Running large language models (LLMs) locally has become more accessible with user-friendly tools like LM Studio, but VRAM (video RAM) remains the primary hardware bottleneck for anyone aiming for smooth, fast AI inference. This guide details exactly how much VRAM you need for running models in LM Studio, how configuration and quantization affect memory requirements, and what to do if your GPU isn't enough. Links to other essential VRAM articles on LocalLLM.in will help you dive deeper into advanced memory strategies.
TL;DR: How Much VRAM Do You Need for LM Studio?
- Entry-level (4–6GB VRAM): Can run 3–4B parameter models (Q4 quantization) with moderate context window (about 4k tokens comfortably).
- Mid-range (8–12GB VRAM): Supports 7–14B models, e.g., Llama 3 8B, Qwen 3 8B, and similar at 4- or 5-bit quantization - the sweet spot for most users.
- High-end (16–24GB+ VRAM): Ideal for 13–30B models at higher quality, larger context windows for reliable RAG and light weight coding tasks.
- Workstation (48–80GB+ VRAM): Required only for extremely large models (70B+) or running smaller models at FP16 precision without quantization.
For ultimate precision in planning your setup, use the interactive VRAM calculator designed specifically for local LLM deployment in LM Studio and other popular backends.
LM Studio VRAM Usage: What Really Matters
- Model Weights: Core parameters loaded onto VRAM. Quantization (Q4, Q5, Q6, etc.) has a large impact. Lower quantization means smaller VRAM use.
- KV Cache: For every token processed (input or output), a portion of VRAM is reserved for attention cache. Longer context = higher VRAM demand.
- System Overhead: The backend (llama.cpp, CUDA, Vulkan, etc.) adds roughly 0.5–1GB to VRAM use.
Example Table: VRAM Required in LM Studio (Approximate)
| Model Size | Quantization | VRAM Needed | Typical GPU |
|---|---|---|---|
| 3B | Q4_K_M | 3–4GB | GTX 1650, RTX 3050 |
| 7B–8B | Q4_K_M | 6–8GB | RTX 3060, 4060 |
| 13B | Q4/Q5 | 9–12GB | RTX 3060 Ti, RTX 4070 |
| 30B | Q4 | 20GB+ | RTX 3090, RTX 4090 |
| 70B | Q4 | 40GB+ | RTX 6000, A100, H100 |
Always check the quantization format. Q4_K_M is the memory efficiency gold standard for consumer hardware.
Practical VRAM Test: LM Studio with Qwen 3 8B Q4_K_M on RTX 4060 on Windows 11
To demonstrate LM Studio's VRAM usage in practice, I conducted a real-world test on an NVIDIA RTX 4060 with 8GB VRAM. This mid-range graphics card represents a common consumer setup perfect for validating our VRAM guidelines.
Test Setup
- OS: Windows 11
- Hardware: NVIDIA RTX 4060 (8GB VRAM)
- Model: Qwen 3 8B Q4_K_M quantization (4.68GB GGUF file size)
- Context Length: 4096 tokens
- Acceleration: Full GPU offload (offload ratio: 1)
- CPU Threads: 7
- Task: Generate article content on "Local LLMs" (simple prompt)
Performance Results
Generation Stats:
- Tokens/second: 42.55
- Time to first token: 0.103 seconds
- Total generation time: 39.32 seconds
- Prompt tokens: 15
- Generated tokens: 1673
- Total tokens: 1688
This performance shows excellent real-time responsiveness, well within the sweet spot for conversational AI use.
VRAM Usage Analysis
With the model preloaded, the RTX 4060 handled the 8B parameter Qwen 3 Thinking model perfectly within its 8GB VRAM envelope. The test confirmed:
- Model Fit: The 4.68GB Q4_K_M model loaded entirely in VRAM without RAM overflow
- KV Cache: 4096 context window didn't trigger significant memory pressure
- GPU Utilization: Full offload (offload ratio 1) maintained optimal performance
- No Spilling: No RAM fallback indicates the hardware matched the model's requirements
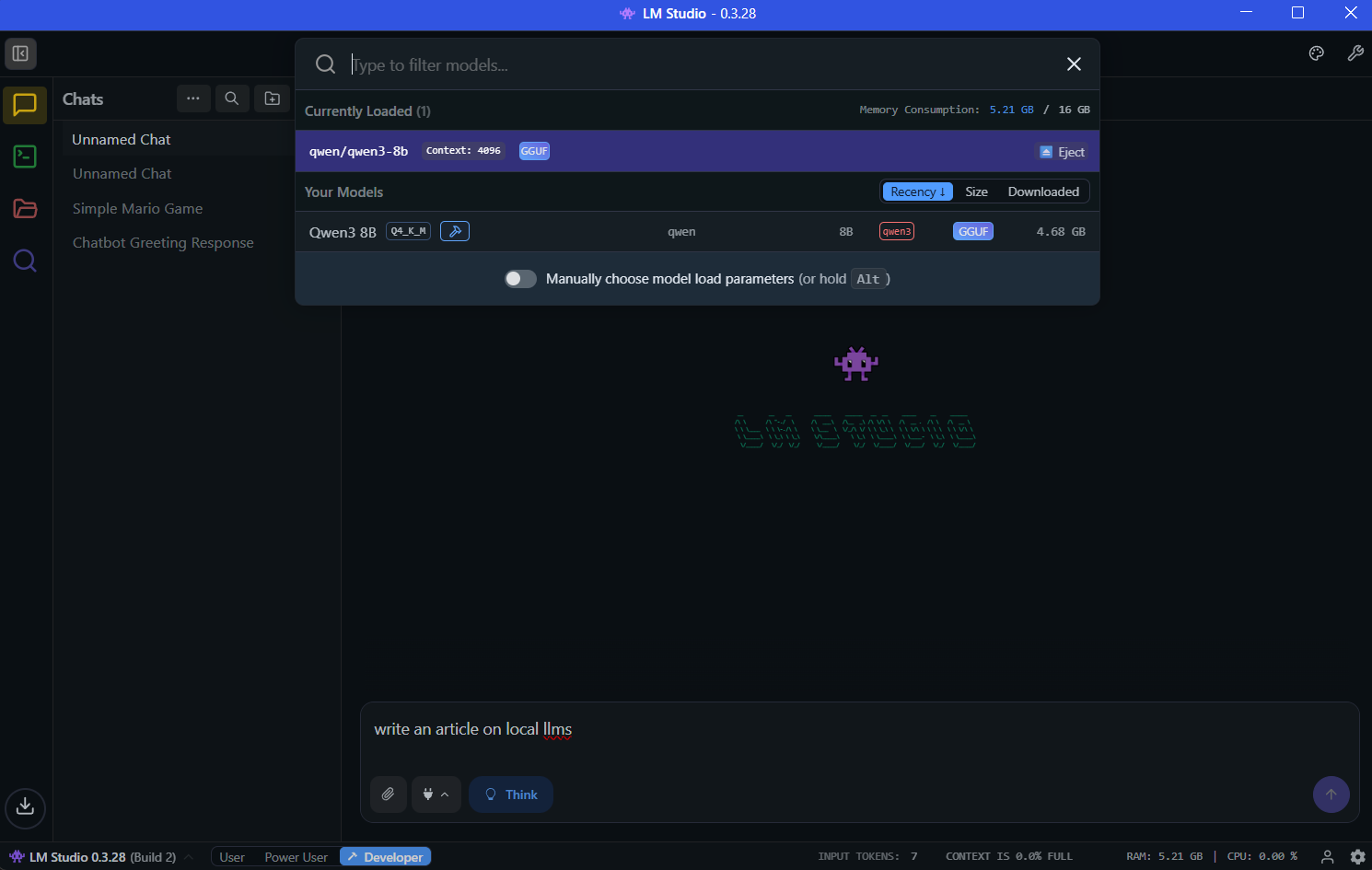

Why This Matters: This real-world test validates our mid-range (8-12GB VRAM) category recommendations. The RTX 4060 with 8GB VRAM comfortably handles 7-8B models like Qwen 3 8B Thinking in Q4_K_M, proving that you don't always need high-end GPUs for modern local LLM inference. Qwen 3 8B Thinking is a very capable model for it's size and quitable for a lot of light weight tasks such as question answering and generating code snippets. It can also easily generate fully functional basic html pages, however expecting it to work with coding assistants like cline and kilo code will be an over kill. The combination of efficient quantization and proper GPU configuration delivers both speed (42+ tokens/second) and memory efficiency.
How LM Studio Handles VRAM and GPU Offload
- Automatic Layer Offload: LM Studio lets you choose how many layers to offload to GPU. You can split heavy models across VRAM and fast system RAM (at a serious performance penalty if system RAM is slow).
- Performance Impact: If VRAM is exceeded, LM Studio will "spill" to RAM, and response speed can be up to 30x slower compared to fitting entirely in VRAM. I was able to manage about 10 tps with a 14b model split across gpu and cpu, while it delivered about 4 fps when loaded to cpu only on windows 12th gen core i7 12700H CPU.
- Integrated GPU Support: iGPUs use system RAM as VRAM. On AMD with VGM (Variable Graphics Memory), you can scale up dedicated memory, but always expect lower throughput than discrete GPUs.
LM Studio System Requirements and Compatibility
LM Studio supports multiple operating systems with specific hardware requirements that vary based on your platform. Here are the exact system requirements for optimal performance:
macOS Requirements
Minimum Requirements:
- Processor: Apple Silicon (M1, M2, M3, M4) - Intel Macs are currently not supported
- Operating System: macOS 13.4 or newer
- RAM: 8GB minimum, but 16GB+ strongly recommended
- Storage: 20GB+ free space for models and cache
For MLX Models:
- macOS 14.0 or newer required
- Apple Silicon optimized for maximum performance with MLX backend
Performance Notes: 8GB Macs can run smaller models but should stick to modest context sizes and 3B-7B parameter models. For serious LLM work, 32GB+ RAM is ideal for larger models.
Windows Requirements
Minimum Requirements:
- Architecture: Both x64 and ARM64 (Snapdragon X Elite) supported
- Processor: AVX2 instruction set support required for x64 systems
- Operating System: Windows 10 or Windows 11
- RAM: 16GB minimum, 32GB+ recommended for larger models
- GPU: 4GB+ dedicated VRAM recommended for optimal performance
- Storage: 20GB+ free space (SSD recommended)
GPU Support: NVIDIA RTX series (including RTX 50-series with CUDA 12.8) and AMD graphics cards fully supported.
Linux Requirements
Minimum Requirements:
- Distribution: Ubuntu 20.04 or newer (distributed as AppImage)
- Architecture: x64 only (aarch64 not yet supported)
- Processor: AVX2 instruction set support required
- RAM: 16GB minimum, 32GB+ recommended
- GPU: 8GB+ VRAM recommended for dedicated NVIDIA/AMD cards
- Storage: 20GB+ free space
Important Note: Ubuntu versions newer than 22.04 are not extensively tested. The Linux version is currently in beta.
LM Studio VRAM Optimization Strategies
- Use 4-bit (Q4) models for best balance of RAM/VRAM and output quality.
- Reduce context length if running into VRAM limits - remember KV cache grows linearly with tokens. For detailed guidance on increasing or managing context length in LM Studio, see our comprehensive How to Increase Context Length in LM Studio guide.
- Use the VRAM calculator to estimate usage before downloading massive models.
- Consider CPU-only inference as a fallback for very large models where real-time speed is not a priority, but prepare for slower response.
- Overflowing into system RAM is possible, but dramatically reduces speed.
For additional benchmarks and best practices by hardware, read Best GPUs for Local LLM Inference in 2025 and Best Local LLMs for 8GB VRAM (2025).
Frequently Asked Questions
Can LM Studio run without a GPU or with low VRAM?
Yes, LM Studio can run models entirely on CPU without a GPU, though performance will be significantly slower. If your model exceeds available VRAM, LM Studio offers an automatic overflow option that shifts excess data to system RAM. However, this comes with a severe performance penalty—tests show models running 30x slower when overflowing into system RAM compared to fitting entirely in VRAM. For low VRAM situations, use aggressive quantization (Q3 or Q4) and stick to smaller parameter models.
What happens if my model is too large for my VRAM in LM Studio?
When a model exceeds available VRAM, LM Studio can automatically offload excess layers to system RAM through a simple toggle option. While this allows larger models to run on modest hardware, the performance penalty is substantial. Benchmark tests show a Gemma 3 27B model that overflowed into 6GB of system RAM ran at only 1.57 tokens/second compared to 46.45 tokens/second for a smaller model that fit entirely in VRAM. The system remains functional but response generation becomes noticeably sluggish.
Does LM Studio work with AMD GPUs or only NVIDIA?
LM Studio supports both NVIDIA and AMD GPUs, as well as Apple Silicon Macs with integrated graphics. NVIDIA GPUs generally offer the widest software compatibility and best performance due to mature CUDA support. AMD users should ensure they have 6GB+ VRAM and updated drivers. On AMD systems with Variable Graphics Memory (VGM), you can allocate system RAM as dedicated VRAM—for example, converting up to 96GB of system RAM into discrete graphics memory on supported processors.
What is MLX in LM Studio and should I use it on my Mac?
MLX is Apple's open-source machine learning framework optimized specifically for Apple Silicon's unified memory architecture. LM Studio version 0.3.4 and newer includes native MLX support alongside the traditional llama.cpp backend. On Apple Silicon Macs, MLX offers significant advantages: models load 3x faster (under 10 seconds vs 30 seconds for llama.cpp), achieve 26-30% higher token generation speeds, and use less memory due to unified memory optimization. For example, Llama 3.2 1B runs at approximately 250 tokens per second on M3 Max with MLX. MLX requires macOS 14.0 (Sonoma) or newer, while regular llama.cpp models work on macOS 13.4+.