How to Increase Context Length in LM Studio
Long context is the difference between ad-hoc prompts and real long form workflows. In LM Studio, context length is not just a number, it’s a memory and I/O problem you can engineer around without scratching your head much. This article walks through how LM Studio context window size maps to KV cache, VRAM and system RAM, and shows three practical strategies to increase context length in LM Studio (GUI, advanced load flags, and SDK/CLI).
You’ll get concrete rules of thumb (how much KV a 32K window costs, when Flash Attention helps, and why context overflow policies like truncateMiddle vs rollingWindow behave differently), step-by-step CLI/SDK snippets, and targeted troubleshooting for the common case of LM Studio GPU offload not working. This is the hands-on guide for squeezing large-context performance out of consumer GPUs.
To make it even easier to follow along, we've embedded step-by-step tutorial videos in Methods 2 and 3.
Quick Reference Card
| Your GPU VRAM | Recommended Context | Model Size | Model Examples for LM Studio |
|---|---|---|---|
| 6GB | 8-10K | 3-4B Q4 | Qwen3-4B, Gemma 3-4B, Llama 3.2-3B, DeepSeek-R1-Distill-1.5B, Phi 4 mini reasoning |
| 8GB | 8-16K | 8B Q4 | Qwen3-8B, DeepSeek-R1-Distill-Qwen-8B, Gemma 3-12B |
| 12GB | 16-32K | 13-14B Q4 | Qwen3-14B, Gemma 3-12 B, Phi 4 reasoning plus |
| 16GB | 24-32K | 13-14B Q4 | Qwen3-14B, Gemma 3-12 B, Phi 4 reasoning plus |
| 24GB | 24-32K | 22-27B Q4 | Gemma 3-27B, Mistral Small 3.2 (22-24B), magistral-small-2509, OpenAI gpt-oss 20B |
| 32GB | 32-48K | 30-32B Q4 | Qwen3-32B, Qwen3-32B, Qwen3-30b-a3b, Qwen 3 Coder 32B |
| 48GB | 64-128K | 30-32B Q4 | Qwen3-32B, Qwen3-32B, Qwen3-30b-a3b, Qwen 3 Coder 32B |
| 80GB | 32-100K | 70B Q4 | DeepSeek-R1-Distill-Llama-70B |
Get started quickly with these hardware recommendations. Use our Interactive VRAM Calculator for detailed calculations. See our Best Local LLMs for 8GB VRAM guide for model recommendations that work within specific hardware constraints, and check out our Best GPUs for Local LLM Inference 2025 if you're looking to upgrade your hardware.
What You'll Learn
- Understanding context windows and why they matter for AI conversations
- KV cache VRAM requirements and linear scaling with context length
- Easiest beginner method for context length increase using GUI
- Intermediate method with custom model load parameters
- Advanced CLI and SDK methods for developers
- Optimizing Flash Attention and GPU KV cache offload for best performance
- Handling context overflow policies and choosing the right approach
- GPU offload fundamentals and configuration strategies
- Best practices and troubleshooting guide
What is the Context Window in LM Studio and Why Does It Matter?
The context window in LM Studio, also referred to as context length, determines how much information a model can retain during a single session. Consider it the model's short-term memory: everything from your system prompt to the complete chat history must fit within this space, measured in tokens (where each token represents approximately 0.75 words).
Default configurations: Most models ship with context windows of 4k to 32k tokens, though cutting-edge models like Qwen3 Coder 30B and Qwen3-VL-30B extend this to 256K tokens, enabling sophisticated tasks such as document analysis, complex coding projects, and video analysis.
Performance considerations: Expanding your context window allows LM Studio to process lengthy conversations or digest entire documents, but this increase comes at a cost of significantly higher memory consumption. Push beyond your hardware's limits, and you'll encounter context overflow, causing the model to drop critical information or halt generation entirely. Later in this article, we'll explore three proven strategies to extend context length without overwhelming your system or sacrificing performance.
Below, we'll walk through three practical methods that allow you to maximize context window size in LM Studio without compromising speed or exhausting your GPU's VRAM.
Understanding KV Cache VRAM Requirements for Context Length in LM Studio
Before diving into the methods, it's crucial to understand how context length impacts your hardware. The KV (Key-Value) cache is what stores the attention states for every token in your context window, and it directly determines how much VRAM you'll need.
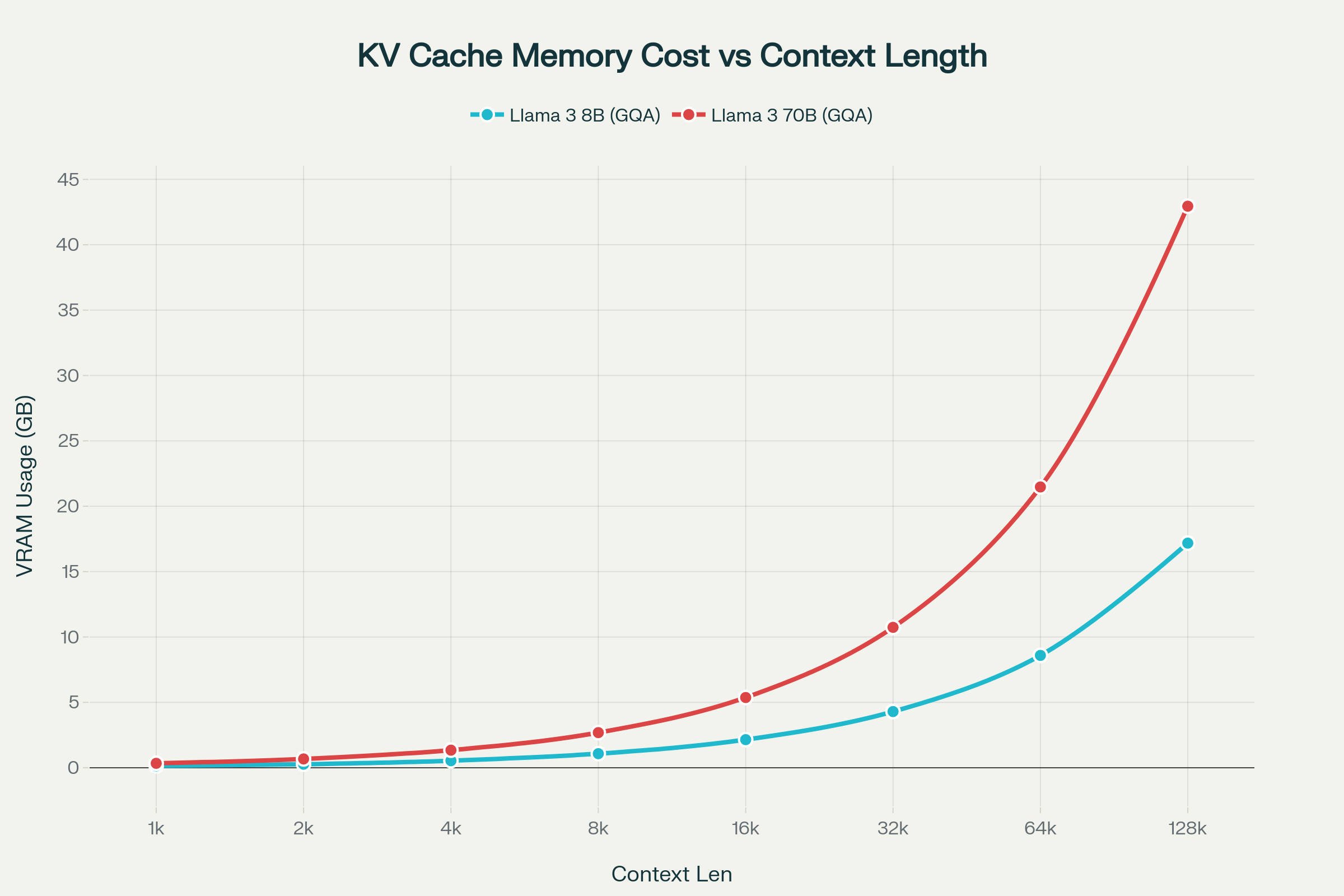
The graph above reveals a linear relationship between context length and VRAM usage, but also shows how Grouped Query Attention (GQA) keeps memory costs manageable even for larger models. Notice that while the 70B model has nearly 9× more parameters than the 8B model, its KV cache at 128K context is only 2.5× larger, approximately 39.06 GB versus 15.62 GB for FP16 cache precision (LM Studio's default), or 10.7 GB versus 4.3 GB with INT4 quantized KV cache (Not recommended due to performance degradation in complex tasks).
This efficiency comes from both models using 8 KV heads, though with different grouping factors: the 70B model (64 attention heads) achieves g=8, while the 8B model (32 attention heads) achieves g=4. The 2.5× cache ratio maps directly to the layer count difference, 80 layers in 70B versus 32 layers in 8B, making long-context inference feasible on consumer hardware without memory requirements ballooning proportionally to parameter count.
Key takeaway: When planning your context length increase, factor in both the model size and the KV cache overhead. A 32K context on an 8B model might need 4-6 GB additional VRAM beyond the model weights. Quantization (like Q4) and Flash Attention (recommended) can significantly reduce this footprint. For a complete breakdown of VRAM requirements in LM Studio, see our LM Studio VRAM Requirements for Local LLMs. Learn how quantization reduces model size by up to 75% while maintaining performance in our Complete Guide to LLM Quantization.
Best Context Length setting for various use cases in LM Studio
Here's a practical comparison of common context lengths with their typical use cases:
| Context Length | Use Case |
|---|---|
| 512-1K | Quick questions, simple prompts, minimal context needs |
| 2K-4K | Brief conversations, single-page documents, basic queries |
| 4K-8K | Multi-turn chat, short documents, casual conversations |
| 8K-16K | Extended conversations, detailed instructions, small documents, coding |
| 16K-32K | Document analysis, code review, research papers, complex tasks, coding, simple agentic tasks |
| 32K-64K | Large document analysis, codebases, technical writing, research, lengthy coding, complex agentic task |
| 64K-128K | Multiple documents, comprehensive research, long technical specs, agentic coding, deep research |
| 128K-256K | Full ebooks, enterprise applications, advanced research, data analysis, agentic coding, deep research |
| 256K-1M | Massive datasets, entire knowledge bases, enterprise-scale applications, agentic coding, deep research, long running agentic tasks |
Method 1: Increase Context Length in LM Studio: Easiest method for Beginners
Step 1: Launch and Load a Model in Developer/Power User Mode
Open LM Studio and load your model (e.g., Qwen 3 8b). Before or after loading, click the button at bottom left to switch to the Power User or Developer mode.

Step 2: Set Custom Context Length
Look for the gear icon to the left of the model picker dropdown and click it. Using the slider or the input field, set the desired context length and click on the 'Reload to apply changes' button. Now you are ready to start chatting with increased context length.
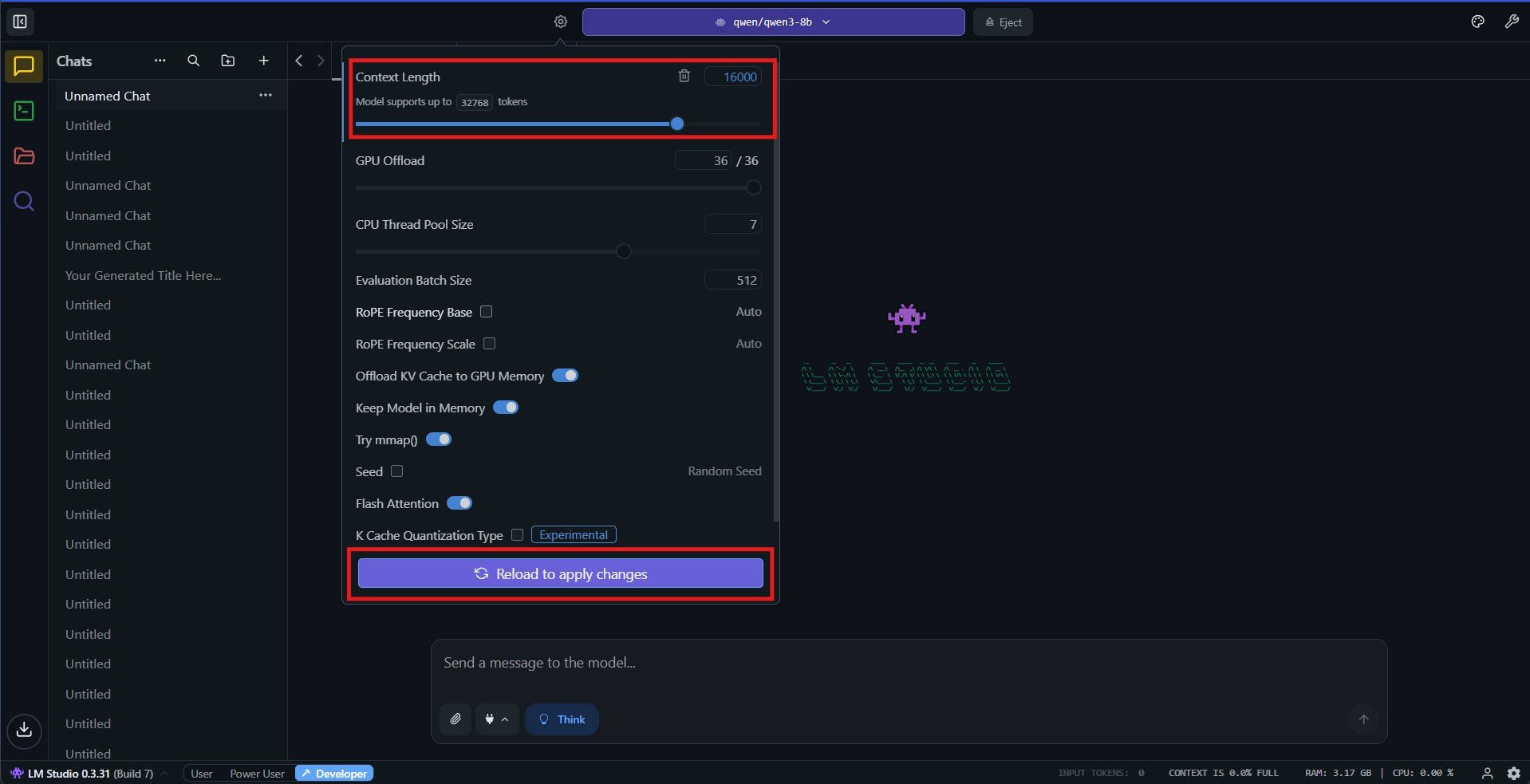
Pro tip: Start low (6K-8K) and test; LM Studio expand context gradually to monitor LM Studio context length VRAM spikes. We were able to load Qwen 3 8b model (4 bit quantized) with 32k context length on a system with 8 GB VRAM (RTX 4060) and 16 GB RAM. The model itself takes up 4.68 GB. The KV cache for 32k context takes up additional 5-6 GB (with Flash Attention i.e the default behafior) on LM Studio. With increasing context length, expect the performance of the model to degrade, both in terms of quality of output and the inference throughput. We have done extensive testing to understand the variation in performance across various context lengths in LM studio. Continue reading the article to learn more about it.
VRAM calculation tip: You can use our VRAM calcualtor or the built in Estimated Memory Usage feature shown in method 2.
Method 2: Increase Context Length in LM Studio: Intermediate method
Step 1: Load the model with custom parameters
In the Developer mode, click on the model picker dropdown, then turn on the toggle to manually choose model load parameters. After that, click on your preferred model.
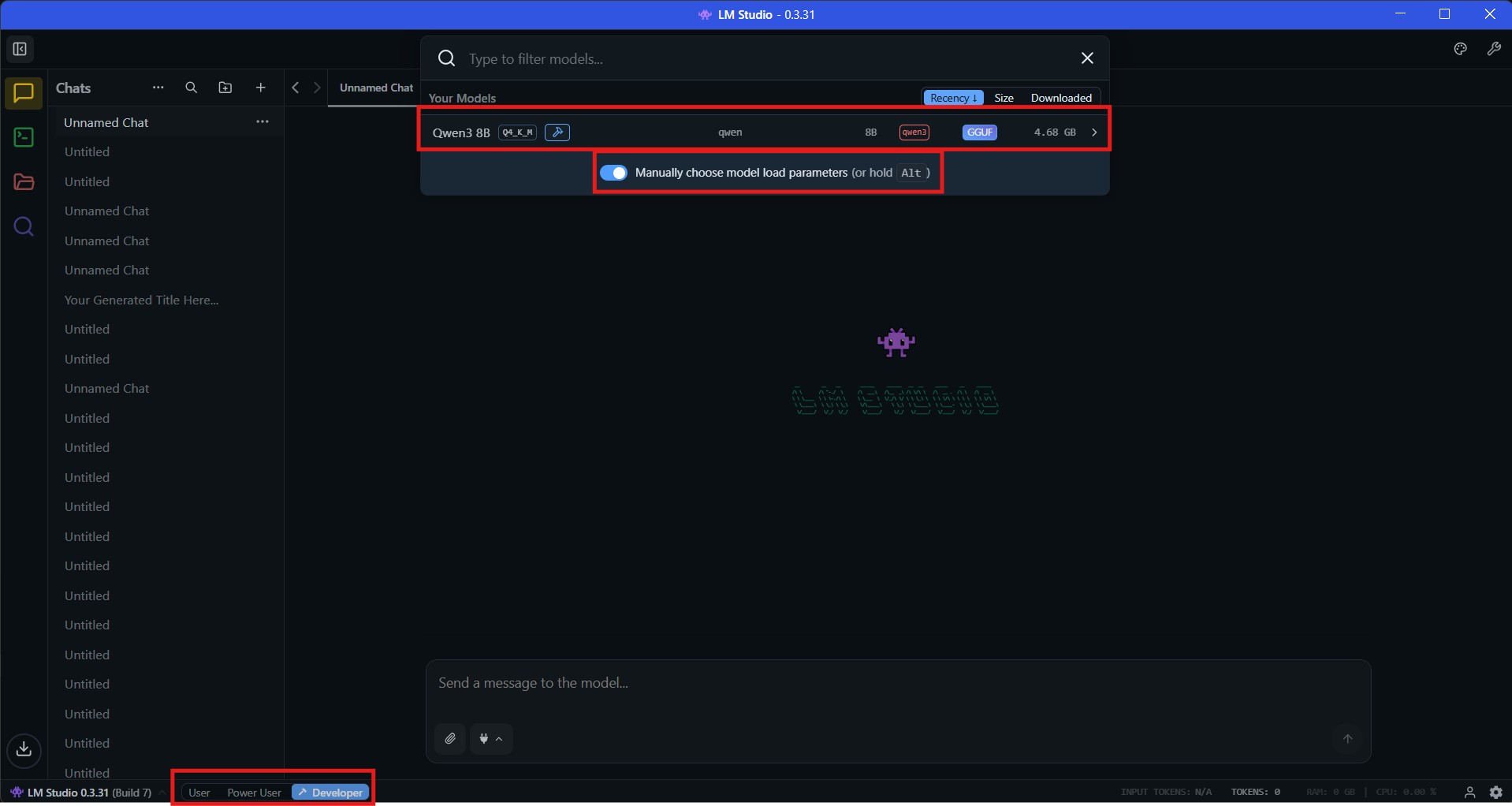
Step 2: Select custom parameters for increasing the context length
Use sliding the par or the text to select the required context length. Check the Estimated memory usage at the top, and click on the Load Model button. The model will load with the chosen context length.
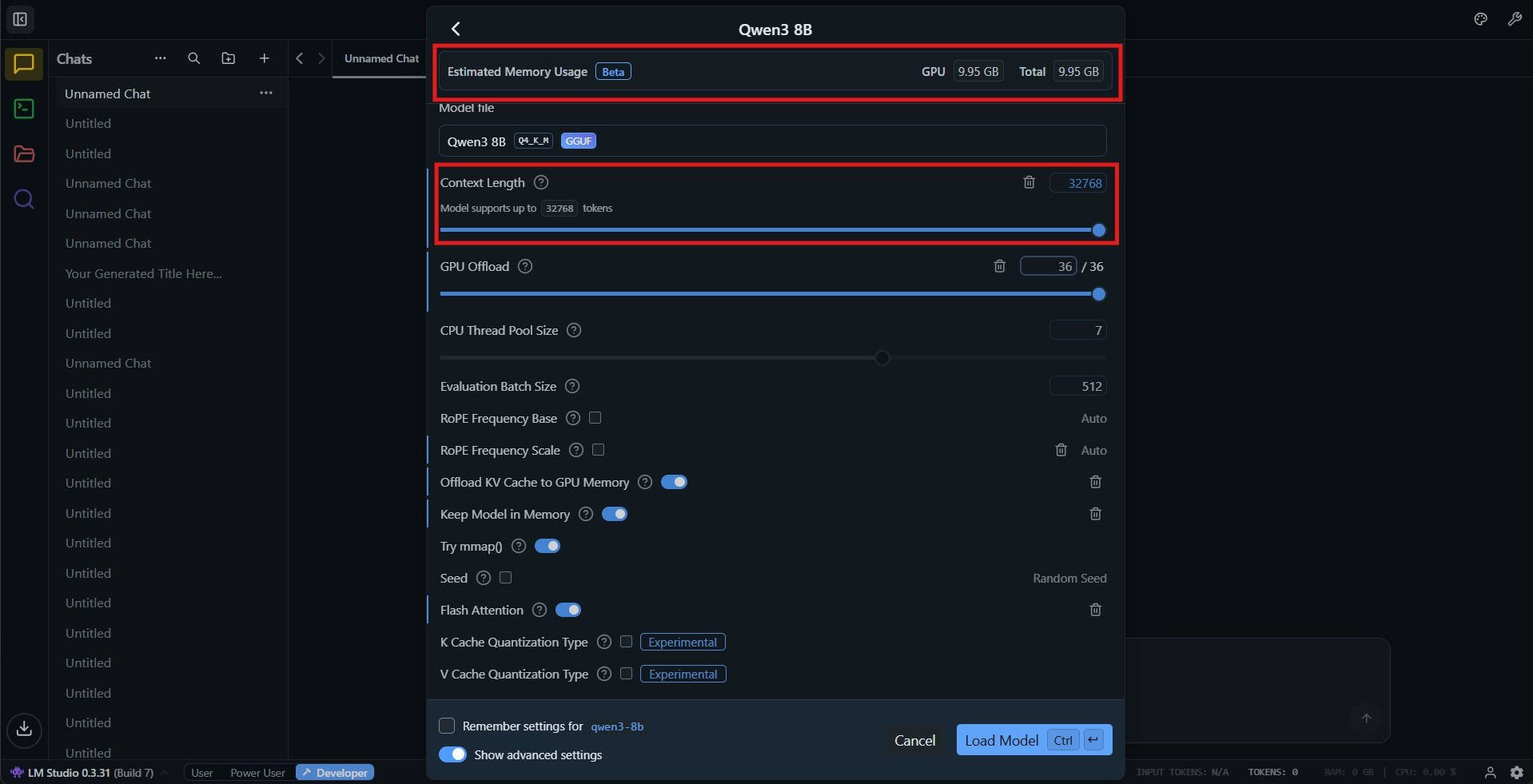
Other important parameters:
- Flash Attention: Decreases memory usage and generation time on some models.
- Offload KV Cache to GPU memory: Improves performance but requires more VRAM
You will be able to see the impact on VRAM under the Estimated Memory Usage on top when you toggle these options. in the later section, we discuss the impact of these options on performance so that you can pick the best settings for your requirements.
Method 3: Increase Context Length in LM Studio using CLI and SDK: Advanced method for Developers
Using CLI:
Step 1: Estimate Total Memory requirement before loading
Command:
lms load --estimate-only <model_key>
You can even use optional flags such as --context-length and --gpu
Example:
lms load --estimate-only qwen3-8b --context-length 16000
Output:
Model: qwen/qwen3-8b
Context Length: 16,000
Estimated GPU Memory: 8.73 GB
Estimated Total Memory: 8.73 GB
Step 2: Load the model with custom parameters to increase context length
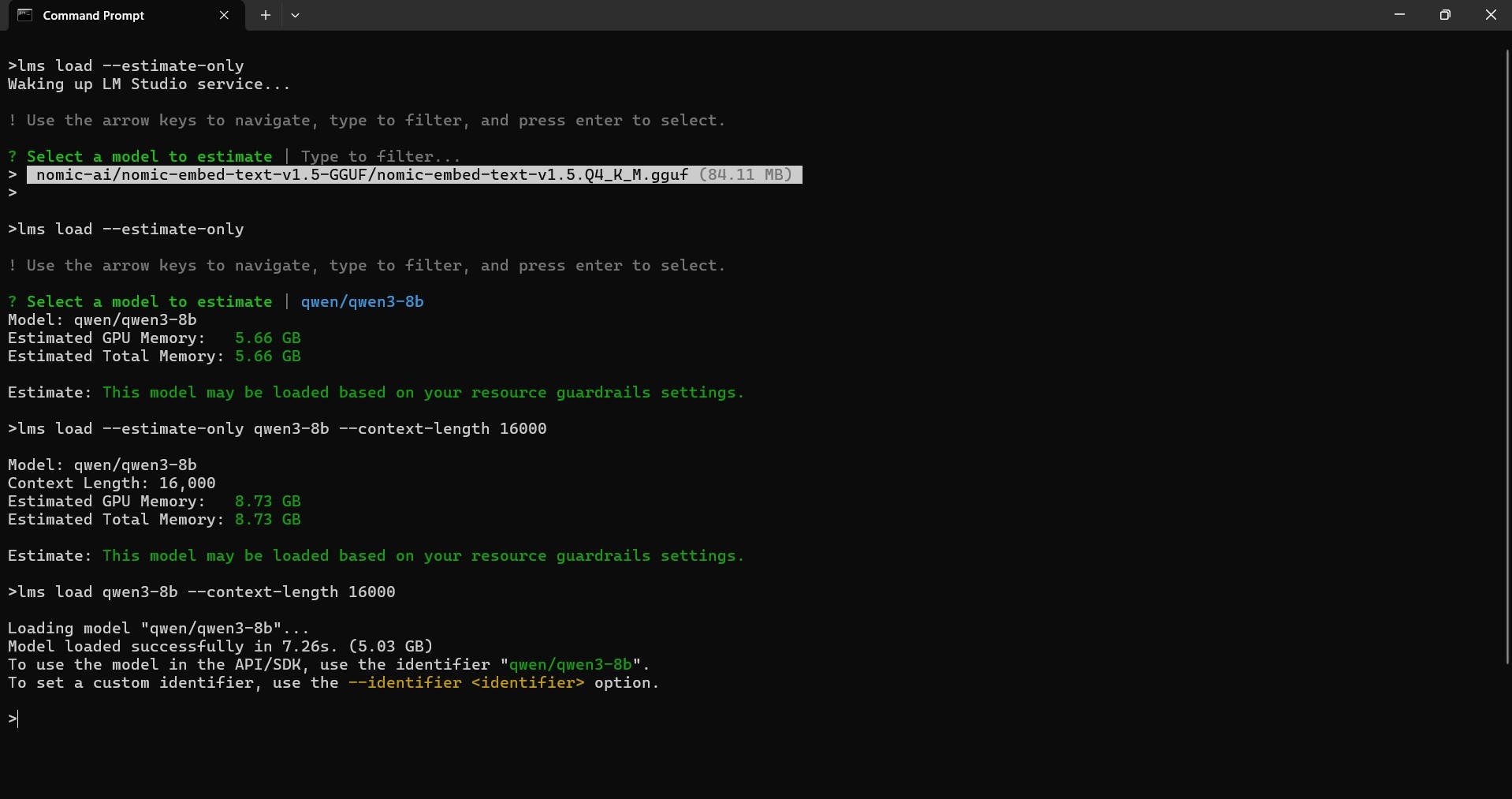
Command:
lms load <model_key>
Example:
lms load qwen3-8b --context-length 16000
Output:
Loading model "qwen/qwen3-8b"...
Model loaded successfully in 7.26s. (5.03 GB)
To use the model in the API/SDK, use the identifier "qwen/qwen3-8b".
To set a custom identifier, use the --identifier <identifier> option.
Troubleshooting CLI issues
These are the issues we encountered and steps to resolve them:
- Failed to initialize the context: failed to allocate buffer for kv cache
After the lms load command, we encountered this error a few times. This can happen sometimes especially when loading the model with higher context length. Retrying after freeing up some system RAM fixed it.
- "lms load --estimate-only" command failed to list models
Executing this command (without specifying the model) should list all the available models. For once, the command did not list the models available on our system. Opening the LM Studio desktop app then retrying resolved it.
Using SDK:
You can load models in LM studio with custom context length using the python and typescript SDKs as well.
Load model with custom context length in LM Studio TypeScript SDK example
import { LMStudioClient } from "@lmstudio/sdk";
const client = new LMStudioClient();
const model = await client.llm.load("qwen/qwen3-8b", {
config: {
contextLength: 16000,
},
});
// Now you can use the model for inference
const resp = await model.respond(
[
{ role: "system", content: "You are a concise assistant." },
{ role: "user", content: "Summarize key points about context length." },
],
{
maxTokens: 500,
temperature: 0.7,
}
);
console.log(resp.outputText);
Load model with custom context length in LM Studio Python SDK example
from lmstudio import Client
client = Client()
# Load model with custom context length
model = client.llm.load(
model="qwen/qwen3-8b",
config={
"contextLength": 16000,
},
)
# Use the loaded model for inference
resp = client.llm.respond(
model=model,
messages=[
{"role": "system", "content": "You are a concise assistant."},
{"role": "user", "content": "Explain the importance of context length in LLMs."},
],
config={
"maxTokens": 500,
"temperature": 0.7,
},
)
print(resp.output_text)
Links to the official sdk documentation:
- Typescript: https://lmstudio.ai/docs/typescript/api-reference/llm-load-model-config
- Python: https://lmstudio.ai/docs/python/llm-prediction/parameters
Optimizing Flash Attention and GPU KV cache offload configuration for best performance at larger context lengths
What is offload kv cache to gpu memory option in LM Studio?
The “Offload KV Cache to GPU Memory” toggle instructs LM Studio to allocate the cache in VRAM when possible, complementing the separate “GPU offload” control that decides how many model layers live on GPU vs CPU. With the toggle on, VRAM usage rises roughly in proportion to tokens and context window, but per‑token latency drops because attention reads are on‑device.
What is flash attention in lm studio?
Flash Attention in LM Studio enables an optimized attention kernel that computes attention in fused, blockwise operations on the GPU, reducing memory reads/writes and speeding up inference without changing model outputs.
Flash Attention enabled with GPU KV cache offload represents the optimal configuration for most use cases, delivering up to 45.59× speedup in Time to First Token (TTFT) and 40.77 tokens/second throughput at 4k context length. However, the benchmark reveals a significant performance anomaly at 32k context length, where counterintuitively, disabling GPU offload while maintaining Flash Attention produces superior results. This configuration-dependent behavior provides actionable guidance for practitioners deploying the Qwen 3 8B model on consumer-grade hardware.
Throughput (TPS) comparison at various context lengths and configurations:
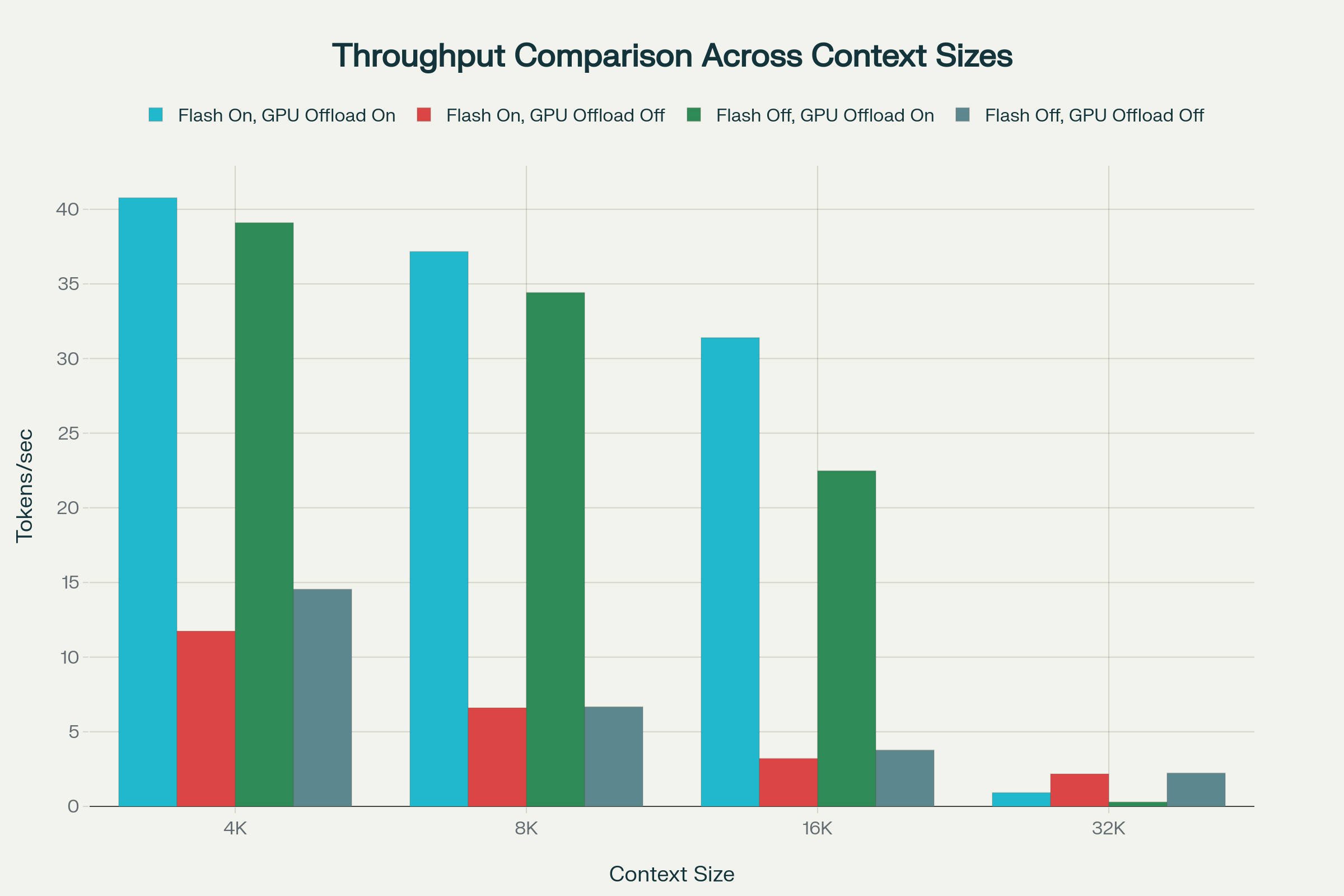
Throughput remains strong at 4K–8K when Flash Attention is enabled with GPU KV cache offload, sustaining roughly 37–41 tok/s and degrading gracefully by about 10% from 4K to 8K as memory pressure grows. At 16K, throughput slips further to the low 20s–31 tok/s depending on Flash/Offload, with Flash Attention providing a clear advantage over non-Flash paths. The steep drop arrives at 32K, where all configurations collapse to sub‑3 tok/s, indicating hard memory‑bandwidth and data‑movement limits regardless of compute headroom. Among the 32K options, placing KV on RAM (offload off) is the “least bad,” delivering around 2.2 tok/s because it allows some CPU–GPU pipeline overlap despite slower access. Overall, TPS behavior is governed first by KV placement and Flash efficiency, and then dominated by bandwidth and access patterns as context grows.
Memory consumption at various context lengths and configurations:

Total memory (VRAM + shared system RAM) grows steadily with context when KV is offloaded to GPU, reaching about 7–8 GB at 16K and pushing past 9–11 GB at 32K depending on Flash status. Configurations with offload off hold total memory flatter (≈5–6 GB) through 16K because the KV cache lives in system RAM, only climbing at 32K when the cache expands. The 8 GB threshold cleanly separates regions: below it, most usage is true VRAM; above it, spillover to shared RAM becomes visible and correlates with latency spikes. VRAM headroom tightens notably at 16K with offload on, leaving little capacity for transient buffers and tiling, which contributes to the subsequent performance collapse. Flash Attention helps by reducing the working set churn, but cannot prevent total memory from breaching practical limits at 32K on 8 GB cards.
TTFT (Time to first token) comparison at various context lengths and configurations:
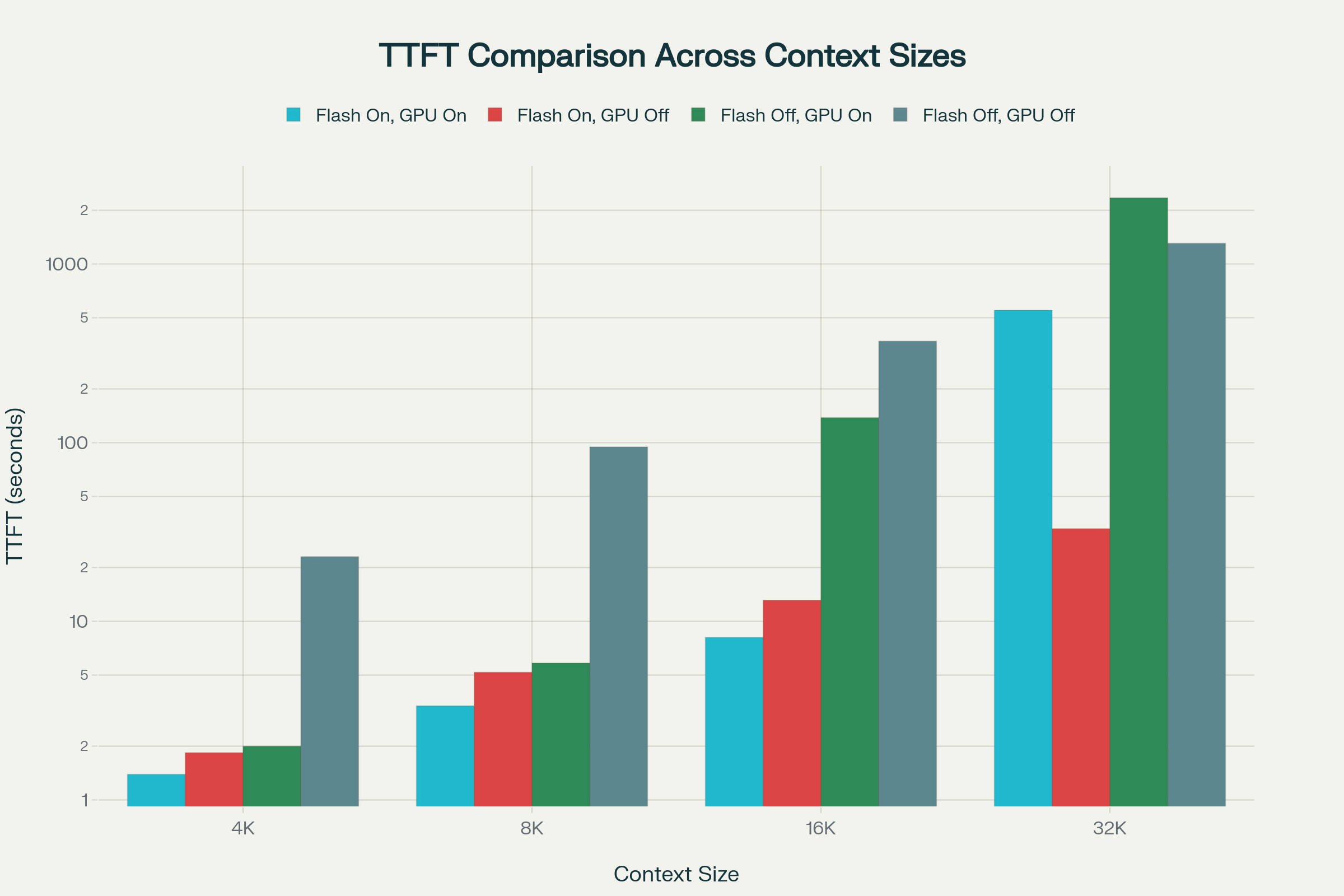
TTFT is excellent at 4K with Flash + Offload On (≈1.4–2.0 s), acceptable at 8K (≈3–6 s), and stretches at 16K (≈8–13 s) depending on configuration. With Flash disabled or KV offload disabled, TTFT penalties accumulate sooner as prefill and memory traffic increase. At 32K, TTFT diverges dramatically: Offload On can exceed 9–39 minutes depending on Flash, reflecting GPU memory stalls from massive KV access, while Offload Off reduces TTFT to tens of seconds by shifting KV to RAM and enabling some pipeline overlap. This showcases that TTFT is not just compute‑bound; it is highly sensitive to memory placement, bandwidth saturation, and the attention kernel’s IO behavior. In practice, keeping Flash on and avoiding VRAM saturation is essential to maintain predictable first‑token latency at larger contexts.
Handling LM Studio Context Overflow Policy: What Happens When Context is Full
When your chat exceeds the LM Studio max context length, context overflow kicks in. Without tweaks, the model might truncate inappropriately, losing key details like your system prompt.
Here's the breakdown of LM Studio context overflow policy options:
LM Studio context overflow policy (contextOverflowPolicy)
Stop at Limit (stopAtLimit): Stops generation when the context window is full. Stops immediately with stopReason=contextLengthReached (Context Length Reached).
Truncate Middle (truncateMiddle): Keeps the beginning and end by removing the middle of the conversation. System prompt and first user message are explicitly retained. Later end context is kept while middle is truncated. If the context window is full, LM studio continues generating output (tokens) while replacing the middle to fit the context window limit .
Rolling Window (rollingWindow): Maintains a rolling window by truncating older messages as new tokens are added. Older history is dropped. If the context window is full, LM studio continues generating output (tokens) while pruning old context to stay within the limit.
Choosing the right LM Studio context overflow policy
To examine the actual behavior, we ran some tests with Qwen 3 8b Q4 at 8k and 16k context lengths on RTX 4060 8 GB. Here is a table to summarize our observations on practical tests:
| Context (tokens) | Input tokens | Policy | Observed behavior |
|---|---|---|---|
| 8000 | 7539 | Rolling Window | Worked; generation proceeded with context reported at 108% full |
| 8000 | 7539 | Truncate Middle | Infinite generation loop observed |
| 16000 | 15504 | Rolling Window | Worked; generation proceeded with context reported at 104% full |
| 16000 | 15504 | Truncate Middle | Infinite generation loop observed |
While these options let the model continue generating response even when the context window is completely utilized, you must conduct thorough testing to check if it works reasonably well for your usecase. It may increase hallucinations, degrade instruction adherence as earlier system prompts drift out of scope, and amplify error cascades when important facts are pruned to make room for new tokens.
To mitigate this, cap max tokens per response, summarize or compress history before overflow, and prefer retrieval over stuffing long source text into the prompt so the active window stays focused and stable.
How to set context overflow policy (contextOverflowPolicy) in LM Studio
You can set the context overflow policy within the LM Studio Desktop app directly or using the
Set context overflow policy in LM Studio Desktop App (GUI)
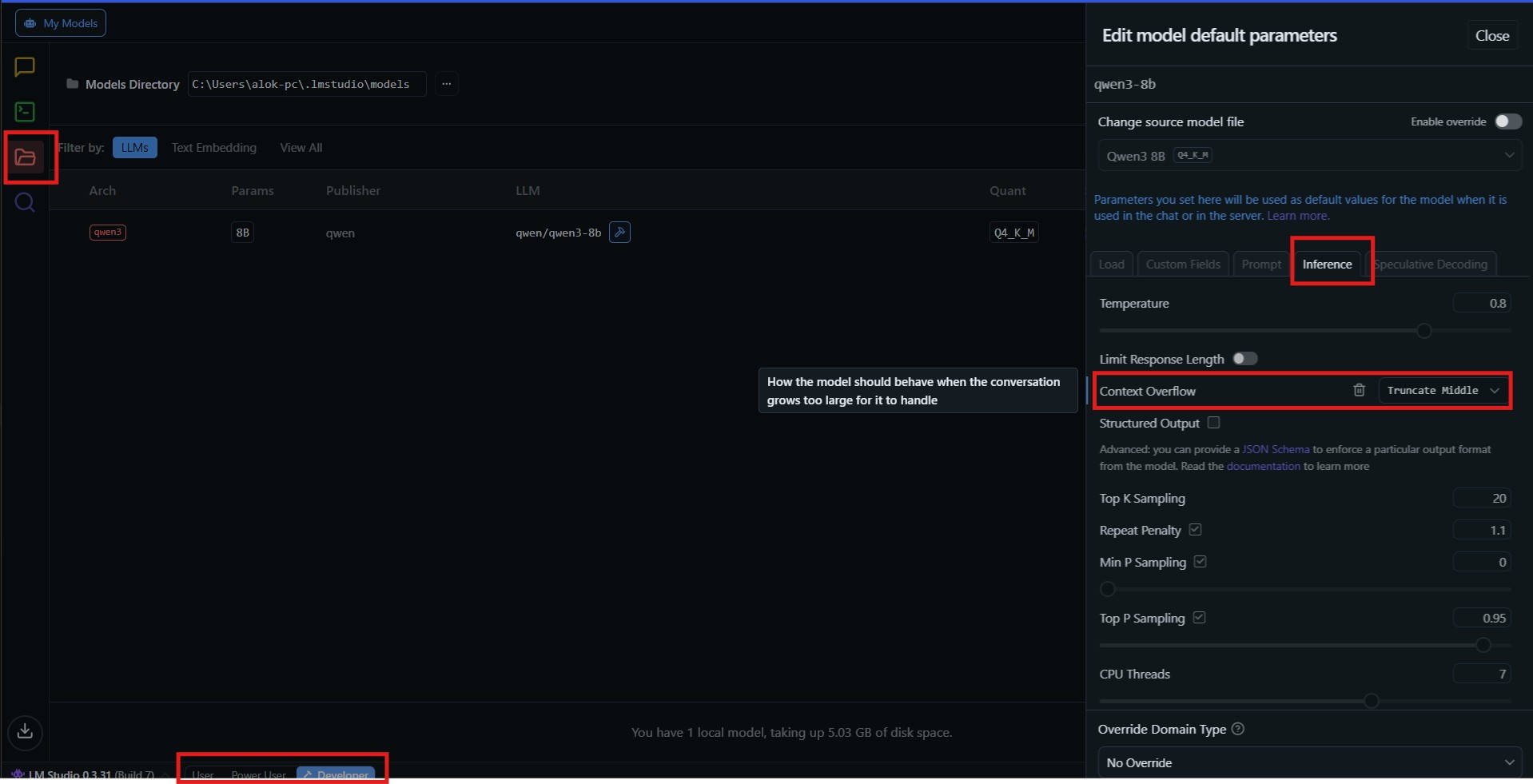
In the Developer/Power User mode, go to the 'My Models' section, under 'Actions' click on the settings (gear) icon next to the required model. Then, click on the 'Inference' tab to set the context overflow policy.
Set context overflow policy in LM Studio SDK for Developers
LLMPredictionConfigInput is the set of per-request generation parameters you pass to LM Studio when calling a model; it covers decoding controls (temperature, top‑p, top‑k), stopping behavior, context overflow handling via contextOverflowPolicy, structured output, penalties, and advanced features like speculative decoding. Allowed contextOverflowPolicy values are stopAtLimit, truncateMiddle, and rollingWindow.
Set context overflow policy in LM Studio Javascript SDK example
import { LMStudioClient } from "@lmstudio/sdk";
const client = new LMStudioClient();
const model = await client.llm.load("qwen/qwen3-8b");
const resp = await model.respond(
[
{ role: "system", content: "You are concise." },
{ role: "user", content: "Summarize KV cache vs RoPE scaling." },
],
{
contextOverflowPolicy: "rollingWindow",
maxTokens: 500,
temperature: 0.8,
topPSampling: 0.9,
}
);
console.log(resp.outputText);
Set context overflow policy in LM Studio Python SDK example
from lmstudio import Client
client = Client()
resp = client.llm.respond(
model="qwen/qwen3-8b",
messages=[
{"role": "system", "content": "You are a concise assistant."},
{"role": "user", "content": "Explain context overflow policies."},
],
config={
"contextOverflowPolicy": "rollingWindow", # stopAtLimit | truncateMiddle | rollingWindow
"maxTokens": 500,
"temperature": 0.9,
"topPSampling": 0.9,
},
)
print(resp.output_text)
What is GPU Offload in LM Studio? A Beginner's Breakdown
GPU Offload in LM Studio means running some or all of a model’s transformer layers on your GPU (VRAM) instead of the CPU (system RAM), so those layers execute with GPU kernels while the remaining layers, if any, stay on CPU; the more layers that fit in VRAM, the bigger the speedup, with best performance when all layers (plus KV cache and attention ops) fit on the GPU.
GPUs accelerate matrix multiplies and attention much more than CPUs, and VRAM bandwidth is far higher than system RAM; placing more layers on GPU increases tokens/sec until VRAM is saturated.
If a model is too big for VRAM, partial offload lets you run it anyway and still gain speed on the GPU-handled layers versus pure CPU, but there’s a penalty from transfers and any CPU-bound layers; the ideal remains a smaller quant or smaller model that fully fits.
If you don’t set a GPU offload value, LM Studio will auto-select an offload amount that tries to use as much dedicated VRAM as is safe for the model and your hardware, often resulting in the maximum number of layers being placed on the GPU. If the entire model can’t fit, it will reduce the layer count to fit VRAM and keep the remainder on CPU RAM.
You can change the LM Studio GPU offload preference setting using the GPU Offload slider shown in the screenshots of Method 1 and Method 2 above or using --gpu flag while loading the model using CLI. Official details on cli: https://lmstudio.ai/docs/cli/load
Here is an example if partial GPU Offload with Typescript SDK:
import { LMStudioClient } from "@lmstudio/sdk";
const client = new LMStudioClient();
const model = await client.llm.load("qwen/qwen3-8b", {
config: {
contextLength: 8192,
gpu: {
offloadRatio: 0.5, // Offload 50% of layers to GPU
},
},
});
const resp = await model.respond(
[
{ role: "system", content: "You are concise." },
{ role: "user", content: "Summarize KV cache vs RoPE scaling." },
],
{
contextOverflowPolicy: "rollingWindow",
maxTokens: 500,
temperature: 0.8,
topPSampling: 0.9,
}
);
console.log(resp.outputText);
LM Studio v0.3.14+, multi-GPU support lets you split loads across cards. Check out the official post https://lmstudio.ai/blog/lmstudio-v0.3.14 to learn more.
Conclusion
Increasing context length in LM Studio is simple to try but requires deliberate memory hygiene. Use the GUI first to set a modest custom context length, watch the Estimated Memory Usage, and only ramp up further after testing. If you need more control for development, use the CLI/SDK to estimate and load with --context-length and the gpu flags, then toggle Offload KV Cache to GPU Memory and the LM Studio GPU offload slider for best throughput.
Quick checklist:
- Start with a safe context size (6K–12K), then scale upward only after checking latency.
- Watch VRAM using “Estimated Memory Usage” and stop increasing once you approach your GPU limit.
- Enable Flash Attention for faster prefill and stable throughput at medium context lengths.
- Use GPU offload only when VRAM allows; disable it for very large contexts (16K–32K+) on 8GB cards.
- Prefer rollingWindow for chat-style workloads; avoid truncateMiddle unless you’ve tested it thoroughly.
- If GPU offload fails or behaves oddly, free system RAM, re-run --estimate-only, and reload the model.
Use our VRAM Calculator to Estimate VRAM requirements for various context lengths:
FAQ
What's the default context window size in LM Studio?
LM Studio doesn't have a single universal default context window size, it varies based on the specific model being loaded. The application typically reads the default from each model's configuration file, but common defaults you'll encounter are 2048 or 4096 tokens. LM Studio determines the default context length by reading the model's configuration metadata, specifically the max_position_embeddings value. For MLX-converted models, LM Studio often defaults to 2048 tokens when it can't accurately detect the model's capabilities.
How do I check my model's maximum context length?
LM Studio displays the maximum supported context length in the model load interface and also on the model discover page in the model README for some of the models (click on model name). You can also check the model's Hugging Face card.
What's the difference between context length and embedding size?
Context length determines how much conversation history the model can reference, while embedding size refers to token vector dimensions. Context length is adjustable up to model limits and affects memory usage, while embedding size is fixed by architecture.
How do I permanently save context settings in LM Studio?
Save the model configuration with your custom context length settings. LM Studio remembers your load configs per model, so running the same model again will use previously set parameters by default. Easiest way to do it: Go to 'My Models' and click on the gear (settings) icon next to your model. Here you would be able to edit all the default parameters of the model.
Can I use RoPE scaling in LM Studio?
Yes, LM Studio supports RoPE scaling in the prediction config for models beyond their native context length limits, allowing extrapolation for longer contexts on many architectures.
What happens when context overflows?
LM Studio offers multiple overflow policies: Stop at Limit (halt input), Truncate Middle (preserve prompts, cut middle), or Rolling Window (maintain recency). Choose based on your use case to handle long conversations gracefully.
How do I optimize GPU offload settings?
Set the GPU offload slider from 0-100% in load configs. Start low (20-50%) for partial offload on low-VRAM cards, go full for maximum speed. Monitor VRAM usage and balance with context length to avoid OOM errors.
What's the impact of context length on VRAM?
Each token adds bytes to the KV cache, roughly 4-6GB VRAM bump per 32K increase on 8B models. Use quantization (4-bit) and partial offload for large contexts on consumer hardware. Monitor with nvidia-smi or LM Studio's built-in tools.
How do I troubleshoot GPU offload issues?
Check VRAM limits, ensure updated drivers (CUDA 12.4+), use quantized models for better offload, and restart LM Studio after changes. Common fixes include reducing layers/context or enabling Flash Attention.
Can LM Studio handle 1M+ token contexts?
With sufficient VRAM (120GB+ setups), LM Studio can handle massive contexts on models like Qwen2.5-1M. Use partial quantization and high-end GPUs for optimal performance on extreme contexts.
Are context length and context window the same in LM Studio?
Yes, context length and context window are the same thing in LM Studio and in LLM terminology generally. They are interchangeable terms that refer to the maximum number of tokens a model can process at once.
How much VRAM do I need to increase context length in LM Studio?
For an 8B parameter model with 4-bit quantization, expect to use approximately 4-5 GB for the model weights plus an additional 1.5-2 GB per 8K tokens of context length with Flash Attention enabled. At 32K context, you'll need around 10-11 GB total (model + KV cache). A 16GB GPU comfortably handles most scenarios, while 8GB GPUs work well up to 16K context.
What's the difference between Flash Attention and GPU KV cache offload in LM Studio?
Flash Attention optimizes how attention computations are performed on the GPU, reducing memory usage and improving speed without changing outputs. GPU KV cache offload determines whether the key-value cache is stored in VRAM (faster access) or system RAM (slower but uses less VRAM). For best performance at 4K-16K contexts, enable both. At 32K+ on 8GB GPUs, disable GPU offload while keeping Flash Attention enabled.
Why does my LM Studio model generate slowly at large context lengths?
Large context windows exponentially increase memory bandwidth requirements. At 32K tokens, throughput can drop from 40 tokens/second to under 3 tokens/second due to memory saturation. The KV cache must be read for every generated token, creating a bottleneck. Solutions include using a smaller context length, enabling Flash Attention, or upgrading to a GPU with more VRAM and bandwidth.
What does "failed to allocate buffer for kv cache" mean in LM Studio?
This error indicates insufficient memory (VRAM or system RAM) to store the KV cache for your requested context length. Solutions: reduce context length, enable quantization, free up system RAM by closing other applications, reduce GPU layer offload, or use a smaller/more quantized model. Retrying after freeing memory often resolves the issue.
Should I use rollingWindow or truncateMiddle for context overflow in LM Studio?
Use rollingWindow for chat-style conversations where older messages become less relevant. It maintains recent context by dropping old messages. Use truncateMiddle cautiously for tasks where both the beginning (instructions) and end (recent info) matter, but middle content is less critical. Testing shows truncateMiddle can cause infinite generation loops at near-full contexts, so thorough testing is essential.
Can I increase LM Studio context length without using more VRAM?
Yes, by disabling "Offload KV Cache to GPU Memory," the KV cache moves to system RAM instead of VRAM. This trades speed for capacity, you'll see slower generation but can handle larger contexts on GPUs with limited VRAM. At 32K context on an 8GB GPU, this approach maintains ~2 tokens/second versus complete failure with GPU offload enabled.