How to Enable Internet Access for Local LLMs with MCP and APIs
Local LLMs (or open source and open weight llms) let you keep inference and data on-prem, but they don't have built-in access to the live web. Give them safe, auditable internet access and you get private inference plus up-to-date facts.
This guide covers practical recipes (from 10-minute demos to production pipelines), exact tools and code (including LM Studio, Ollama, Playwright, Crawl4AI/Firecrawl, Exa, Chroma/Qdrant/Weaviate), operational hardening (ngrok for dev, nginx/OAuth/WAF for production), and legal/do-harm crawling rules. All advice checked against current docs and reporting as of Sept 2025.
Kindly navigate to the relavent section as per your requirement using the contents button on the bottom right corner, or keep scrolling to understand all the solutions sequencially. In the later sections, I have attached a beginner friendly video tutorial to add Tavily web serch MCP to LM studio.
TL;DR - Which route should you take?
Curious non-dev / quick demo: Run LM Studio (GUI) on your laptop; use its Local LLM Service / OpenAI-compatible API to call local models and feed it search results from DuckDuckGo or SerpAPI. Great for private, GUI-driven experimentation.
Developer / small app: Run LM Studio or Ollama as a local server (keep bound to 127.0.0.1), implement search → fetch → extract → embed → retrieve → model pipeline. Use Chroma or Qdrant for embeddings.
Production at scale / team: Use a pipeline with robust crawling (Crawl4AI/Firecrawl), neural SERP (Exa) or self-hosted crawler + extractor, persistent vector DB (Qdrant/Weaviate), an API gateway/reverse proxy with OAuth2 and TLS, rate limits and WAF. Use ngrok only for short-lived development/demo access; do not rely on it for production.
Note: LM Studio is now a first-class local server + SDK option (GUI + headless + SDKs for Python/TS), and it's extremely convenient for laptop/mini-PC workflows. It's worth considering before building heavy infra.
1) What "giving internet access to a local LLM" actually means
Local models don't browse the web. Giving them internet capability means building a tooling layer that retrieves external information and feeds it into the model's context. However, there are two fundamental approaches depending on the complexity and requirements:
Path 1: Real-Time Search (Simple, No Vector DB)
This lightweight approach retrieves fresh information on-demand without storing anything:
- Search - Query a search API (DuckDuckGo, SerpAPI, Exa) or web crawler to find relevant pages
- Fetch & Render - Download target pages; render JavaScript when needed using tools like Playwright
- Extract - Pull main content, metadata, published date, and author information
- Inject & Generate - Pass extracted content directly into the LLM's context window along with the user's query; model generates response and cites sources
Best for: Quick lookups, current events, one-off queries, demos, and applications where storage overhead isn't justified. The entire flow happens at query time—no pre-indexing required.

Path 2: RAG Pipeline (Complex, With Vector DB)
This approach pre-processes and stores documents for semantic retrieval, enabling more sophisticated question-answering over large knowledge bases:
- Search - Find candidate pages (search API, crawler)
- Fetch & Render - Download and render pages
- Extract - Pull content and metadata
- Embed & Store - Generate vector embeddings and store them in a vector database (Chroma, Qdrant, Weaviate)
- Retrieve & Generate - At query time, perform semantic search to find relevant document chunks, inject them into context, and let the LLM synthesize an answer with citations
Best for: Domain-specific knowledge bases, internal documentation search, applications requiring semantic understanding across large document collections, and scenarios where repeated queries benefit from pre-indexed data.
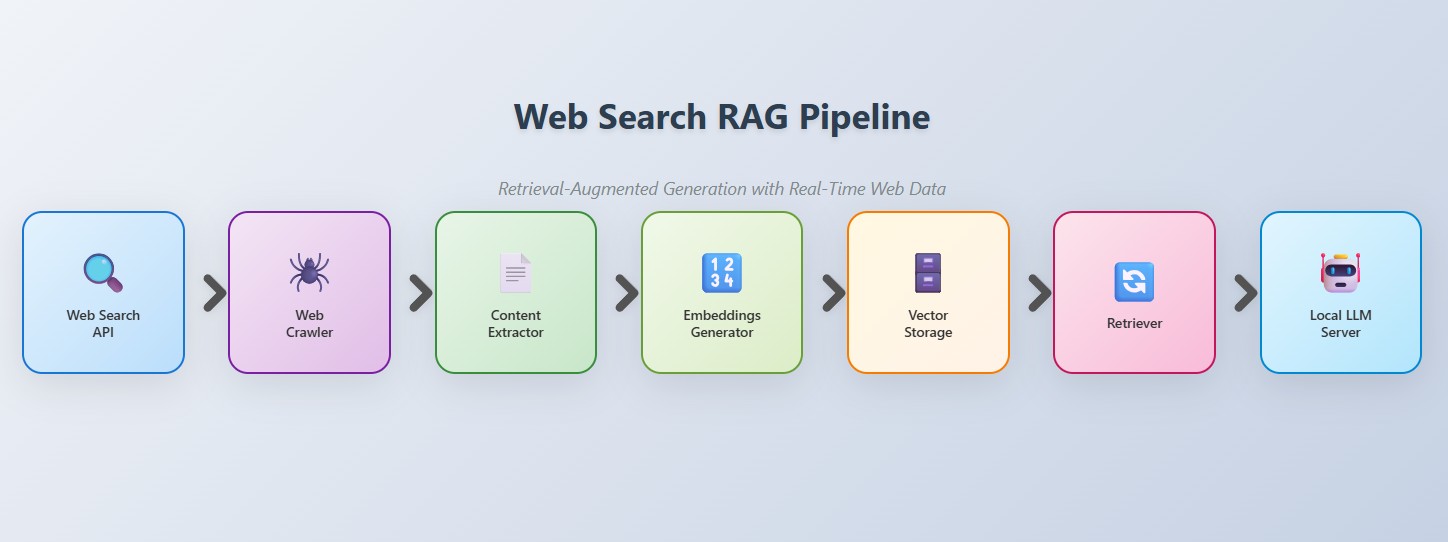
Choosing Your Path
Start with Path 1 for simple requirements—getting current weather, news, or answering straightforward factual questions. Graduate to Path 2 when building knowledge assistants, customer support bots, or any application that needs to understand relationships across hundreds or thousands of documents.
2) Key Tools for Enabling Internet Access to Your Open Source Local LLM
Giving your local LLM internet access requires three components: a model runner to serve your LLM, web data tools to fetch and process content, and integration protocols to connect them. Here's a practical breakdown of the essential tools.
Model Runners
LM Studio: Cross-platform desktop app with GUI and OpenAI-compatible API endpoints. Supports MCP (Model Context Protocol) since June 2025, enabling LLMs to connect to external data sources and tools through standardized "MCP servers" without custom integration code. Includes official SDKs (Python/JS), CLI tools, and works well on newer Intel Arc and AMD GPUs via Vulkan. Older Intel HD Graphics (pre-2020) may perform worse with GPU acceleration than CPU-only. Best for rapid prototyping and GUI-focused workflows. For detailed setup, see the comprehensive local LLM setup guide.
vLLM: High-throughput inference engine optimized for production deployments with concurrent users. Uses PagedAttention for efficient memory management and excels at batch processing. Returns responses with lower latency under heavy load compared to alternatives. Best for server environments serving multiple simultaneous requests.
llama.cpp: Lightweight C++ inference library focused on CPU efficiency and cross-platform compatibility. Runs models without GPU requirements through optimized SIMD instructions, making it accessible on resource-constrained hardware. Supports GGUF format and provides the foundation for many other tools. Best for minimal dependencies, embedded systems, or CPU-only deployments.
Ollama: CLI-first model runner with REST API and intuitive model management. Simpler than LM Studio but less GUI-focused. Best for scriptable server-style deployments.
Jan: Open-source ChatGPT-like interface with 70+ pre-installed models and local document chat. Works offline and supports remote API fallback.
GPT4All: Privacy-focused runner with 250,000+ monthly users, offline operation, and enterprise licensing.
Web Data Collection Tools
To feed your LLM real-time internet content, choose from these specialized tools:
Crawl4AI (open source): Purpose-built for extracting LLM-ready markdown from websites. Handles JavaScript rendering, provides structured extraction, and runs entirely self-hosted. Best for full control over crawling infrastructure.
Firecrawl: Managed web data API with open-source components. Returns clean, LLM-ready outputs while handling JavaScript rendering, anti-bot measures, and sitemap processing. Offers free tier and paid plans. Best for teams prioritizing speed-to-market.
Playwright: Headless browser automation for rendering JavaScript-heavy pages. Foundation for building custom crawling solutions.
Search and Discovery APIs
MCP-Enabled Search (via Model Context Protocol)
Tavily MCP: Real-time web search with AI-powered content extraction and intelligent filtering. Provides structured, LLM-optimized results through MCP servers. Best for semantic search integrated directly into model workflows.
Brave Search MCP: Privacy-focused search integration through official MCP server. Enables web searches with enhanced privacy controls. Leading search tool for Claude MCP applications and RAG pipelines.
API-Based Search
Perplexity Search API (launched September 2025): Real-time web search with index covering hundreds of billions of pages. Returns fine-grained, pre-ranked snippets optimized for AI consumption rather than full documents. Updates tens of thousands of documents per second for freshness. Pricing: $5 per 1,000 requests. Best for grounding LLMs in current, accurate web data.
Exa: Neural search API using embedding-based semantic search instead of keyword matching. Returns results optimized for AI processing. Best when semantic relevance matters more than keyword-based results.
Google Search API: Traditional web search through Google Custom Search API. Provides access to Google's index with programmable search capabilities.
Bing Search API (deprecated): Microsoft retired Bing Search and Bing Custom Search APIs on August 11, 2025. Microsoft now recommends "Grounding with Bing Search" through Azure AI Agents for real-time web data access. Existing Bing Search API users must migrate to Azure AI Agents or alternative providers.
Storage Infrastructure
Vector Databases: Store and retrieve embeddings for semantic search and RAG workflows.
Chroma: Simple local/persistent vector DB, ideal for getting started. Qdrant and Weaviate: Production-grade options with advanced filtering and scaling.
Development and Exposure
ngrok: Secure HTTP tunneling for development and webhook testing. Use only for ephemeral sharing and demos—never for production without additional authentication and rate limiting.
3) Practical Examples - Local llm internet access templates (web search)
Below are practical, copy-paste examples and templates. Pick the path that matches your comfort and goals.
A - Non-dev: 10-minute setup for integrating web search for LM Studio with MCP (GUI)
Install LM Studio and Enable MCP Support
Download LM Studio (version 0.3.17 or higher) and open it. Load a function-calling capable model from the catalog - pick a 7B-14B parameter model optimized for your hardware (Qwen3, Gemma3, or granite-4-h-tiny work well). You can refer to this blog post for a detailed LM Studio Web Search MCP Integration Tutorial.
Set up Web Search with Tavily MCP (Easiest Method)
Tavily offers the smoothest onboarding with 1,000 free monthly searches and no payment details required:
Sign up at tavily.com and grab your API key (click "Generate MCP Link")
In LM Studio, go to Settings → Program tab → Install → Edit mcp.json
Paste this configuration:
{
"mcpServers": {
"tavily-remote": {
"command": "npx",
"args": [
"-y",
"mcp-remote",
"https://mcp.tavily.com/mcp/?tavilyApiKey=YOUR_API_KEY_HERE"
]
}
}
}
Save, toggle the server "On" in settings, and test with: "What's the weather in London today?"
You can also refer this video for a step by step tutorial on adding web search MCPs with LM Studio:
Alternative: Brave Search MCP
For higher limits (2,000 queries/month) and independent search indexing, Brave Search provides a privacy-focused alternative. Configuration requires an API key from brave.com/search/api and uses environment variables instead of URL parameters.
📖 For complete step by step instructions with screenshots, troubleshooting, and advanced configurations, see our comprehensive LM Studio Web Search MCP Integration Tutorial. In this blog we show how you can very easily integrate Tavily and Brave Search MCPs in LM Studio. We have covered both, the GUI method (for non devs and beginners) and also the API method to use MCP servers with LM Studio Open AI like API.
B - Developer: Simple programmatic RAG with Ollama + Chroma
Why: programmatic control + persistent retrieval quality.
Steps (high level):
- Start Ollama server and pull a model (e.g.,
ollama pull llama3.2). - Use a search API (duckduckgo-search or Exa if you have keys) to get candidate URLs.
- Fetch and (if necessary) Playwright-render those pages; extract main text with BeautifulSoup or Crawl4AI.
- Generate embeddings with an embedder (sentence-transformers or Ollama's embedding model) and add to a Chroma PersistentClient.
- At query time: run an embedding on the user query → vector similarity search → build RAG prompt from top K docs → call Ollama's chat completion endpoint.
Example code sketch (Python):
# sketch: query → retrieve → Ollama
import requests, json
from sentence_transformers import SentenceTransformer
import chromadb
# 1) Ollama endpoint (OpenAI compatible)
OLLAMA_API = "http://localhost:11434/v1" # your local Ollama server with --api-format openai
MODEL_NAME = "llama3.2" # your Ollama model
# 2) embedder & chroma (assumes persist set up)
embedder = SentenceTransformer("all-MiniLM-L6-v2")
client = chromadb.PersistentClient(path=".chromadb")
collection = client.get_or_create_collection("web_content")
def retrieve_rag(query, top_k=4):
q_emb = embedder.encode([query]).tolist()
results = collection.query(query_embeddings=q_emb, n_results=top_k, include=["documents","metadatas","distances"])
# format context
ctx = "\n\n".join([f"Source: {m['url']}\n{d}" for d,m,d in zip(results["documents"][0], results["metadatas"][0], results["distances"][0])])
prompt = f"Using the sources below, answer: {query}\n\n{ctx}\n\nAnswer concisely and cite sources (URLs)."
resp = requests.post(f"{OLLAMA_API}/chat/completions",
json={"model": MODEL_NAME,"messages":[{"role":"user","content":prompt}]})
return resp.json()
Notes: Chroma's PersistentClient is purpose-built for local persistence; Ollama supports OpenAI compatibility when started with --api-format openai.
📖 Check out this simpler example that discusses integration of tavily and brave search MCP using the Open AI like API Endpoints. For complete step by step instructions with screenshots, troubleshooting, and advanced configurations, see our comprehensive LM Studio Web Search MCP Integration Tutorial.
C - Production / scale: crawler + Exa/Firecrawl + Qdrant + Gateway
High level design:
- Managed crawling (Firecrawl) or self-hosted Crawl4AI + Playwright for rendering.
- Ingest into a vector DB (Qdrant/Weaviate) with metadata and text.
- Use Exa (neural SERP) for high-quality query→document candidate ranking or use your retrieval service.
- LLM inference behind a secure API gateway (nginx/Traefik with OAuth2/OIDC via oauth2-proxy or a managed API gateway). Apply rate limits + WAF.
When to pick managed vendors: choose Firecrawl/Exa if your team doesn't want to run and maintain scraping infra; they handle rendering, anti-bot, scalability and provide LLM-ready outputs - but data flows through third-party infra, so review privacy implications. For detailed production deployment architectures, see our comprehensive local LLM setup guide.
4) Crawling & extraction: practical notes & code patterns
When to render vs. simple fetch
- If the page is server-rendered (news articles, blogs) a simple requests fetch + BeautifulSoup usually suffices.
- For SPA sites, infinite scroll, or paywalled JS-loaded content use Playwright. Playwright can be used inside a crawler (Crawl4AI integrates these ideas).
Crawl4AI & Firecrawl
- Crawl4AI is open source and focuses on producing LLM-ready Markdown/JSON extraction pipelines; good for teams that like self-hosting and customization.
- Firecrawl is a managed web-data API that returns structured outputs (markdown/json/screenshot) and handles traversal/anti-bot. Useful if you need production stability quickly.
Practical extraction pattern (pseudo)
search(query) -> candidate_urls
For each URL:
fetch(url)
if is_js_heavy(url) -> playwright.render(url)
extract_main_content(html) (article body, date, authors, images)
Normalize & chunk content (2-3 KB chunks, overlap) → embed & store
Chunking and overlap matters: choose chunk size to match your embedder/context window tradeoffs.
5) Vector DBs & RAG: practical how-tos
Why You Need This (vs. Direct Web Search Every Time)
The Problems with Direct Retrieval:
- Slow & expensive: Every question triggers new web requests and re-processing
- Context overload: Feeding entire 10,000-word articles to your LLM hits context limits and wastes tokens on irrelevant content
- No memory: Can't connect information across previous searches or build knowledge over time
- Poor precision: Crude text matching misses semantically relevant content that uses different wording
The Solution: Vector databases store your web content as "embeddings" - mathematical representations that capture meaning. Instead of re-crawling or dumping entire pages, your LLM searches your local knowledge base and retrieves only the most relevant chunks.
Real benefit: Ask "What did the AI safety paper say about alignment?" The LLM instantly finds relevant chunks from papers you crawled weeks ago, without re-downloading anything. Then ask a follow-up like "How does that compare to the recent GPT-4 findings?" - it can connect information across multiple sources instantly. For a complete guide on PDF RAG workflows, see our Best local LLMs for PDF chat and analysis in 2025.
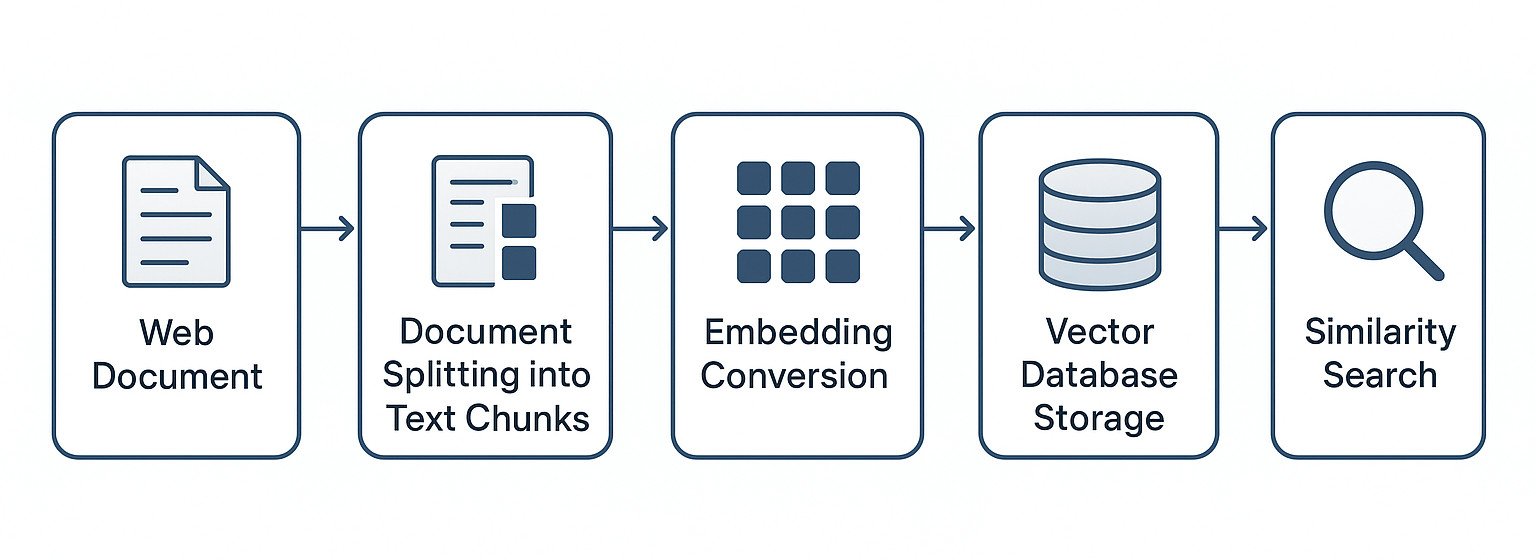
When you need this: You're asking repeated questions about the same domains, building research over time, or want sub-second responses instead of waiting for web crawls.
Database Selection by Use Case
Chroma - Best for local development: PersistentClient stores embeddings to disk; zero setup, perfect for prototyping. Lightweight and simple API.
Qdrant - High-performance choice written in Rust, designed for real-time updates: Known for advanced filtering (pre-filtering), quantization, multi-tenancy, and resource-based pricing. Self-hosted or managed cloud.
Weaviate - Known for its GraphQL API, optional vectorization modules, and strong hybrid search capabilities. Good for complex schemas and multi-modal data.
Chunking Strategy (Critical for Quality)
Embedding smaller chunks instead of entire documents means you only retrieve the most relevant document chunks, resulting in fewer input tokens and more targeted context.
Recommended approach:
- Chunk size: 512-1024 tokens for most use cases; balance between speed and accuracy depends on your specific use case
- Overlap: 20-50 tokens between chunks to preserve context across boundaries
- Strategy: Use semantic chunking that respects document structure (paragraphs, sections) rather than simple character splitting
Essential Metadata for Production
Store these fields for transparent citations and filtering:
metadata = {
"url": "https://example.com/article",
"title": "Article Title",
"published_date": "2025-01-15",
"crawl_date": "2025-09-03",
"source_domain": "example.com",
"content_type": "article" # article, blog, paper, etc.
}
Code Pattern (Qdrant Example)
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
client = QdrantClient(":memory:") # or persistent: QdrantClient("http://localhost:6333")
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Ingest with metadata
client.upsert(
collection_name="web_docs",
points=[{
"id": doc_id,
"vector": embedder.encode(chunk_text).tolist(),
"payload": metadata
}]
)
# Query with filtering
results = client.search(
collection_name="web_docs",
query_vector=embedder.encode(query).tolist(),
query_filter={"must": [{"key": "source_domain", "match": {"value": "trusted-site.com"}}]},
limit=5
)
Operational Best Practices
- Reindex strategy: Set TTLs (7-30 days) for web content; batch reindex during low-traffic hours
- Backup: Vector indices are expensive to rebuild - backup collection snapshots regularly
- Monitoring: Track retrieval latency, embedding quality (measure recall@k), and index size growth
- Filtering: Use tenant isolation, encryption, private networking, region pinning, and auditable filters for production deployments
6) Exposing the service: ngrok (dev) → reverse proxy & OAuth (prod)
ngrok - when & how to use it (dev only)
ngrok is an excellent developer tool to temporarily expose a local endpoint over TLS for demos, webhook testing or pair-programming. It provides inspection, authentication, and enterprise features. Do not use ngrok as a production gateway for an exposed LLM without tight access control and logged audit trails.
Quick ngrok dev example:
ngrok authtoken <YOUR_TOKEN>
ngrok http 1234 # expose LM Studio or your local API from 1234 -> public URL
Security notes: rotate tokens and never embed sensitive keys or secrets in a demo tunnel. Organizations often restrict or disallow uncontrolled tunnel daemons because they can exfiltrate traffic. Huntress and others have documented malicious usage of tunnels.
Production exposure - recommended stack
Put the model server on 127.0.0.1 (local only). Use nginx / Traefik to terminate TLS, enforce rate limits, and forward to localhost. Use oauth2-proxy (or API Gateway) for OAuth2/OIDC auth + RBAC. Add WAF rules or vendor-grade WAF if exposed publicly.
Example nginx snippet and oauth2 flow earlier in the guide is a good template.
7) Security & prompt injection: the must do list
Prompt injection is the #1 risk for internet-enabled LLMs. OWASP ranks prompt injection as the top LLM risk (LLM01) and provides mitigation patterns you must follow. The threat is real: when a model ingests web content, adversarial instructions embedded in pages can cause it to leak data or obey malicious commands.
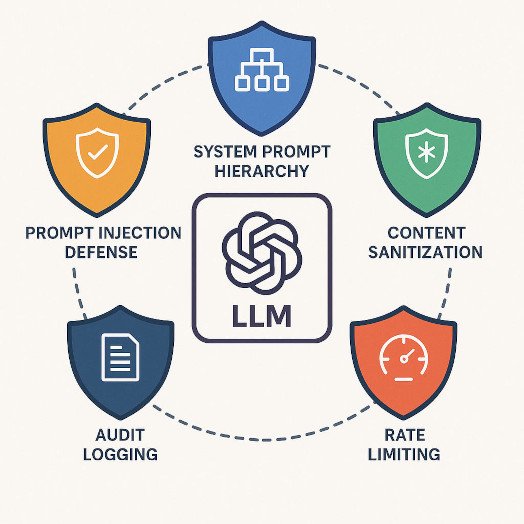
Mandatory defenses:
- Defense in depth - sanitize web content BEFORE it enters the prompt; remove code blocks, hidden HTML comments, and lines that look like instructions.
- System prompt hierarchy - require a system prompt that explicitly denies external instruction execution (and do not allow user content to override system prompts). Consider hard-coded system prompts at the gateway or the server level (not in user-editable files).
- Jailbreak detectors - run a small classifier or safety LLM on the retrieved content to flag suspicious instruction-like text before passing it to the main model.
- Tool & action whitelists - when the LLM can call tools (e.g., run a crawler, send emails, or execute code), restrict allowed actions and validate outputs.
- Logging & audit - maintain immutable audit logs (hashed identifiers) for every retrieval + LLM response to support incident response. Redact PII before long retention.
- Rate limits & quotas - to prevent resource exhaustion and automated abuse.
- Red-team - run prompt-injection corpora and adversarial tests regularly.
Takeaway: don't rely on any single defense. OWASP's Top-10 for LLM apps is the best starting point and provides layered mitigations.
8) Legal & ethical checklist for crawling/scraping
- robots.txt: Respect it by default for polite crawling. Some sites use robots.txt to signal blocking - honor it.
- Terms of Service: Check site TOS for prohibited scraping or commercial reuse. Some publishers have explicitly restricted AI training reuse in recent disputes; major publishers are negotiating licensing deals with big AI firms in 2024-2025. If in doubt, consult counsel.
- Rate limiting: use polite crawl rates and exponential backoff. Don't DDoS.
- Attribution & citations: always surface sources in user answers and link back. This is both ethical and reduces hallucination litigation risk.
- Licensing & paid content: do not re-publish paywalled or licensed content without permission - consider licensing if you rely on that content materially. Publishers are actively litigating and making business deals for AI access in 2024-2025.
9) Performance & hardware (practical 2025 guidance)
For detailed hardware selection and performance benchmarks, see our comprehensive GPU buyer's guide for local LLM inference in 2025.
- Small models (<=7B): 8-16GB VRAM (or CPU for light testing).
- Medium (7-20B): 16-32GB VRAM.
- Large (30B-70B): 32-80GB VRAM or multi-GPU with offload + quantization.
- Huge (>70B): typically multi-GPU or inference services (H100s, etc.) and advanced kernel libraries. Quantize (8-bit / 4-bit) where possible.
Operational tips:
- Use quantized GGUF models when possible.
- For RAG, keep retrieved context size small: retrieve only the most relevant chunks and let the model synthesize.
- Use caching to avoid repeated crawls and reduce cost.
10) Ready-made architectures & checklists
Minimal local prototype (safe)
Browser / CLI → local script:
search (DuckDuckGo) → fetch (requests) → LM Studio OpenAI API (localhost)
LM Studio runs as headless server on 127.0.0.1
Good for demos and experimentation.
Production recommended
Internet
→ CDN / DNS
→ Reverse Proxy (nginx/Traefik) - TLS (Let's Encrypt)
→ oauth2-proxy / Auth Provider (OIDC) - RBAC, MFA
→ API gateway / Rate limits / WAF
→ Retriever microservice (Qdrant / Weaviate)
→ Crawler/Extractor (Playwright + Crawl4AI or Firecrawl)
→ LLM inference (LM Studio / Ollama) - bound to localhost
→ Logging + Monitoring (Prometheus, Grafana, audit logs)
Checklist before going live
- Model server bound to 127.0.0.1 (not 0.0.0.0) unless behind a secured gateway.
- OAuth2/OIDC in front (don't use simple home-rolled API key stores in memory).
- Prompt-injection scanner & system prompt locked down.
- Logs redacted & encrypted; backups for vector DB.
- Legal/TOS review for large-scale crawling.
11) Common pitfalls (learned the expensive way)
- Opening ports without auth - do not run OLLAMA_HOST=0.0.0.0:11434 or open LM Studio to the internet without gateway auth. That makes your LLM a public API.
- Trusting scraped text blindly - it may contain prompt injections, inaccurate facts, or timestamps that mislead the RAG system. Sanitize always.
- Storing raw PII in logs/caches - logs are often forgotten; redact and limit retention.
- Assuming managed crawlers are "privacy free" - managed APIs (Exa, Firecrawl) solve engineering but route your queries through third parties - important for compliance decisions.
12) Final recommendations (how to move forward)
- Prototype locally with LM Studio (GUI + CLI) - get comfortable with models and their capabilities. Enable headless server for programmatic access.
- Add retrieval (Chroma or Qdrant) - persistent embeddings improve accuracy and speed.
- Use Crawl4AI (self-hosted) or Firecrawl (managed) for robust extraction when you outgrow simple fetch+BS4.
- Harden: reverse proxy + OAuth + rate limits + OWASP mitigations before exposing anything to external users. Don't forget legal review for large-scale crawling.
Frequently Asked Questions
What does "internet access for a local LLM" actually mean?
Local models don't browse the web directly. You give them internet capability by building a tooling layer that includes search (find candidate pages), fetch & render (download pages with JavaScript rendering when needed), extract (pull main content and metadata), store/index (create embeddings and store in vector DB), retrieve & RAG (retrieve relevant documents and synthesize answers with citations), and expose (wrap model behind secure API).
Which is the easiest way to give a local LLM internet access for experimentation?
For non-developers or quick demos, LM Studio is the best option. Install LM Studio, use its model catalog to pick a model, enable Local LLM Service (headless mode), and run a simple Python script that queries DuckDuckGo or SerpAPI, fetches pages, and passes snippets as context to LM Studio via its OpenAI-compatible API.
What tools should I use for a production-scale local LLM with internet access?
For production deployments, use a pipeline with robust crawling (Firecrawl or Crawl4AI + Playwright), neural SERP (Exa), persistent vector DB (Qdrant/Weaviate), and a secure API gateway with OAuth2, TLS, rate limits, and WAF. Never use ngrok for production without additional security controls.
What are the key security considerations for local LLMs with internet access?
Prompt injection is the #1 risk. Implement defense in depth by sanitizing web content before it enters prompts, using system prompts that deny external instruction execution, running jailbreak detectors on retrieved content, implementing tool/action whitelists, maintaining audit logs, and applying rate limits. Follow OWASP's Top-10 for LLM apps.
What's the difference between using Ollama vs LM Studio for local LLM internet access?
Ollama is ideal for lightweight, CLI-first local inference with a REST API, perfect for developers who want programmatic control and minimal overhead. LM Studio offers a polished GUI, MCP tool integration, auto-suggested quantized models, and better laptop compatibility with integrated GPUs. Choose Ollama for server-style deployments and LM Studio for user-facing demos, rapid prototyping, or when you need GUI-driven experimentation and structured tool integration.
How do I choose between Chroma, Qdrant, and Weaviate for vector storage in my local RAG setup?
Use Chroma for local development and prototyping - it's the simplest with zero-setup PersistentClient and automatic disk storage. Choose Qdrant for high-performance production workloads requiring advanced filtering, quantization, and real-time updates. Select Weaviate for complex schemas, GraphQL APIs, and strong hybrid search capabilities. Start with Chroma for simplicity, migrate to Qdrant for performance, and use Weaviate for advanced query patterns.
When should I use Playwright vs simple requests for fetching web content?
Use simple requests + BeautifulSoup for server-rendered pages like news articles and blogs where content is available in initial HTML. Use Playwright when fetching client-side heavy websites: single-page applications (SPAs), infinite scroll content, JavaScript-rendered content, or sites with anti-bot protections. Playwright excels at rendering dynamic content but requires more compute resources and setup than basic requests.
What are the security differences between using ngrok vs nginx/oauth2-proxy for exposing my local LLM?
ngrok is designed for temporary, development-only exposure with basic token auth and inspection - never use it for production without enterprise controls. nginx/oauth2-proxy provides production-grade TLS termination, OAuth2/OIDC authentication, rate limiting, WAF integration, and access control. Use ngrok for short-lived demos and nginx/oauth2-proxy for any public-facing deployment requiring security, auditing, and compliance.
What specific prompt injection mitigations should I implement for crawled web content?
Sanitize content before prompts (remove code blocks, hidden HTML, suspicious instruction patterns), use hard-coded system prompts denying external instruction execution, deploy jailbreak detectors on retrieved content, implement tool/action whitelists, maintain audit logs of retrievals and responses, apply rate limits, and follow OWASP's Top-10 for LLM apps. Run regular red-team tests with adversarial prompt corpora.
How does vLLM compare to Ollama and LM Studio for serving local LLMs with internet access?
vLLM is a high-performance serving engine optimized for large-scale LLM inference, offering features like dynamic batching, optimized CUDA kernels, and support for FP8 quantization, making it ideal for GPU-heavy production environments. Unlike Ollama's lightweight CLI-first approach or LM Studio's GUI and MCP integration for rapid prototyping, vLLM prioritizes throughput and scalability, supporting advanced features like paged attention for efficient memory use. For internet access, vLLM can be integrated into the same search → fetch → extract → embed → retrieve pipeline as Ollama or LM Studio, using tools like Crawl4AI or Exa. Choose vLLM when you need to serve large models (20B+) at scale with high request volumes, but for simpler setups or GUI-driven experimentation, Ollama or LM Studio are more approachable.