a basic HTML snake game - boom! Timeout error. For guidance on choosing the right local models for coding tasks, check our comprehensive analysis of coding-optimized models.
Why Does This Happen? Understanding the Real Issue
At first, I was confused. The model was responding fine everywhere else, so why was Cline different?
After some digging and testing, I realized what was happening. When you use Ollama directly in the terminal or GUI, you're typically sending simple, standalone prompts. But when Cline sends a request to Ollama, it's not just sending your question. It's also including:
- Cline's system prompts (instructions on how to behave as a coding assistant)
- Environment details (your VS Code workspace info)
- Directory structure (files and folders in your project)
- File contents (the actual code you're working with)
- Tool definitions (available commands like
read_file,write_file, etc.) - Conversation history (previous messages in the chat)
All of this adds up to a much larger context than a simple terminal prompt. For a 14B parameter model running on mixed CPU/GPU, this significantly increases the "time to first token" (TTFT)-the time it takes for the model to start generating a response.
The default 30-second timeout in Cline simply wasn't enough for my model to process all that context and start responding.
The Solution: Adjusting the Request Timeout
The fix is actually quite simple once you know what to do. You need to increase Cline's request timeout setting. Here's how:
Step 1: Open Cline Settings
In VS Code, click on the Cline icon in your sidebar, then click the gear icon (⚙️) to access settings.
Step 2: Find the API Request Timeout Setting
Scroll down until you find the "Request Timeout" option. By default, it's set to 30000 milliseconds (30 seconds).
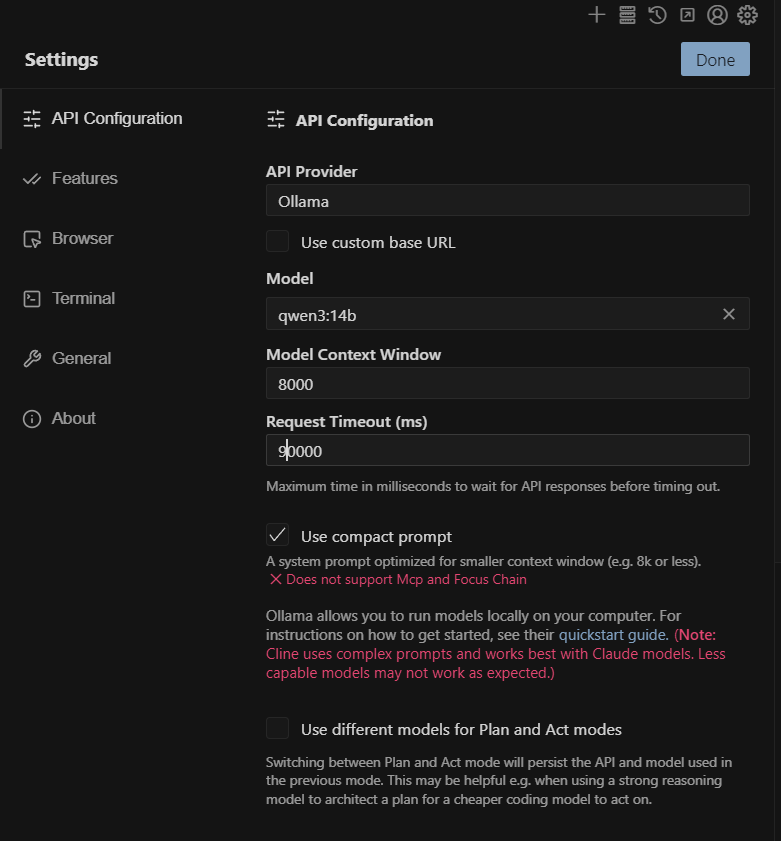
Step 3: Increase the Timeout Value
I changed mine to 90000 (90 seconds), and it worked perfectly. Depending on your hardware and model size, you might need more or less time:
- For 7B models on decent hardware: 60000 (60 seconds) should be enough
- For 13-14B models on mid-range hardware: 90000-120000 (90-120 seconds)
- For 30B+ models or slower hardware: 180000+ (180 seconds or more)
Step 4: Enable Compact Prompt (Important!)
This is a crucial step that many people miss. In Cline's settings, make sure to enable "Use Compact Prompt".
This option is described as: "A system prompt optimized for smaller context windows (e.g. 8k or less). Does not support MCP and Focus Chain."
While my model has an 8000 token context window, enabling this setting significantly reduced the prompt size, making it faster for the model to process. The trade-off is that you lose some advanced features (MCP and Focus Chain), but for local models, this is usually worth it.
Results: It Actually Works!
After making these changes, Cline with Qwen 3 14B worked beautifully:
- ✅ Plan mode: The model could analyze my requests and create execution plans
- ✅ Act mode: It successfully used tools to read, create, and edit files
- ✅ No more timeouts: Even complex requests completed without issues
- ✅ Proper tool usage: File operations, code searches, everything worked as expected
The first response took longer as expected (that's the nature of local models), but it was well within the 90-second timeout, and subsequent responses were much faster thanks to context caching.
Common Issues and Additional Tips
Based on my research across Reddit and GitHub issues, here are other common problems people face and their solutions:
Still timing out even after increasing timeout?
- Check if your model is actually loaded in Ollama (
ollama ps) - Try restarting VS Code after changing settings
- Ensure you have enough RAM available (close other applications)
- Consider using a smaller model (7B instead of 14B)
- Make sure "Use Compact Prompt" is enabled
- Check if your model is actually loaded in Ollama (
Model unloads between requests?
- Ollama unloads models after 5 minutes of inactivity by default. You can change this:
# Keep model loaded for 1 hour ollama run qwen3:14b --keepalive 1h # Keep model loaded indefinitely ollama run qwen3:14b --keepalive -1 - Or set it in your Ollama configuration file (Modelfile).
- Ollama unloads models after 5 minutes of inactivity by default. You can change this:
First request is slow, but subsequent ones are fine?
- This is normal! The first request has to load the model and process the full context. Subsequent requests benefit from:
- The model already being loaded in memory
- Context caching (previous conversation is cached)
- Prompt caching (Ollama caches common prompt patterns)
- This is normal! The first request has to load the model and process the full context. Subsequent requests benefit from:
Running out of VRAM?
- With 8GB VRAM, you're right on the edge for 14B models. If you're experiencing crashes or extreme slowdowns, check out our guide on optimizing local models for 8GB VRAM systems for detailed recommendations and benchmarks.
- Check your GPU utilization with
nvidia-smior Task Manager - Consider using a quantized version (Q4 or Q5 instead of Q6 or Q8)
- Try a smaller model like 7B
- Adjust the
num_gpuparameter in Ollama to offload more layers to CPU
- Check your GPU utilization with
- With 8GB VRAM, you're right on the edge for 14B models. If you're experiencing crashes or extreme slowdowns, check out our guide on optimizing local models for 8GB VRAM systems for detailed recommendations and benchmarks.
Works in terminal but not in Cline after updates?
- Some users reported this after Cline updates. If you're experiencing this:
- Restart VS Code completely (not just reload window)
- Roll back to a previous Cline version to test
- Check the Cline GitHub issues for your specific version
- Clear VS Code's extension cache
- Some users reported this after Cline updates. If you're experiencing this:
Hardware Optimization Tips
Since I'm running on a laptop with an RTX 4060 (8GB VRAM), here's what I learned about optimization:
- GPU/CPU Split: My Ollama shows 49%/51% CPU/GPU, which means layers are being offloaded to CPU. This is actually fine for 14B models on 8GB VRAM. Don't worry if you see this split.
- Temperature Management: Long inference sessions will heat up your laptop. Make sure you have:
- Good ventilation
- A laptop cooling pad (optional but helpful)
- Power plugged in (don't run on battery)
- Memory Management: Close unnecessary applications when using Cline with local models. Chrome tabs, Discord, and other apps can eat into your available RAM, forcing more swapping and slowing down inference.
Conclusion
The "Ollama request timed out after 30 seconds" error in Cline is frustrating, but it's not a dealbreaker. With a simple timeout adjustment and the compact prompt enabled, local models can work wonderfully with Cline.
Yes, they're slower than cloud APIs. Yes, you need decent hardware. But the privacy, cost savings, and satisfaction of running a capable AI assistant entirely on your own machine? Totally worth it.
If you're struggling with this issue, try the 90-second timeout setting and enable compact prompt. If that doesn't work, start experimenting with higher values or consider a smaller model. Every hardware configuration is different, and it might take a bit of trial and error to find your sweet spot.
Happy coding! 🚀
FAQ
Why does Cline timeout with Ollama when the model works fine elsewhere?
Cline sends much larger contexts than simple terminal prompts, including system instructions, environment details, directory structures, and conversation history. This increases 'time to first token' (TTFT) on local models, especially larger ones running on mixed CPU/GPU offload.
What's the right timeout setting for my hardware and model?
For 7B models on decent hardware: 60 seconds. For 13-14B models on mid-range hardware (8GB VRAM): 90-120 seconds. For 30B+ or slower hardware: 180+ seconds. Start with 90000ms (90 seconds) and adjust based on your setup.
What does 'Use Compact Prompt' do and should I enable it?
It optimizes Cline's system prompt for smaller context windows (≤8k tokens). Enable it for local models to reduce prompt size and speed up processing, though it disables MCP and Focus Chain features.
My model keeps unloading between requests - what can I do?
Use ollama run qwen3:14b --keepalive 1h to keep it loaded for an hour, or --keepalive -1 for indefinite loading. Check if Ollama is actually running the model with ollama ps before using Cline.
How do I fix 'Ollama request timed out after 30 seconds' in Cline?
To fix the Ollama timeout error in Cline, increase the request timeout value in Cline's settings. Open VS Code, click the Cline icon, then the gear icon to access settings. Find 'Request Timeout' and change it from 30000 to 90000 (90 seconds) or higher depending on your model size. For 7B models use 60 seconds, for 13-14B models use 90-120 seconds, and for 30B+ models use 180+ seconds. Additionally, enable 'Use Compact Prompt' in settings to optimize for smaller context windows and reduce processing time.
Why does Ollama work in terminal but timeout in Cline?
Ollama works fine in the terminal but times out in Cline because of the difference in context size. When you use Ollama directly via terminal, you're sending simple, standalone prompts. However, Cline sends much larger requests that include system prompts, environment details, directory structure, file contents, tool definitions, and conversation history. This significantly increases the 'time to first token' (TTFT), causing the model to exceed the default 30-second timeout. Larger context requires more processing time, especially for 13B+ parameter models running on consumer hardware with limited VRAM.
What is the best timeout setting for Ollama with Cline on RTX 4060?
For an RTX 4060 8GB with a 13-14B parameter model like Qwen 3 14B, a timeout setting of 90000 milliseconds (90 seconds) works well. If you're still experiencing timeouts, increase it to 120000 (120 seconds). For smaller 7B models on the same hardware, 60000 milliseconds (60 seconds) should be sufficient. Make sure to enable 'Use Compact Prompt' in Cline settings and keep your model loaded with ollama run modelname --keepalive 1h to avoid reload delays. Monitor your first request response time and adjust the timeout to be 20-30 seconds longer than your typical TTFT.