Best Local LLMs for 16GB VRAM: Practical Performance Testing 2026
You've got 16GB of VRAM and a stack of LLM options that promise the world. But here's the problem: benchmarks only tell part of the story. A model scoring 96% on Math 500 might choke on basic code generation. Another topping LiveCodeBench could take 17 minutes to write what you need in 60 seconds. And neither metric reveals how models handle the specific, messy problems you'll actually throw at them. New to local LLMs? Start with our complete introduction to local LLMs to understand the basics.
This guide takes a different approach: we combined three independent validation methods to find what actually works on 16GB VRAM systems. First, we analyzed industry-standard benchmarks (AIME 2025, LiveCodeBench, MMLU-Pro) to establish baseline capabilities. Second, we profiled hardware performance metrics on an NVIDIA T4 with Ollama, measuring real VRAM consumption, generation speed, context scaling, and prompt processing rates under actual workloads. While the T4's performance is comparable to consumer RTX 2060/2070 GPUs, not frontier hardware, this provides reliable comparative data that translates directly to real world consumer setups. Third, we designed custom cognitive challenges from our years of model testing experience: spatial reasoning puzzles, multi-step logic problems, and creative coding tasks that don't exist in any training dataset. These out-of-sample tests reveal how models truly think when they can't rely on memorization.
The verdict? Three models separate from the pack: GPT-OSS 20B delivers 42 tokens/second with flawless reasoning, Apriel 1.5 15B-Thinker brings creative firepower and native vision support, and Qwen3 14B maximizes VRAM efficiency when you need headroom. Everything else involves serious compromises. Here's how we tested them and why it matters.
TL;DR: Best Local LLMs for 16GB VRAM in 2026
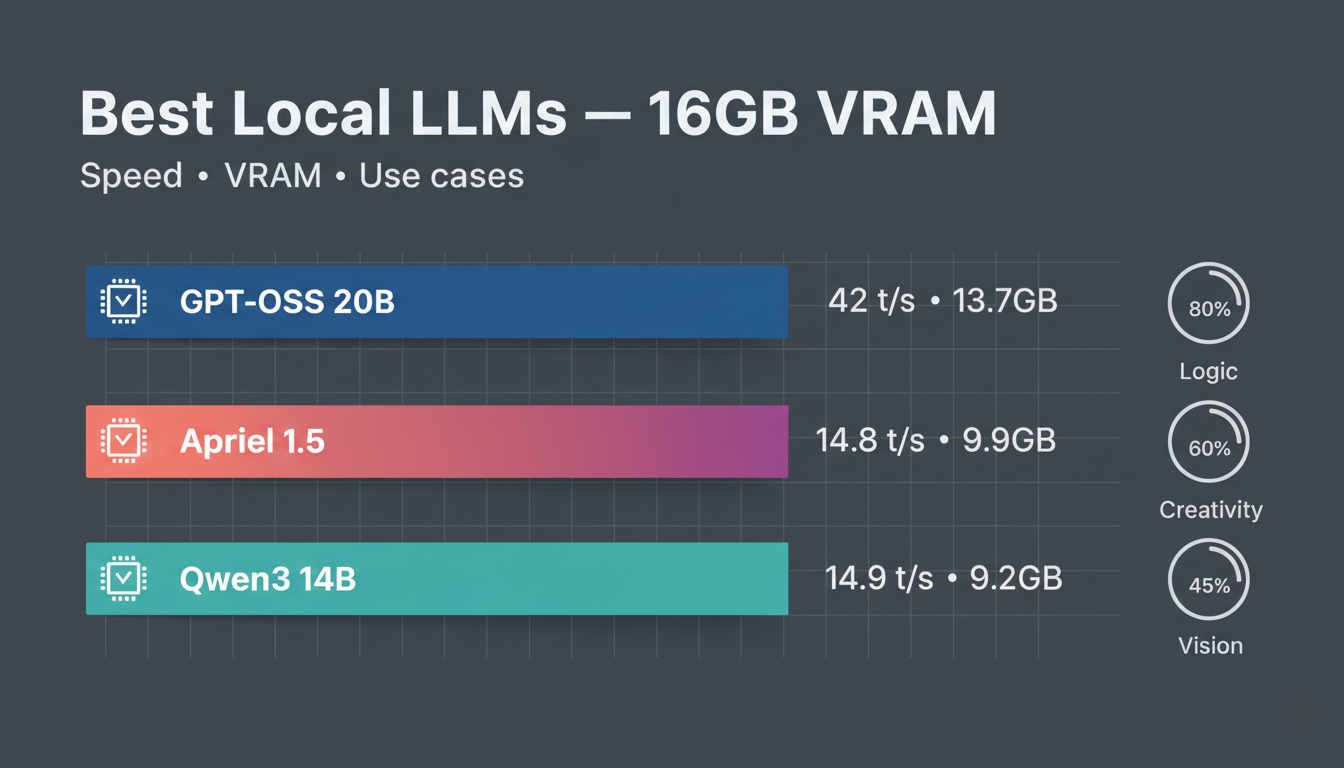
After testing the top local LLMs on 16GB VRAM with real hardware benchmarks, cognitive challenges, and practical workloads, GPT-OSS 20B at 60K context is the clear winner for most users. It generates at 42 tokens/second (2.8x faster than competitors), uses 13.7GB VRAM, and achieved perfect scores on logic tests while maintaining good code quality. For creative workflows requiring vision capabilities, Apriel 1.5 15B-Thinker delivers native screenshot analysis and innovative problem-solving at 14.84 t/s using just 9.9GB VRAM.
Key Findings:
- GPT-OSS 20B dominates speed and reliability: 42 t/s generation, 611-652 t/s prompt processing, perfect logic scores, and 52.1% artificial intelligence index score.
- Apriel 1.5 excels at creative tasks: native vision support, highest intelligence-per-GB efficiency, ideal for UI/UX and design work but requires validation on logic tasks.
- Qwen3 14B saves VRAM when used with low context window settings, but generates 2.8x slower with execution reliability issues. Choose only when VRAM headroom matters more than performance.
- Context window tuning matters as much as model selection: GPT-OSS at 120K context (7.05 t/s) performs worse than Apriel at 4K (14.84 t/s).
- Practical testing reveals benchmark blind spots: models scoring 96% on Math 500 can fail basic spatial reasoning.
Quick Decision Guide:
Choose GPT-OSS 20B for coding, debugging, research synthesis, technical writing, and workflows prioritizing reliability and speed. Choose Apriel 1.5 for UI/UX prototyping, creative brainstorming, screenshot analysis, and design challenges. Run both models (swap as needed) to cover 95% of use cases, or default to GPT-OSS alone if single-model simplicity matters more than creative capabilities.
Choosing the right GPU for your setup? See our comprehensive GPU comparison for LLM inference. Working with 8GB VRAM instead? Check our best local LLMs for 8GB VRAM guide.
Local LLM Benchmarks for 16 GB VRAM
Standardized benchmarks provide crucial context before diving into practical testing. Use the dashboard below to explore the performance of leading 16 GB VRAM models across various industry-standard benchmarks. Select a metric from the buttons to update the chart, and click on model names to filter the view for a direct comparison.
AI Model Performance Comparison
| Model Name | Creator | Release Date | Artificial Analysis Intelligence Index | Artificial Analysis Coding Index | Artificial Analysis Math Index | MMLU-Pro (Reasoning & Knowledge) | GPQA Diamond (Scientific Reasoning) | Humanity's Last Exam (HLLE) | LiveCodeBench (Coding) | SciCode (Bench Sci) | Math 500 | AIME 2025 (Competition Math) | AIME 25 | IFBench | LCR | TerminalBench Hard | TAU2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemma 3 12B Instruct | 2025-01-15 | 20.4% | 10.6% | 18.3% | 59.5% | 34.9% | 4.8% | 13.7% | 17.4% | 85.3% | 22.0% | 18.3% | 36.7% | 6.7% | 0.7% | 10.8% | |
| Apriel-v1.5-15B-Thinker | Apriel | 2025-01-10 | 51.6% | 39.2% | 87.5% | 77.3% | 71.3% | 12.0% | 72.8% | 34.8% | N/A | N/A | 87.5% | 61.7% | 20.0% | 9.9% | 68.4% |
| Qwen3 14B (Non-reasoning) | Alibaba | 2025-01-05 | 29.2% | 19.8% | 58.0% | 67.5% | 47.0% | 4.2% | 28.0% | 26.5% | 87.1% | 28.0% | 58.0% | 23.9% | 0.0% | 5.0% | 32.2% |
| Qwen3 14B (Reasoning) | Alibaba | 2025-01-05 | 36.0% | 29.1% | 55.7% | 77.4% | 60.4% | 4.3% | 52.3% | 31.6% | 96.1% | 76.3% | 55.7% | 40.5% | 0.0% | 3.5% | 34.5% |
| DeepSeek R1 Distill Qwen 14B | DeepSeek | 2025-01-20 | 29.7% | N/A | 55.7% | 74.0% | 48.4% | 4.4% | 37.6% | 23.9% | 94.9% | 66.7% | 55.7% | 22.1% | 7.0% | N/A | N/A |
| Phi-3 Medium Instruct 14B | Microsoft | 2024-11-15 | 14.4% | 8.9% | 1.3% | 54.3% | 32.6% | 4.5% | 15.0% | 11.8% | 46.3% | 1.3% | 1.3% | 21.5% | 3.0% | 0.0% | 0.0% |
| Pixtral 12B (2409) | Mistral | 2024-09-01 | 8.9% | N/A | N/A | 47.3% | 34.3% | 5.3% | 11.5% | 13.5% | 45.8% | 0.0% | N/A | N/A | N/A | N/A | N/A |
| Llama 2 Chat 13B | Meta | 2023-07-18 | 5.5% | N/A | N/A | 40.6% | 32.1% | 4.7% | 9.8% | 11.8% | 32.9% | 1.7% | N/A | N/A | N/A | N/A | N/A |
| gpt-oss-20B (low) | GPT-OSS | 2025-01-01 | 44.3% | 34.5% | 62.3% | 71.8% | 61.1% | 5.1% | 65.2% | 34.0% | N/A | N/A | 62.3% | 57.8% | 31.0% | 4.3% | 50.3% |
| gpt-oss-20B (high) | GPT-OSS | 2025-01-01 | 52.1% | 40.7% | 89.3% | 74.8% | 68.8% | 9.8% | 77.7% | 34.4% | N/A | N/A | 89.3% | 65.1% | 30.7% | 9.9% | 60.2% |
| Phi-4 Reasoning | Microsoft | 2025-03-01 | N/A | N/A | N/A | 74.3% | 65.8% | N/A | 53.8% | N/A | N/A | 75.3% | 62.9% | 83.4% | N/A | N/A | N/A |
| Phi-4 Reasoning Plus | Microsoft | 2025-03-01 | N/A | N/A | N/A | 76.0% | 68.9% | N/A | 53.1% | N/A | N/A | 81.3% | 78.0% | 84.9% | N/A | N/A | N/A |
| Phi-4 | Microsoft Azure | 2024-12-12 | 22.7% | 17.6% | 18.0% | 71.4% | 57.5% | 4.1% | 23.1% | 26.0% | 81.0% | 14.3% | 18.0% | 23.5% | 0.0% | 3.5% | 0.0% |
Key Benchmark Insights
The data show clear specializations across reasoning, coding, math, and instruction-following. Below we summarize the practical strengths and tradeoffs so you can pick a model by the failure mode you care about.
Knowledge & reasoning:
Apriel-v1.5-15B-Thinker and Qwen3 14B (Reasoning) stand out on knowledge and academic reasoning tasks. Apriel posts MMLU-Pro 0.773 / GPQA 0.713, while Qwen3 (Reasoning) has MMLU-Pro 0.774 / GPQA 0.604 - Qwen3 matches Apriel on MMLU while Apriel is stronger on GPQA.
GPT-OSS 20B (high) is also very capable on reasoning: MMLU-Pro 0.748 / GPQA 0.688.
Coding & developer workflows:
GPT-OSS 20B (high) and Apriel-v1.5-15B-Thinker are the strongest coding performers: GPT-OSS shows LiveCodeBench 0.777 (and coding index 40.7), Apriel shows LiveCodeBench 0.728 (coding index 39.2). Both also post the highest TerminalBench Hard numbers among the set (0.099).
Models like Qwen3 (Reasoning) and DeepSeek R1 Distill are competent but lower on live coding metrics (Qwen3 Reasoning LiveCodeBench 0.523; DeepSeek 0.376). For a deeper dive into coding-specific LLM performance, see our best local LLMs for coding guide.
Competition / advanced math:
Qwen3 14B (Reasoning) and DeepSeek R1 Distill Qwen 14B excel at competition-style math: Qwen3 Reasoning math_500 0.961 / AIME 0.763, DeepSeek math_500 0.949 / AIME 0.667.
GPT-OSS 20B (high) and Apriel also score very high on math index metrics (AIME-style math indices: GPT-OSS ~89.3, Apriel ~87.5 in the math index field), making them reliable for many advanced math tasks.
Instruction-following, safety & compliance:
Phi-4 Reasoning / Phi-4 Reasoning Plus are the clearest leaders for instruction following and compliance: IFBench 0.834 (Reasoning) and 0.849 (Reasoning Plus) - these are the highest IFBench values in the set. They also have strong AIME values (0.753 / 0.813) and solid MMLU scores (0.743 / 0.760), so they combine instruction reliability with good reasoning/math performance.
By contrast, models such as DeepSeek R1 Distill and Qwen3 14B (Non-reasoning) show much lower IFBench (0.221 and 0.239 respectively), indicating they may require more careful prompting and additional guardrails in production.
Notable specializations & caveats:
Qwen3 (Reasoning) is a particularly strong choice if your priority is competition math and strict MMLU performance (math_500 and MMLU are among the highest).
GPT-OSS (high) and Apriel are excellent all-rounders for engineering teams that need both strong coding and excellent math/reasoning.
Phi-4 Reasoning / Plus should be prioritized where instruction adherence, safety, and predictable compliance are critical, they may reduce prompt engineering needs thanks to high IFBench.
Several entries contain null or placeholder values for some metrics (e.g., Phi-4 models lack a composite AA index in your set, Qwen Chat 14B has mostly null metrics). Treat comparisons that rely on missing fields as inconclusive.
Practical selection guide (by failure mode):
- If code correctness / developer workflows matter most: prefer GPT-OSS 20B (high) or Apriel (highest LiveCodeBench & coding index).
- If you need strong, competition-level math reasoning: prefer Qwen3 14B (Reasoning) or DeepSeek R1 Distill.
- If instruction following, safety, and predictable outputs are critical: prefer Phi-4 Reasoning / Phi-4 Reasoning Plus (top IFBench).
- If you need balanced high competence across coding, math, and reasoning: consider GPT-OSS (high) or Apriel.
Practical Performance Testing: Where Theory Meets Hardware
To validate benchmark claims, we conducted extensive testing on an NVIDIA T4 GPU (16GB VRAM) system running Ollama with llama.cpp backend. Tests measured VRAM/RAM usage, load times, prompt evaluation rates (input processing speed), and generation rates (output token speed) across two practical workloads:
Test Task Definitions
To ensure consistent and reproducible results, we standardized two practical workloads that represent common practical use cases:
- Coding: Create an HTML page to explain a technical concept with animations. This task tests the model's ability to generate functional code, structure content logically, and implement interactive elements.
- Summarization: Summarize articles from our website in 500 words. This task evaluates inference performance which actual tokens increase as opposed to simply increasing the context window, mimicking real use scenarios.
Important technical note: The context values in our summarization tests represent actual tokens processed, not merely reserved context window settings. This distinction is critical: when you configure Ollama with a 60K context window, it allocates VRAM for the KV cache upfront, but if your prompt only contains 1K tokens, the cache remains mostly empty and inference stays fast. The summarization task was specifically designed to test real-world performance degradation by filling the KV cache with actual document content.
To illustrate: GPT-OSS 20B at 60K context shows dramatically different behavior between tasks. For the coding task (row 3 in the table below), the model generates a landing page with 60K context window reserved but uses far fewer actual input tokens, achieving 42.18 tokens/s generation speed with 13.7GB VRAM. For the summarization task (row 6), the model processes a real 48,822-token article, filling the KV cache completely. Despite identical VRAM usage (13.7GB), generation speed drops to 28.87 tokens/s, a 32% slowdown. The difference? The attention mechanism must compute over 48,822 actual tokens in the summarization task versus a much smaller effective context in the coding task. This is not just memory allocation; it's the computational cost of attending to tens of thousands of real tokens that causes the performance hit.
VRAM Efficiency: Fitting Models Within 16GB
Qwen3 14B at 4K context consumed just 9.2GB VRAM while generating at 14.86 tokens/second, using minimal system RAM (0.8GB). Apriel 1.5 at 4K required 9.9GB VRAM and achieved 14.84 t/s, with 0.4GB of system RAM usage. GPT-OSS 20B scaled from 12.1GB (1K context) to 14.1GB VRAM + 2.6GB RAM (120K context), demonstrating predictable VRAM growth as context expanded. It is also worth noting that once the total memory requirement approached and exceeded about 14GB, model layers or KV cache were offloaded to the system RAM automatically by Ollama. For a comprehensive breakdown of VRAM requirements across different models and configurations, see our complete guide to Ollama VRAM requirements. Use our interactive VRAM calculator to estimate memory requirements for your specific configuration.
| # | Context | Model (variant) | VRAM (GB) | RAM (GB) | Prompt eval rate (tokens/s) | Eval duration | Eval rate (tokens/s) | Task type |
|---|---|---|---|---|---|---|---|---|
| 1 | 4k | qwen3-coder:30b | 14.3 | 4.0 | 49.66 | 16m3.635206252s | 5.31 | coding |
| 2 | 120k | gpt-oss:20b | 14.1 | 2.6 | 166.05 | 567.570879610s | 7.05 | coding |
| 3 | 60k | gpt-oss:20b | 13.7 | 1.5 | 194.09 | 98.203985253s | 42.18 | coding |
| 4 | 4k | gpt-oss:20b | 12.2 | 1.5 | 191.55 | 61.157433174s | 42.19 | coding |
| 5 | 1k | gpt-oss:20b | 12.1 | 1.5 | 198.88 | 55.764900733s | 41.69 | coding |
| 6 | 60k | gpt-oss:20b | 13.7 | 1.9 | 611.77 | 56.082149128s | 28.87 | summarization |
| 7 | 32k | gpt-oss:20b | 13.0 | 1.7 | 652.15 | 39.313107211s | 34.16 | summarization |
| 8 | 4k | qwen3:14b | 9.2 | 0.8 | 205.58 | 240.644660728s | 14.86 | coding |
| 9 | 32k | qwen3:14b | 13.6 | 1.0 | 417.46 | 152.264928411s | 9.59 | summarization |
| 10 | 4k | MichelRosselli/apriel-1.5-15b-thinker:Q4_K_M | 9.9 | 0.4 | 282.93 | 545.165684398s | 14.84 | coding |
| 11 | 16k | MichelRosselli/apriel-1.5-15b-thinker:Q4_K_M | 13.2 | 0.6 | 315.02 | 265.442059637s | 9.48 | summarization |
| 12 | 20k | MichelRosselli/apriel-1.5-15b-thinker:Q4_K_M | 14.3 | 1.0 | 255.03 | 310.873009577s | 6.94 | summarization |
| 13 | 20k | mradermacher/Apriel-1.5-15b-Thinker-Text-Only.i1-Q4_K_M | 13.5 | 1.0 | 255.83 | 331.321750990s | 6.90 | summarization |
The critical insight: context length dramatically impacts VRAM. GPT-OSS 20B at 60K context (13.7GB) delivered 42.18 t/s generation, but pushing to 120K context (14.1GB) collapsed speed to 7.05 t/s, a 6x slowdown from saturating available memory. For 16GB systems, capping GPT-OSS at 60K context and Apriel/Qwen3 at 20K-32K maintains optimal performance.
Inference Speed: The Practical Bottleneck
GPT-OSS 20B dominated generation speed across all context lengths, consistently delivering 41-42 tokens/second for contexts up to 60K tokens. At 4K context, it completed a 2,580-token landing page generation in 61 seconds (42.19 t/s) while using just 12.2GB VRAM. Even at 60K context with 13.7GB VRAM, it maintained 42.18 t/s for 4,142 tokens, completing complex tasks in under 2 minutes. This MoE architecture advantage means only a subset of the 20B parameters activates per token, enabling dense-model-like throughput at reduced computational cost.
Apriel 1.5's performance exhibited high variance by context. At 4K context, it achieved respectable 14.84 t/s generation, but scaling to 20K context dropped throughput to 6.94 t/s, nearly matching GPT-OSS's 120K context penalty. Qwen3 14B settled in the middle: 14.86 t/s at 4K context, declining to 9.59 t/s at 32K. Not so surprisingly, Qwen3-Coder 30B managed only 5.31 t/s, taking 17 minutes to generate 5,118 tokens. For interactive workflows, GPT-OSS's consistent 40+ t/s proves essential.
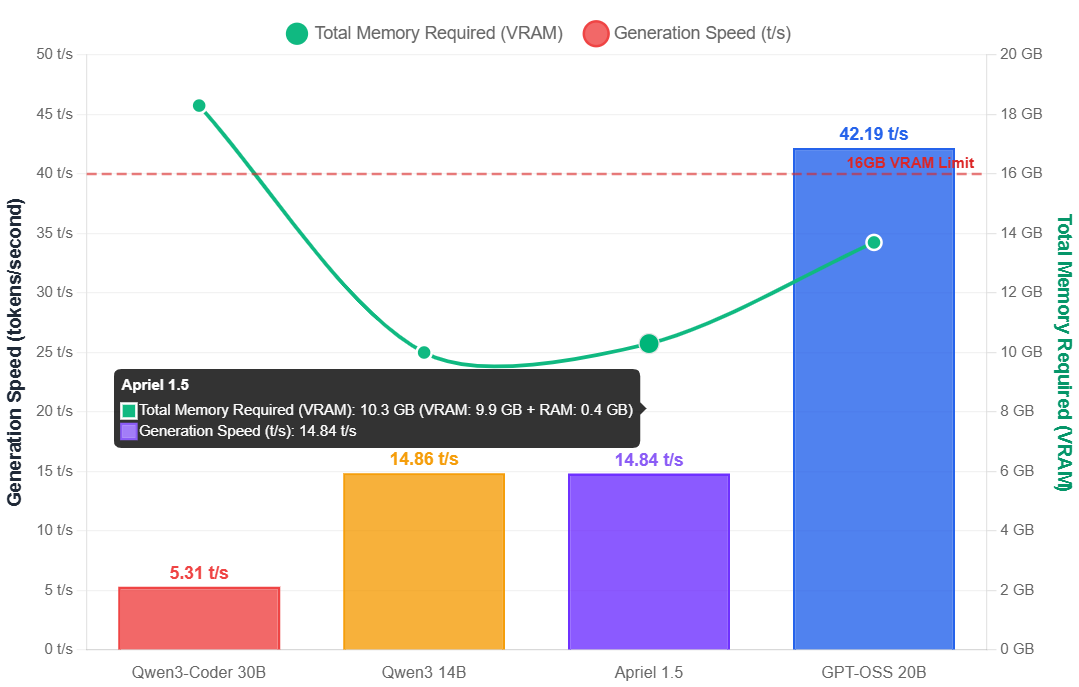
Generation speed vs total memory (VRAM + RAM) at 4K context, highlighting the performance-memory trade-off and 16GB VRAM limit
Long-Context Summarization: Processing Speed Under Load
Prompt evaluation rates - how quickly models process input before generating responses, prove critical for long-context workflows. GPT-OSS 20B demonstrated superior throughput: at 32K context, it processed 21,741 tokens at 652.15 t/s with a 33-second time-to-first-token, then generated a 1,343-token summary at 34.16 t/s (132 seconds total). Scaling to 60K context, it handled 48,822 input tokens at 611.77 t/s (80-second TTFT) and produced 1,619 output tokens at 28.87 t/s in 196 seconds. In practical terms: feed it a 50K-token technical paper, see first tokens within 90 seconds, receive a complete summary in under 3.5 minutes.
By contrast, Qwen3 14B processed 23,133 tokens at 417.46 t/s (32K context) but faltered during generation at just 9.59 t/s. Apriel 1.5 proved slower still: evaluating 20,000 tokens at 255.03 t/s (20K context) but generating at only 6.94 t/s, requiring nearly 7 minutes for a 2,158-token summary. For document-heavy research synthesis or codebase analysis, GPT-OSS's 600+ t/s prompt processing creates a qualitative difference, enabling workflows that slower models render impractical.
The Cognitive Gauntlet: How These Models Actually Think
We designed three challenges targeting spatial reasoning, instruction adherence, and creative problem solving skills that memorized benchmarks can't capture. The coding challenge asked models to generate an HTML page explaining a machine learning concept with animations. Spatial logic tests included perspective-taking (hand-swapping between facing actors), coordinate tracking (navigation with body relative directions), and sequential state tracking (queue position shifts).
Apriel 1.5: The Creative Powerhouse with a Catch
Apriel 1.5 emerged as the sole model to truly interpret "studio quality" (part of the prompt) as a design challenge rather than basic code correctness. It implemented GSAP (GreenSock Animation Platform) for timeline-based motion and HTML5 Canvas for a real-time neural network training simulation. The reasoning trace revealed it explicitly planned to "impress" the user with UX quality, demonstrating creative ambition beyond literal instruction-following.
However, this creative tendency backfired in spatial logic. Given "walk South, then walk towards the left," Apriel over-analyzed the phrasing, assuming "strafing" or lateral movement while maintaining a Southward facing, an unnecessarily complex interpretation leading to wrong coordinates. In perspective-taking tests, it struggled with mirroring effects when actors faced each other. Verdict: Apriel excels at brainstorming, UI/UX generation, and tasks valuing creativity over precision, but requires human validation for logical reasoning.
Qwen3 14B: Knowledge Without Application
Qwen3 14B coding attempt showcased its core weakness: perfect theoretical knowledge, flawed execution. It generated syntactically flawless Tailwind CSS utility classes but failed to include the CDN script tag, rendering the page as broken text. In spatial logic, it couldn't model the mirroring effect of facing actors. Navigation puzzles confused the model as well.
This reflects Qwen3's architecture: exceptional at knowledge retrieval and text generation (evidenced by 96.1% Math 500 and 77.4% MMLU-Pro scores), but fragile when simulating physical environments or multi-step processes. For API documentation, technical writing, or knowledge-dense tasks, Qwen3 shines, but expect to debug its practical outputs.
GPT-OSS 20B: The Reliable Reasoning Engine
GPT-OSS 20B produced uninspired but flawless code: standard HTML with CSS transitions, interpreting "studio quality" as "error-free and production-ready." While lacking Apriel's visual flair, every element functioned correctly, a senior engineer's approach favoring reliability over spectacle. In logic tests, GPT-OSS achieved a perfect score. It correctly visualized cross-body item transfers between facing actors, tracked orientation changes during navigation (South → pivot East → advance), and maintained sequential queue positions without speculation.
Its reasoning traces were disciplined and linear, breaking problems into atomic steps and executing without deviation. This aligns with its benchmark strength in GPQA (61.1-68.8%, graduate-level scientific reasoning) and LiveCodeBench (65.2-77.7%, real-world coding). For debugging, mathematical proofs, operational planning, or any task where correctness trumps creativity, GPT-OSS is unmatched in the 16GB VRAM class.
| Aspect | Apriel 1.5 | Qwen3 14B | GPT-OSS 20B |
|---|---|---|---|
| Creativity (Coding) | 9/10 | 7/10 | 6/10 |
| Logic (Spatial/Sequential) | 5/10 | 4/10 | 10/10 |
| Instruction Following | 8/10 | 6/10 | 9/10 |
| Overall Character | Divergent Dreamer | Fragile Factoid | Convergent Pro |
Decision Matrix: Pick Your 16GB VRAM Champion
After extensive testing, the reality is simpler than benchmark sheets suggest: for 16GB VRAM systems in 2026, you're choosing between two models, GPT-OSS 20B for professional reliability or Apriel 1.5 for creative workflows. Everything else involves meaningful compromises.
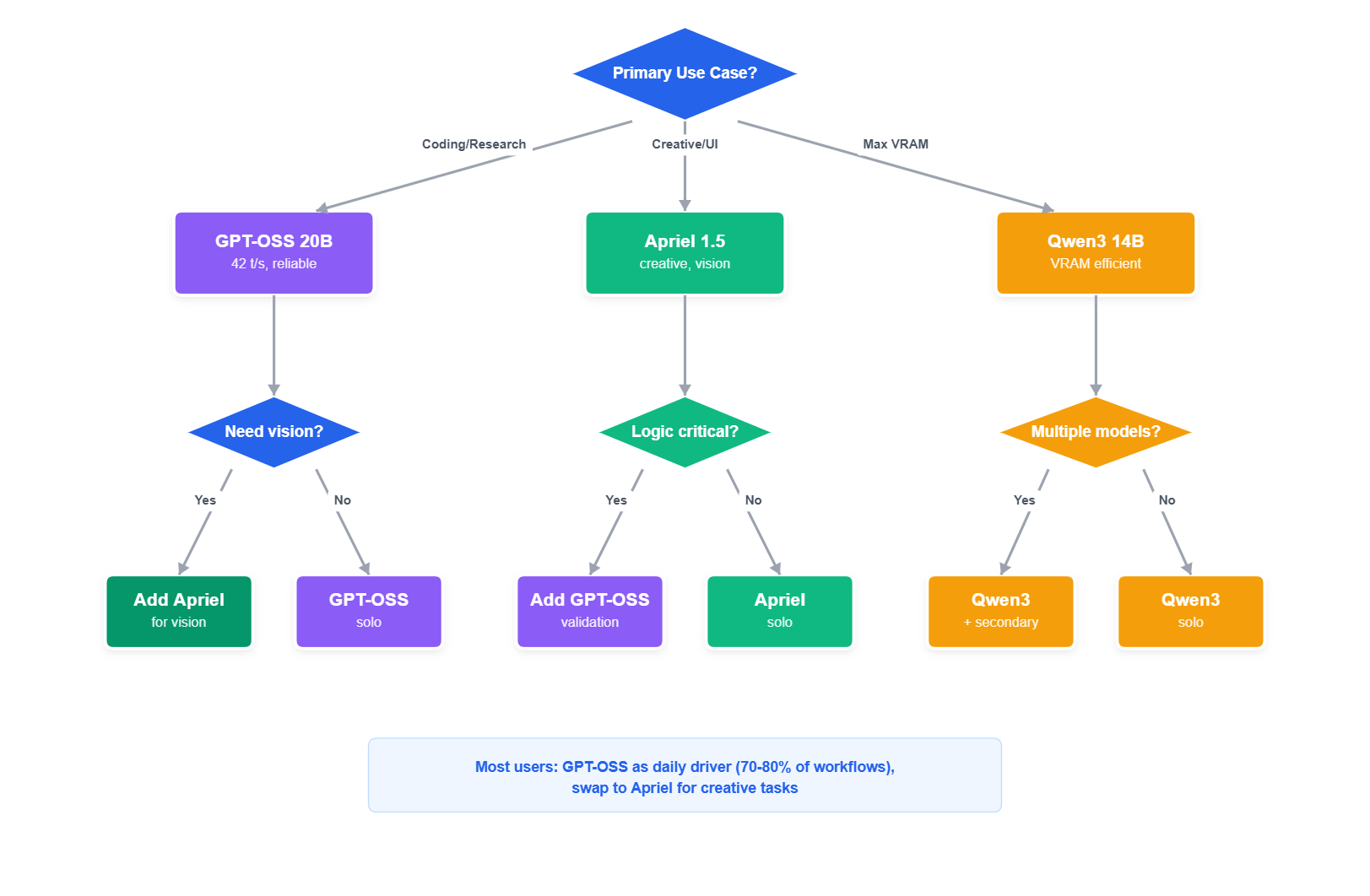
Decision flowchart for selecting the best local LLM based on your workflow requirements and priorities
Best Overall: GPT-OSS 20B at 60K Context
When to choose: Professional coding, debugging, research synthesis, technical writing, long-context analysis, mathematical reasoning, or any workflow where reliability and speed both matter.
Real-world performance:
- Generation speed: 42.18 t/s (consistent across 4K-60K contexts) - 2.8x faster than alternatives
- Prompt processing: 611-652 t/s depending on context
- VRAM footprint: 13.7GB at 60K, 12.2GB at 4K
- Long-context capability: Process 50K-token documents with 80-second time-to-first-token, complete summaries in under 4 minutes
Why it dominates: GPT-OSS achieves 52.1% intelligence index while generating at 42+ t/s regardless of context length. In our cognitive tests, it achieved perfect logic scores and produced production-ready code without errors. The MoE architecture activates only relevant parameters per token, delivering dense-model reasoning at reduced computational cost.
The speed advantage matters: At 42 t/s, GPT-OSS generates a 2,500-token response in 60 seconds. Apriel and Qwen3 at 15 t/s need 167 seconds, nearly 3 minutes. This 2.8x difference transforms interactive workflows: debugging sessions flow naturally, brainstorming stays conversational, and long-form writing doesn't break concentration.
The only trade-off: Outputs prioritize correctness over visual flair. Avoid 120K context (collapses to 7.05 t/s); cap at 60K for optimal performance.
Setup: ollama run gpt-oss:20b with num_ctx 60000. Use 32K if you rarely process documents over 20K tokens (saves 0.7GB VRAM).
Best for Creative & Multimodal Work: Apriel 1.5 15B-Thinker at 4K-16K Context
When to choose: UI/UX prototyping, design challenges, brainstorming, creative writing, exploratory coding, screenshot analysis, document layout understanding, or workflows where innovation and visual impact outweigh execution perfection.
Real-world performance:
- Generation speed: 14.84 t/s at 4K, 9.48 t/s at 16K
- Prompt processing: 283-315 t/s
- VRAM footprint: 9.9GB at 4K, 13.2GB at 16K (vision-capable variant)
- Efficiency champion: 5.21 intelligence per GB of VRAM (beats GPT-OSS at 4.27 and Qwen3 at 3.91) - calculated by dividing the Artificial Analysis Intelligence Index score by peak VRAM usage at 4K context

Intelligence index vs VRAM usage comparison highlighting Apriel 1.5's efficiency advantage
Why it wins its category: Apriel is the only model with native vision support, analyze screenshots, debug UIs, and process document layouts without switching models. In our cognitive tests, it was the sole model to interpret "studio quality" as a design challenge, implementing GSAP animations and Canvas simulations. Its 51.6% intelligence index proves frontier-level reasoning in a compact package.
When creative thinking matters: For brainstorming, UI prototyping, or exploratory coding, Apriel's tendency to think creatively produces ideas better than GPT-OSS 20b. Just validate logical reasoning manually, creative overthinking derails spatial logic and precision tasks.
The speed trade-off: At 14.84 t/s (4K), Apriel generates 2.8x slower than GPT-OSS. This matters for long-form generation but barely affects short creative bursts. At 16K context, speed drops to 9.48 t/s, still responsive for design work but sluggish for document processing.
Setup:
- Vision-capable:
ollama run MichelRosselli/apriel-1.5-15b-thinker:Q4_K_M - Text-only:
ollama pull mradermacher/Apriel-1.5-15b-Thinker-Text-Only.i1-Q4_K_M.gguf(saves 0.8GB) - Context sweet spot: 4K for maximum speed (14.84 t/s), scale to 16K only when needed (9.48 t/s), avoid exceeding 16K
The Qwen3 14B Question: When Does It Make Sense?
Qwen3 14B at 4K context saves 2.3GB VRAM compared to GPT-OSS while generating 2.8x slower and scoring 16 points lower on intelligence (36.0 vs 52.1). It saves 0.7GB compared to Apriel while delivering 43% worse intelligence at identical speed. In performance-per-GB terms, Qwen3 is the least efficient model in our tests.
What it does well: Knowledge retrieval. Qwen3 achieves 96.1% Math 500 and 77.4% MMLU-Pro, it recalls information flawlessly. For documentation, technical explanations, or mathematical derivations where encyclopedic accuracy matters more than reasoning depth, Qwen3 delivers.
What it does poorly: Execution. In our coding test, Qwen3 generated perfect Tailwind CSS classes but forgot the CDN script tag, breaking the entire page. It failed spatial reasoning and multi-step logic tasks. Treat it as a brilliant encyclopedia needing constant supervision when building things.
Real-world performance at 4K context:
- VRAM footprint: 9.2GB (leaves 6.8GB free)
- Generation speed: 14.86 t/s (matches Apriel, 2.8x slower than GPT-OSS)
- Prompt processing: 205.58 t/s
Critical warning: At 32K context, Qwen3 uses 13.6GB VRAM, while generating 35% slower (9.59 vs 42.18 t/s) with worse reasoning.
Legitimate use cases:
- Running multiple models simultaneously (9.2GB leaves room for a second model)
- Maximum VRAM headroom for other GPU applications (gaming, rendering)
- Pure knowledge retrieval workflows (documentation, technical writing)
- Budget learning/experimentation before hardware upgrades
Setup: ollama run qwen3:14b with default 4K context. Only increase context if your workflow genuinely requires it.
The Two-Model Strategy
For users who can spare the setup overhead, two complementary models cover 95% of use cases:
Primary: GPT-OSS 20B at 60K (13.7GB) for coding, debugging, analysis, research, production workflows, 42 t/s generation, 600+ t/s prompt processing. Unload when switching to creative tasks.
Secondary: Apriel 1.5 at 4K-16K (9.9-13.2GB) for UI/UX prototyping, brainstorming, creative writing, screenshot analysis, 14.84 t/s at 4K. Unload when returning to production workflows.
Why this works: You never need both loaded simultaneously. GPT-OSS handles 70-80% of daily workflows; Apriel tackles the creative 20-30% where thinking differently produces breakthrough value.
Alternative: Install only GPT-OSS if switching feels like friction. You'll sacrifice Apriel's innovative flair and vision capabilities but maintain consistency and maximum speed.
Specialized Honorable Mentions
DeepSeek R1 Distill Qwen 14B: For competition math-heavy workflows (94.9% Math 500, 66.7% AIME). Expect 9-10GB VRAM and 15 t/s generation, choose only if mathematical correctness matters more than speed.
Phi-4 Reasoning / Plus: Exceptional instruction-following (83.4-84.9% IFBench) and competition math (75.3-81.3% AIME). Choose if prompt adherence and safety matter more than speed. Limited quantized availability restricts testing; expect ~9-10GB VRAM.
Qwen3-Coder 30B: Only if coding is 90%+ of your workflow and you tolerate 5.31 t/s (8x slower than GPT-OSS). At 14.3GB VRAM, it occupies GPT-OSS's space but delivers drastically slower output, 17 minutes for 5,118 tokens. Potentially valuable for overnight batch processing but impractical for interactive work.
Your Action Plan
- Start with GPT-OSS 20B at 60K context. Run it for two weeks as your daily driver, it handles 70-90% of workflows excellently.
- Add Apriel 1.5 if needed. If UI prototyping, design work, or multimodal tasks comprise 20%+ of your workflow, install Apriel at 4K-16K context alongside GPT-OSS.
- Consider Qwen3 only if: You need maximum VRAM headroom for other applications, run multiple models simultaneously, or work primarily on knowledge retrieval where execution quality doesn't matter. For most users, the 3GB savings don't justify the 2.8x speed penalty and reliability issues.
- Test with your actual prompts. Benchmarks guide initial selection, but hands-on experience reveals cognitive fit.
The "best" model depends on your use case, but for general-purpose reliability with excellent speed and reasoning, GPT-OSS 20B at 60K context remains the clear winner for 2026.
Optimization Pro Tips for 16GB VRAM Systems
Choosing Vision vs. Text-Only Variants
Many recent models offer both vision-capable and text-only variants. Apriel 1.5 demonstrates this trade-off clearly: the vision-capable version adds ~0.8GB VRAM at 20K context (14.3GB vs. 13.5GB) with negligible speed difference (6.94 vs. 6.90 t/s).
Choose vision-capable when you need:
- Screenshot/UI analysis for debugging or design feedback
- Document layout understanding (parsing PDFs, forms, diagrams)
- Occasional multimodal tasks mixed with text generation
- Single-model workflows to avoid swapping between text and vision models
Choose text-only when you need:
- Maximum VRAM headroom for longer context windows
- Purely text-based workflows (coding, writing, analysis)
- Running multiple models simultaneously
- Better thermal characteristics on VRAM-constrained systems
The performance impact is minimal (usually <5% speed difference), so this decision primarily affects VRAM budget. For 16GB systems running multiple concurrent models or maximizing context length, text-only variants provide crucial breathing room.
Context Window Tuning
Treat the context window as two separate costs. VRAM reservation (what your runtime allocates) and compute/attention cost (what slows generation as you fill that window) and tune for the latter: measure actual input-token counts (not just reserved window), pick model-specific sweet spots (our benches: GPT-OSS ≈60K, Apriel ≈4–16K, Qwen3 up to ≈32K), and use pipeline patterns that avoid full-attend on huge docs (progressive summarization, retrieve-and-summarize, or sliding-window + chunk summaries). Prefer text-only variants when VRAM is tight. Learn how to increase context length in Ollama for your specific use case.
Quantization Selection
Q4_K_M quantization remains the gold standard for 16GB systems, reducing model size ~75% with only 2-5% quality loss. K-quantization methods intelligently allocate higher precision to critical weights, preserving more information than uniform Q4_0 schemes despite similar file sizes. Learn more about quantization methods and their impact on VRAM in our detailed guide.
KV Cache Management
The key-value cache grows linearly with context length, directly consuming VRAM. Enable Flash Attention to reduce KV cache 5-10%: `FLASH_ATTENTION=1 ollama serve`. Flash attention also reduces TTFT.
Making the Call: Strategic Deployment for 2026
The testing reveals a clear performance hierarchy, but your optimal choice depends on workflow composition rather than raw benchmarks. For most developers running 16GB VRAM systems, the two-model strategy delivers maximum versatility: deploy GPT-OSS 20B as your daily driver for 70-80% of tasks requiring speed and reliability, then swap to Apriel 1.5 when creative exploration or multimodal analysis justifies the switch.
Single-model setups should default to GPT-OSS 20B at 60K context unless your workflow genuinely prioritizes creative output over execution speed. The 42 t/s generation speed transforms interactive work, debugging stays conversational, long-form writing maintains flow, and document processing completes before context-switching breaks concentration. This 2.8x speed advantage over alternatives compounds across daily usage, saving hours per week.
Qwen3 14B occupies an edge case: choose it only when VRAM headroom matters more than performance (running multiple models, GPU-intensive parallel tasks, or learning experimentation). The 3GB savings don't justify the reliability and speed tradeoffs for production work.
The critical insight: context length management matters more than model selection. GPT-OSS 20b at 120K context performs worse than Apriel at 4K. Tune your context window to actual needs rather than maximizing available space. Start conservative (4K-32K), scale only when document processing demands it, and monitor generation speed as your real-world constraint.
Begin with GPT-OSS 20b, measure performance on your actual prompts for two weeks, then decide if Apriel's creative capabilities or Qwen3's VRAM efficiency justify adding a second model to your rotation.
References
- Artificial Analysis - Benchmark scores for AIME 2025, LiveCodeBench, MMLU-Pro, GPQA, Math 500, IFBench, and Artificial Intelligence Index. Available at: https://artificialanalysis.ai/
Frequently Asked Questions
What is the best local LLM for 16GB VRAM in 2026?
GPT-OSS 20B at 60K context is the best overall choice for 16GB VRAM systems. It delivers 42 tokens/second generation speed consistently across contexts up to 60K, uses 13.7GB VRAM, and achieves perfect scores on logic and reasoning tests. For creative workflows requiring UI/UX design or vision capabilities, Apriel 1.5 15B-Thinker offers native screenshot analysis and innovative problem-solving at 14.84 tokens/second, using just 9.9GB VRAM at 4K context. GPT-OSS provides 2.8x faster generation than alternatives while maintaining good reliability.
Why does my local LLM slow down with longer context windows?
Long context increases both VRAM consumption and attention computation cost. When GPT-OSS 20B processes 48,822 actual tokens at 60K context, generation speed drops from 42 to 28.87 tokens/second, a 32% slowdown, despite identical VRAM usage. This happens because the attention mechanism must compute over every token in the context, not just allocate memory. The KV cache fills with real data, forcing the model to attend to tens of thousands of tokens per generation step. Solutions: use progressive summarization for long documents, enable Flash Attention (reduces KV cache 5-10%), and tune context to actual needs rather than maximizing window size.
What's the difference between benchmark scores and actual LLM performance in practice?
Benchmarks measure memorized patterns; real world tasks test novel problem solving. A model scoring 96% on Math 500 might fail basic spatial reasoning or generate syntactically perfect code with broken logic. For practical deployment, test models on your actual prompts. Measure generation speed under real workloads, validate outputs on domain specific tasks, and assess instruction-following with custom challenges.
GPT-OSS 20B vs Apriel 1.5 15B: Which should I choose?
Choose GPT-OSS 20B for professional reliability and speed; choose Apriel 1.5 for creative work and vision capabilities. GPT-OSS generates 2.8x faster (42 vs 14.84 tokens/second), achieves perfect logic scores, and handles 60K contexts with about 15 GB total memory requirement, ideal for coding, debugging, research, and technical writing. Apriel 1.5 offers native vision support for screenshot analysis, scores highest in intelligence-per-GB efficiency (5.21 vs 4.27), and excels at UI/UX prototyping with innovative problem solving, but requires manual validation for spatial logic. For most users, run GPT-OSS as your daily driver (70-80% of workflows), then swap to Apriel when creative exploration or multimodal tasks justify it. Single-model setups should default to GPT-OSS unless visual design comprises 50%+ of your workflow.
Why are MoE (Mixture of Experts) models faster than traditional LLMs?
MoE models activate only a subset of parameters per token, reducing computational cost while maintaining performance. GPT-OSS 20B uses MoE architecture to deliver inference speeds faster than smaller 14B models, because only relevant experts process each token rather than the entire 20 billion parameters. This sparse activation reduces FLOPs (floating point operations) per inference, lowering both computational demands and energy consumption. A gating network dynamically routes each input token to specialized experts trained for specific patterns (syntax, semantics, domain knowledge), enabling massive scalability without proportional increases in computing power. The result: GPT-OSS achieves higher benchmarks while generating faster than 14B dense models that score lower on benchmarks.
Is 16GB VRAM enough for running local LLMs in 2026?
Yes, 16GB VRAM is sufficient for excellent local LLM performance when using optimized models and quantization. GPT-OSS 20B achieves 52.1% artificial intelligence index while using only about 15 GB of total memory at 60K context with Q4_K_M quantization. Apriel 1.5 delivers 51.6% artificial intelligence index with native vision support at just 9.9GB VRAM. The limitation is context length, not model capability: 16GB constrains GPT-OSS to about 60-80K context and Apriel to 16-20K context before performance degrades. Upgrade to 24GB VRAM only if you regularly process 100K+ token documents, run multiple models simultaneously in production, or need 20B+ parameter models.