Interactive
Local LLMs
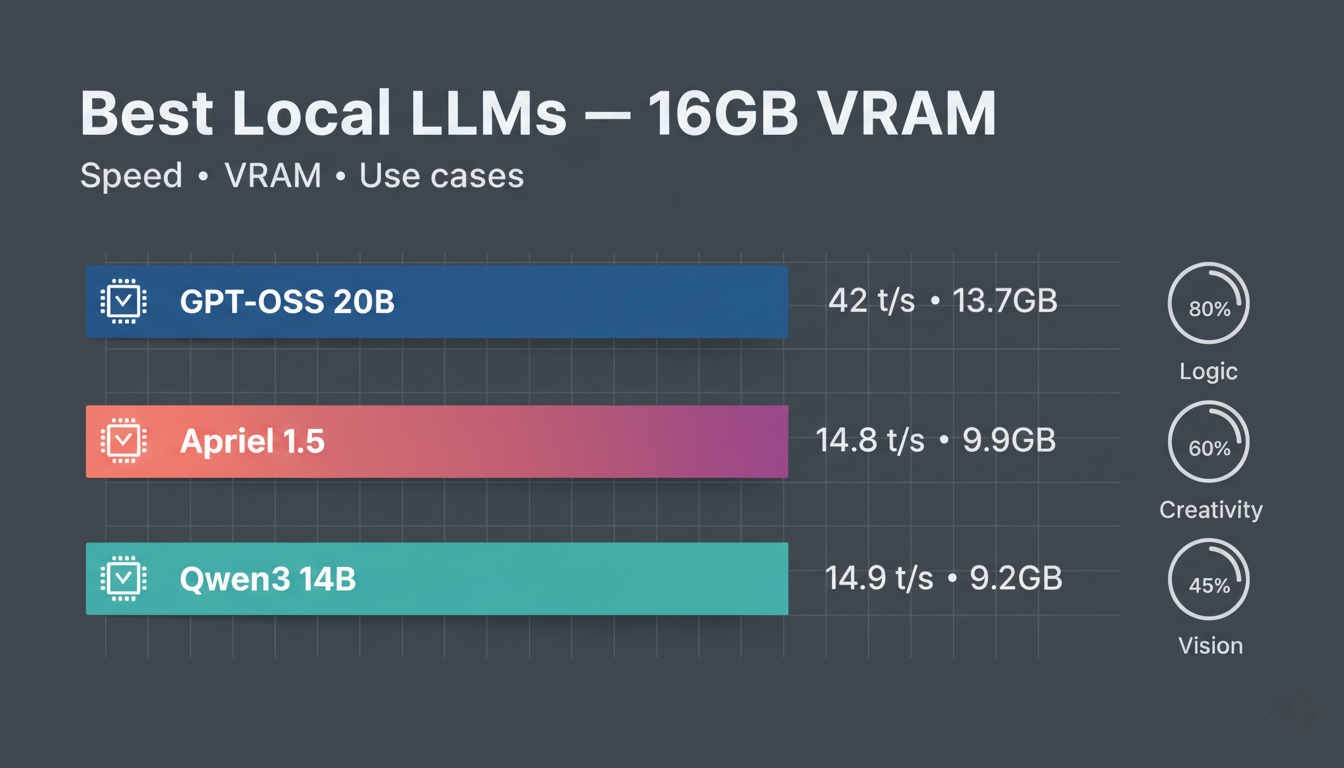
Best Local LLMs for 16GB VRAM: Practical Performance Testing 2026
Comprehensive analysis of top-performing local LLMs optimized for 16GB VRAM systems, featuring 14B-30B parameter models, MoE architectures, and practical optimization strategies for maximum performance.
Read more