How to Increase Context Length of Local LLMs in Ollama
Context window size is a critical parameter when working with language models in Ollama. It determines how much previous conversation or text the model can consider when generating responses. This article clarifies how to check, set, and manage context window sizes in Ollama, addressing common points of confusion.
Ollama Default Context Window Size
By default, Ollama uses a context window size of 4096 tokens for most models. The gpt-oss model has a default context window size of 8192 tokens. However, these defaults can be overridden as needed.
How to Check Context Window Size in Ollama
There are two important context-related values to understand:
- Model's Maximum Context Length: The maximum context length the model can support, determined by its architecture.
- Current Context Length: The actual context length being used in the current session.
Checking Model's Maximum Context Length in Ollama
To see the maximum context length a model can support:
ollama show <model_name>
For example, to check the context length for qwen3:8b:
ollama show qwen3:8b
This will display information including:
context length 40960
embedding length 4096
The "context length" value shows the maximum context window size the model can support, not what's currently being used.
Checking Current Context Length in Ollama
To see the actual context length being used in a running model:
ollama ps
This shows currently loaded models with their actual context length:
NAME ID SIZE PROCESSOR CONTEXT UNTIL
qwen3:8b abc123def456 6.5 GB 100% GPU 8192 4 minutes from now
The "CONTEXT" column shows the actual context length being used for the running model.
Please note: that this function will print the details only if the model is loaded in the memory. You can do this by running "ollama run
Setting Context Window Size
There are several ways to set the context window size in Ollama:
Using the Ollama GUI (Windows and macOS)
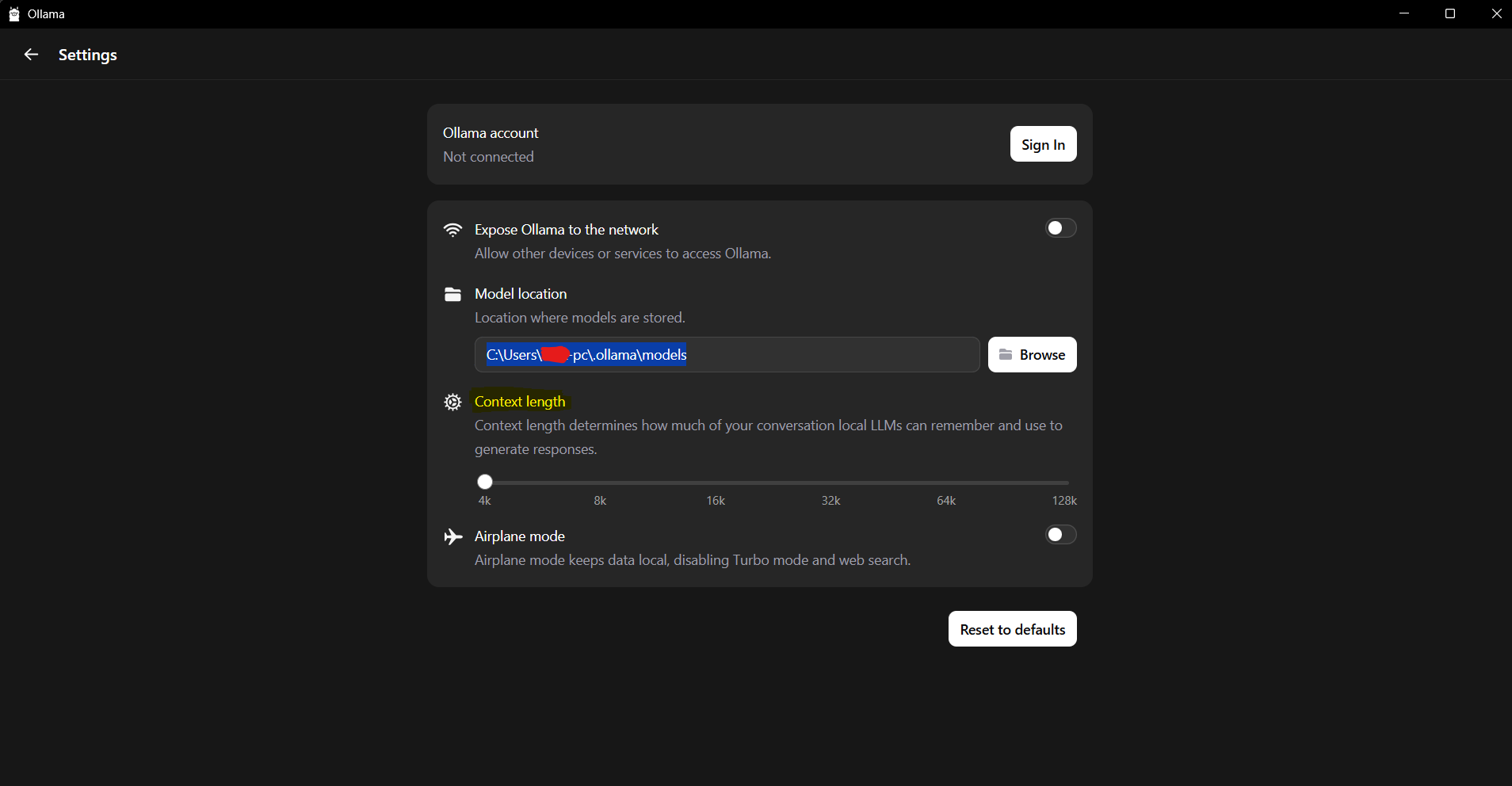
- Open the Ollama application
- Go to Settings
- Adjust the context window size setting
- Restart Ollama for the changes to take effect
Using Environment Variables
To set the default context window for all models:
OLLAMA_CONTEXT_LENGTH=8192 ollama serve
Using the CLI
When running a model interactively:
/set parameter num_ctx 8192
Using the API
When making API calls:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Why is the sky blue?",
"options": {
"num_ctx": 8192
}
}'
Persisting Context Window Settings
Changes made with /set parameter num_ctx during an interactive session are temporary and will not persist after the model is unloaded from memory. To make permanent changes to the context window size, you need to create a new custom model with your desired configuration. This ensures that every time you run your model, it will use the larger context length without having to manually set it each time.
Step 1: Create a New, Simple Modelfile
Create a new Modfile in any directory (Wherever you can run terminal commands). You can name it something different to avoid confusion, for example, Modelfile.custom.
In this new file, you only need two lines:
FROM qwen3:8b: This tells Ollama to use your existing qwen3:8b model as the starting point.PARAMETER num_ctx <value>: This is where you set the new context length.
For example, let's say you want to set the context length to 8192 tokens. Create a file named Modelfile.custom and put the following content inside it:
# My custom Modelfile to increase context length
FROM qwen3:8b
# Set the context window size (e.g., 4096, 8192, 16384, etc.)
PARAMETER num_ctx 8192
Step 2: Create a New Model with Your Custom Modelfile
Now, open your terminal (PowerShell or Command Prompt) in the same directory where you saved Modelfile.custom.
Run the ollama create command. You need to give your new, modified model a new name. For example, let's call it qwen3:8b-8k.
ollama create qwen3:8b-8k -f Modelfile.custom
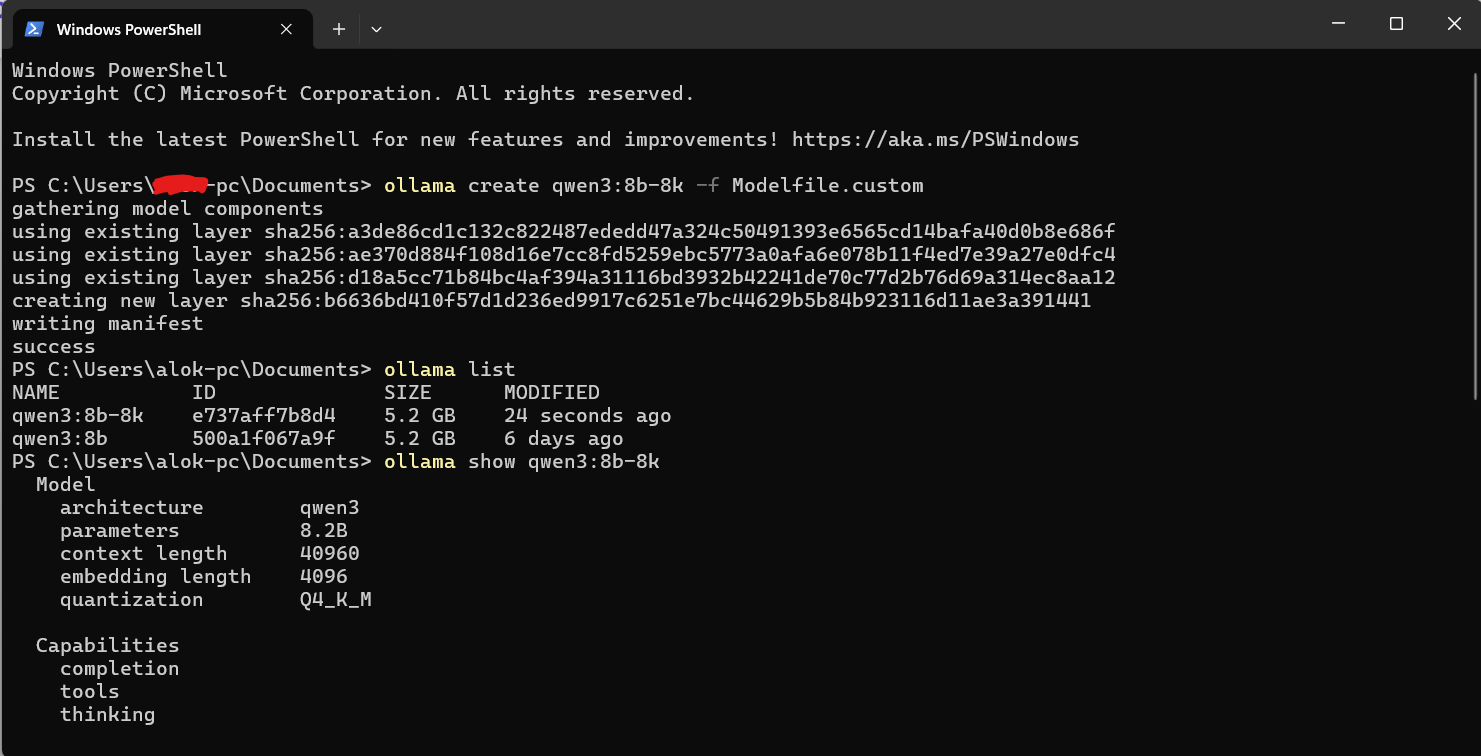
Let's break down that command:
ollama create: The command to build a new model.qwen3:8b-8k: The new name for your model with the larger context.-f Modelfile.custom: This flag tells Ollama to use the fileModelfile.customfor the instructions.
Ollama will quickly create a new model layer. It will not re-download the 5.2 GB model; it just applies your new configuration on top of the existing one.
Step 3: Verify Your Changes
You can now verify that your new model has the updated context length.
List your models:
ollama list

You will now see both the original and your new custom model:
NAME ID SIZE MODIFIED
qwen3:8b 500a1f067a9f 5.2 GB 6 days ago
qwen3:8b-8k ... 5.2 GB seconds ago
Show the new model's information:
ollama show qwen3:8b-8k
This time, the output will include the num_ctx parameter you set!
...
PARAMETER num_ctx 8192
...
Step 4: Use Your New Model
You can now run your new model with its extended context window:
ollama run qwen3:8b-8k
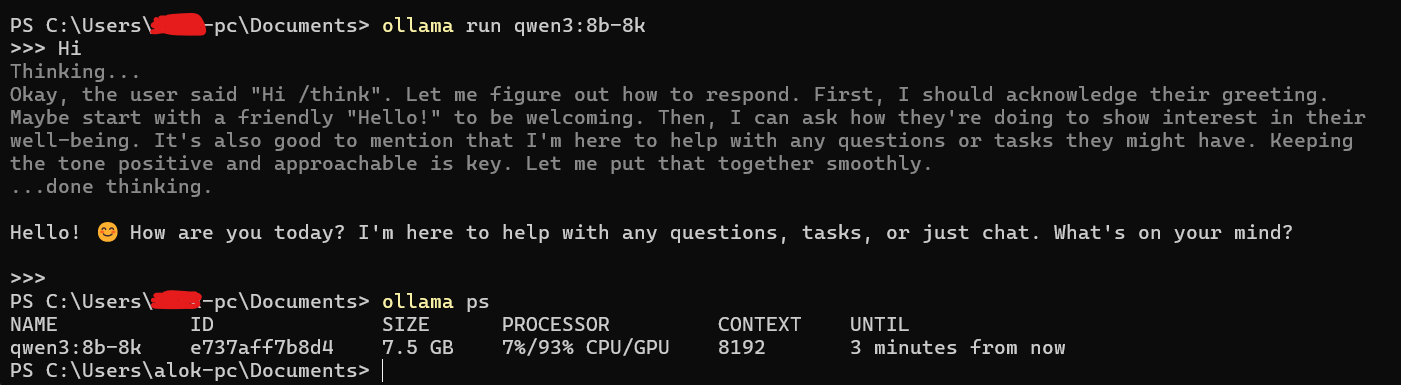
Notice how the VRAM has now increased to 7.5 GB. With the default 4k context, it utilized 6.5 GB and it was entirely in the VRAM. The model is using 1 GB extra VRAM for a 4k increase in context length. It loaded 6193MiB to the GPU VRAM and rest to the RAM.
Ollama loaded 93% of the new model's layers onto GPU's fast VRAM. This is where most of the heavy lifting and fast processing happens. GPU's VRAM wasn't large enough to hold the entire model. So, Ollama automatically offloaded the remaining 7% of the layers to your regular system RAM, where the CPU will process them.
Ollama Context Length vs Embedding Length
When you run ollama show <model_name>, you'll see two different values:
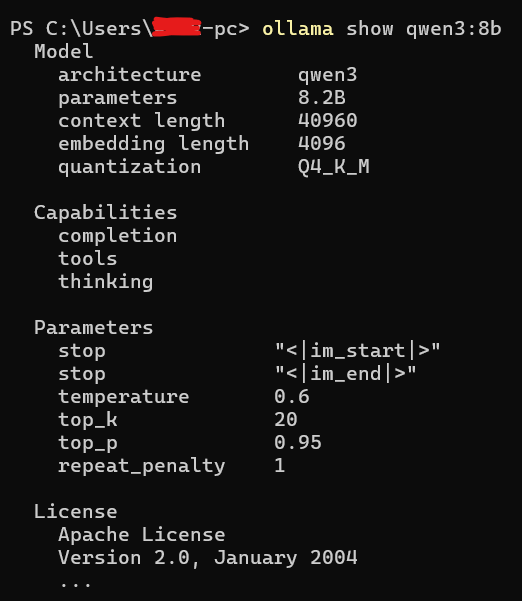
context length 40960
embedding length 4096
Here's a screenshot of the "ollama show qwen3:8b" command I ran locally on a Windows Machine:
Context Length
- What it is: The maximum number of tokens the model can consider when generating a response.
- Purpose: Determines how much previous conversation or text the model can reference.
- Impact: A larger context window allows the model to consider more information but requires more memory and may slow down processing.
- Adjustability: Can be set up to the model's maximum context length.
Embedding Length
- What it is: The dimension of the vector representation of tokens used by the model.
- Purpose: Determines the size of the semantic space in which tokens are represented.
- Impact: Affects the model's ability to capture nuanced relationships between tokens but is fixed by the model's architecture.
- Adjustability: Cannot be changed as it's a fundamental characteristic of the model.
Relationship Between Context Length and Memory Usage
Memory usage in language models is influenced by both context length and embedding dimensions, but the relationship is more complex than simple multiplication. When you increase the context length, the model needs to store more information about each token in the conversation, primarily through a mechanism called the KV cache. This cache grows as the context gets longer, requiring additional memory.
The embedding length affects how richly each token is represented in the model's understanding. Larger embedding dimensions allow for more nuanced representations but require more memory for each individual token.
However, memory usage depends on many factors beyond just these two values. The model's architecture, number of layers, attention mechanisms, and precision settings all play important roles. For example, the attention mechanism creates memory requirements that grow more rapidly than linearly with context length.
In practice, longer contexts generally require more memory, and models with larger embedding dimensions tend to use more memory per token, but the exact relationship varies significantly between different model architectures and implementations.
Using Ollama with Frontend Interfaces
When using frontend interfaces like OpenWebUI:
- Frontend settings for context window serve as templates only when interacting through that interface
- These settings do not change the default context window in Ollama itself
- If you query the same model directly through the Ollama API without specifying identical parameters, Ollama will treat it as a new model request
- This may cause the model to reload with different parameters than what was set in the frontend
Performance Considerations
Setting the context length higher may cause the model to not fit entirely onto the GPU, which will make it run more slowly. You can check where your model is loaded using:
ollama ps
Here's a screenshot of the "ollama ps" command we ran locally on a Windows Machine:
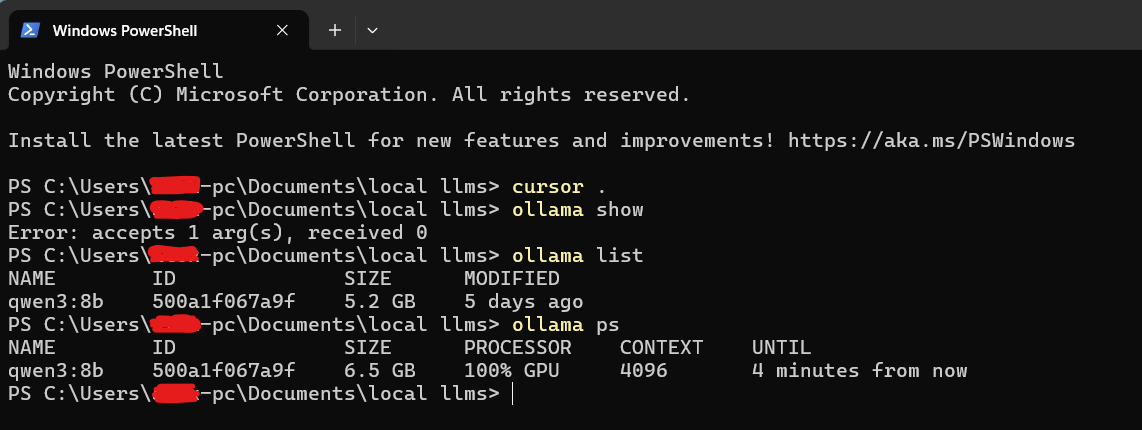
The PROCESSOR column will show:
- "100% GPU" means the model was loaded entirely into the GPU
- "100% CPU" means the model was loaded entirely in system memory
- "48%/52% CPU/GPU" means the model was loaded partially onto both
🧮 Use our VRAM Calculator to see exactly how context length affects your memory requirements and find the optimal balance for your hardware.
Qwen3 8b is a great model to run locally, has a context window of 40k with ollama and it's delivering throughput of about 42 TPS on RTX 4060 locally when plugged in and about 35 TPS on average on battery. For GPUS with 8GB of RAM, 8b 4 bit LLMs offer impressive accuracy/performance. Here we have compared the best Local LLMs for 8 GB VRAM.
Troubleshooting
My Context Window Settings Aren't Taking Effect
- Verify you're setting the context window correctly using one of the methods above
- Check the current context length with
ollama ps - Remember that changes made with
/set parameterare temporary unless you save them to a new model - If using a frontend interface, check if the interface is overriding your settings
How to Tell if My Model Was Loaded with the Correct Context Size
Use ollama ps to see the current context length being used by running models. This shows the actual context length in use, not just the model's maximum capability.
Conclusion
Understanding and properly managing context window size in Ollama is essential for getting optimal performance from your language models. By using the correct commands to check and set context length, and understanding the difference between a model's maximum context length and its current setting, you can better control how your models operate and ensure they're configured appropriately for your specific use cases.
FAQ
How do I check the maximum context length of a model in Ollama?
Run ollama show
and look for the "context length" field. The context length value in the output tells you the maximum number of tokens that model can handle in one session. For example, ollama show qwen3:8b may return context length 40960. How do I see the current context length being used in a running Ollama session?
Use ollama ps to view active models and their context size. The CONTEXT column shows the session's actual context length, which may be smaller than the maximum supported by the model. This only works if the model is already running in memory.
How can I increase the context window size in Ollama?
Set the num_ctx parameter when launching or running a model. You can do this by adding /set parameter num_ctx
in the CLI, setting OLLAMA_CONTEXT_LENGTH as an environment variable, adjusting context size in the Ollama GUI, or passing "options": {"num_ctx": } in API calls. How do I make a custom context length persistent in Ollama?
Save it as a new model or define it in a Modelfile. Session changes with /set parameter num_ctx are temporary. To persist, either run /save my-custom-model after setting the parameter or create a Modelfile with PARAMETER num_ctx
and build with ollama create. What is the difference between context length and embedding length in Ollama?
Context length is how many tokens the model can consider; embedding length is the size of token vectors. Context length is adjustable up to the model's maximum and affects how much prior conversation is remembered. Embedding length is fixed by architecture and determines the dimensionality of token representations.