Qwen3-Next-80B-A3B: The Future of Efficient Local LLMs
Efficient 80B LLM capability is finally within reach: Qwen3‑Next‑80B‑A3B turns heavyweight intelligence into a lightweight, deployable reality for local LLM inference. Built on a hybrid of Gated DeltaNet and Gated Attention with an ultra‑sparse MoE, it delivers big‑model accuracy with only a sliver of activated parameters, so teams get 10x+ faster long‑context inference at a fraction of the training budget.
In practical terms, that means less waiting, lower costs, and room to scale projects without renting a datacenter, making affordable LLM training and deployment truly viable. This guide breaks down the Qwen3‑Next architecture, the why behind its speedups, and some tips for faster LLM inference methods that actually move the needle. Whether building an on‑device coding assistant, a long‑context research copilot, or a multilingual content engine, Qwen3‑Next‑80B‑A3B shows how power users can run more with less, without compromising quality.
Read on to see what’s new, what’s different, and how to make the most of this model for local LLM inference.
What Makes This Qwen3-Next-80B-A3B Revolutionary?
Qwen3-Next-80B-A3B emerges as the flagship model in Alibaba's next-generation foundation model series, specifically designed to address the growing demands for both massive parameter scaling and ultra-long context processing. Unlike conventional large language models that activate all parameters during inference, this model employs an ultra-sparse Mixture-of-Experts (MoE) architecture that activates only 3.75% of its total parameters per token.
The model family includes two primary variants tailored for different use cases. Qwen3-Next-80B-A3B-Instruct focuses on instruction-following and content generation without thinking traces, making it ideal for production environments requiring stable, formatted outputs. Meanwhile, Qwen3-Next-80B-A3B-Thinking specializes in complex reasoning tasks with chain-of-thought capabilities, outperforming even proprietary models like Gemini-2.5-Flash-Thinking across multiple benchmarks.
What sets this model apart is its unprecedented efficiency without performance compromise. Despite using only 10% of the training resources required by Qwen3-32B, it consistently outperforms the latter across downstream tasks while delivering over 10x higher inference throughput when handling contexts longer than 32K tokens. This efficiency breakthrough stems from four core architectural innovations that work in harmony to maximize performance while minimizing computational overhead.
The model natively supports context lengths up to 262,144 tokens, which can be extended to over 1 million tokens using YaRN scaling techniques. This capability, combined with its sparse activation pattern, makes it particularly well-suited for applications requiring extensive context understanding, such as document analysis, code generation, and multi-turn conversations.
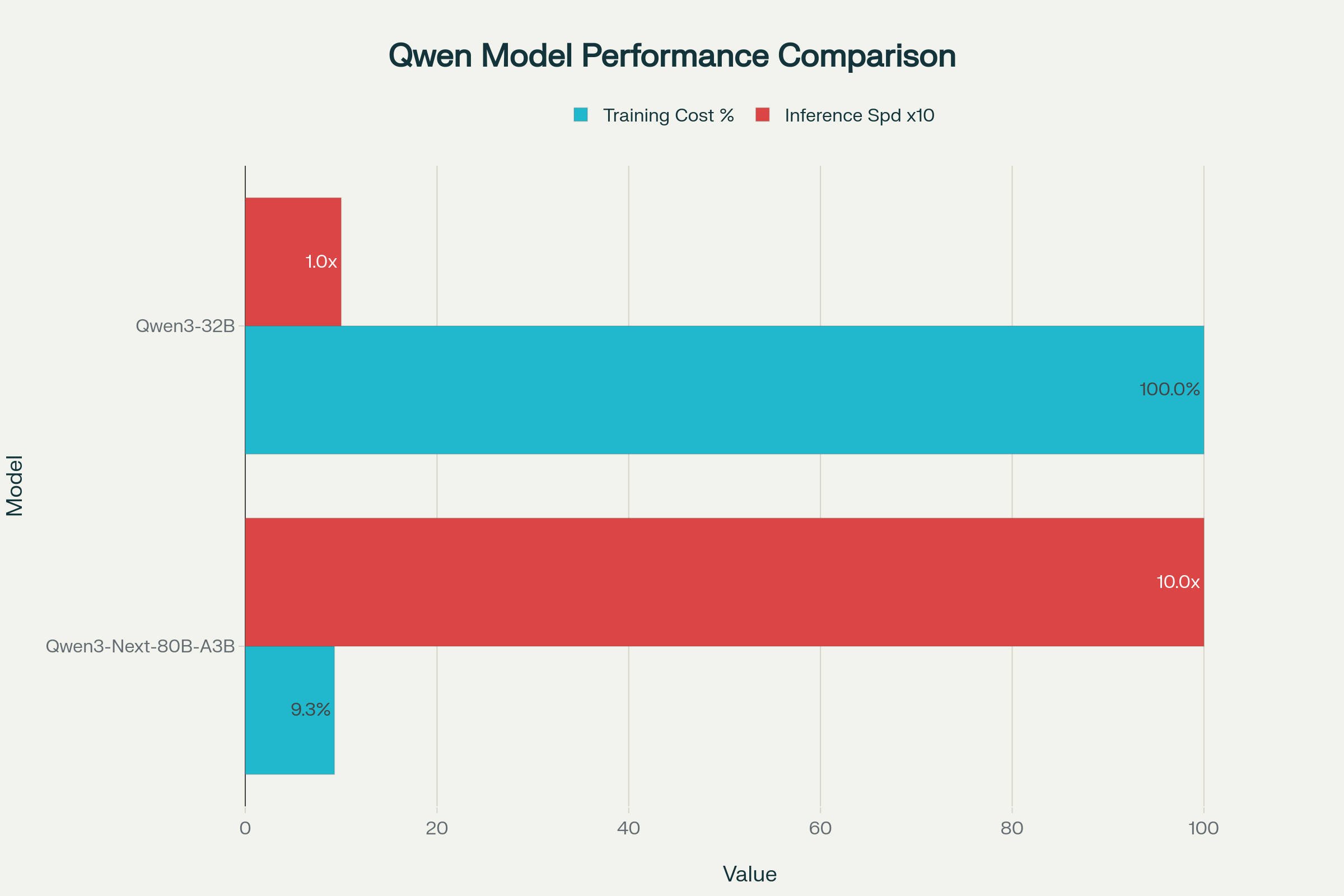
Qwen3-Next-80B-A3B Efficiency Comparison: Training Cost vs Inference Speed
(See the performance comparison chart showing 10x efficiency improvements)
Qwen3-Next-80B-A3B achieves up to 10x faster throughput than earlier Qwen3 models in prefill and decode tasks, highlighting its efficiency for local LLM inference
The Hybrid Architecture Explained: Gated DeltaNet + Gated Attention for Peak Performance
The revolutionary efficiency of Qwen3-Next-80B-A3B stems from its innovative hybrid attention mechanism that combines the best aspects of linear and standard attention approaches. This architectural breakthrough addresses a fundamental challenge in large language model design: linear attention excels at efficiency but struggles with information recall, while standard attention provides superior recall but at tremendous computational cost.
The solution implemented in Qwen3-Next employs a carefully orchestrated 3:1 hybrid ratio, where 75% of the model's 48 layers utilize Gated DeltaNet for efficient sequence processing, while the remaining 25% employ Gated Attention for high-precision information integration.
Qwen3-Next-80B-A3B Hybrid Architecture: 75% Gated DeltaNet + 25% Gated Attention
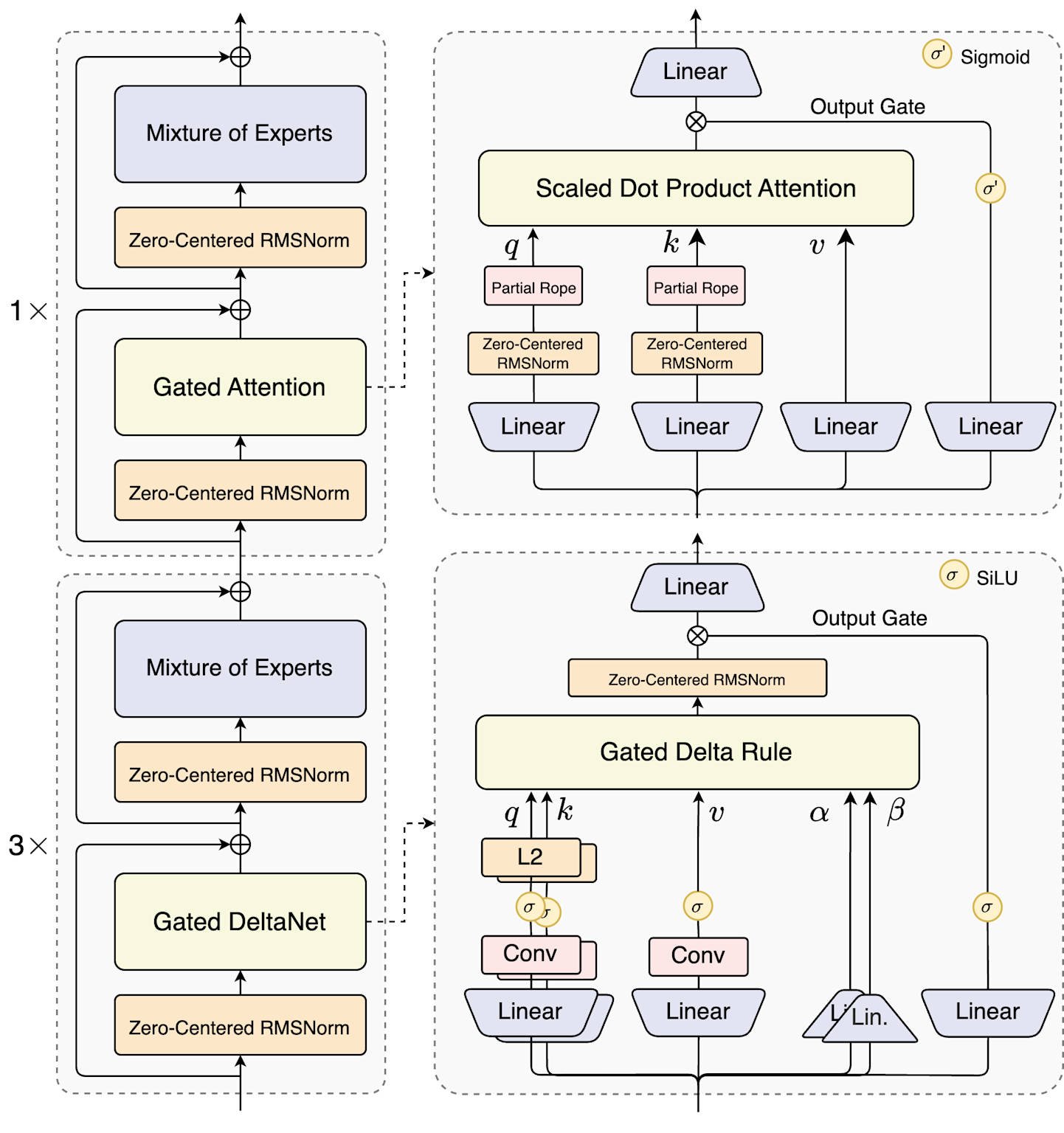
This strategic distribution ensures that most computational work is handled by the efficient linear attention mechanism, while critical information recall tasks are managed by the more computationally intensive but highly accurate standard attention layers.
Gated DeltaNet represents a significant advancement over commonly used alternatives like sliding window attention and Mamba2 in context learning ability. The mechanism employs 32 linear attention heads for value processing and 16 heads for query-key operations, each with a head dimension of 128. This configuration enables the model to process long sequences with linear computational complexity while maintaining strong performance on in-context learning tasks.
The Gated Attention component utilizes 16 attention heads for queries and 2 for key-value pairs, with an expanded head dimension of 256 compared to traditional implementations. Additionally, rotational position encoding is applied only to the first 25% of attention head dimensions, enhancing the model's ability to extrapolate to longer sequences than those seen during training.

This hybrid approach delivers measurable advantages in real-world performance. Compared to Qwen3-32B, the new architecture achieves 7x throughput improvement at 4K context and over 10x improvement at 32K+ context lengths during prefill stages. The decode stage similarly benefits, with 4x improvements at shorter contexts and maintaining 10x advantages for long-context scenarios.
Qwen3 Next 80B A3B Efficiency Breakthroughs
The efficiency gains achieved by Qwen3 Next 80B A3B represent a paradigm shift in how large language models can be trained and deployed cost-effectively. The model was trained on a carefully curated 15 trillion token subset of Qwen3's original 36 trillion token pre-training corpus, requiring less than 80% of the GPU hours needed for Qwen3-30B-A3B training. When compared directly to Qwen3-32B, the training resource requirements drop to an astounding 9.3% of the original computational needs while achieving superior performance across benchmarks.
These dramatic cost reductions stem from multiple architectural optimizations working in concert. The ultra-sparse MoE design activates only 10 routed experts plus 1 shared expert from a total pool of 512 experts, resulting in a mere 3.75% parameter activation rate during inference. This contrasts sharply with Qwen3's previous MoE implementation, which utilized 128 total experts with 8 routing experts, representing a 6.25% activation rate.
Training stability optimizations play a crucial role in enabling such extreme sparsity without performance degradation. The implementation includes Zero-Centered RMSNorm to address abnormal growth issues in layer normalization weights, along with weight decay applications to prevent unbounded parameter growth. Additionally, MoE router parameters are normalized during initialization to ensure unbiased expert selection during early training stages, reducing experimental variance and improving training convergence.
The inference efficiency improvements are equally impressive across different operational scenarios. At 4K context lengths, the model delivers 4x decode throughput improvements compared to Qwen3-32B, scaling to over 10x improvements when processing contexts beyond 32K tokens. These gains become even more pronounced during prefill operations, where the model achieves 7x speedup at 4K context and maintains its 10x advantage for longer sequences.
Ultra-Sparse MoE and Multi-Token Prediction: Turbo-Charged Speed
The speed advantages of Qwen3-Next-80B-A3B extend beyond architectural efficiency through its implementation of Multi-Token Prediction (MTP), a technique that fundamentally changes how the model generates text during inference. Unlike traditional language models that generate tokens sequentially one at a time, MTP enables the simultaneous prediction of multiple subsequent tokens, delivering 3-5x speed improvements in practical applications.
The MTP mechanism serves dual purposes in the Qwen3-Next architecture. During pre-training, it enhances the model's overall performance by learning richer representations through multi-step prediction tasks. During inference, it enables speculative decoding with high acceptance rates, where the model generates multiple token candidates simultaneously and validates them in parallel rather than sequentially.
This approach proves particularly effective when combined with dedicated inference frameworks. SGLang implementation with MTP configuration demonstrates significant throughput improvements, especially for longer context scenarios. The recommended MTP settings include 3 speculative steps with 4 draft tokens and top-k filtering, optimizing the balance between speed and accuracy.
The ultra-sparse MoE structure amplifies these speed benefits through its extreme parameter efficiency. With 512 total experts but only 10+1 activated per token, the model achieves what engineers describe as a "96.25% sparsity rate". This level of sparsity ensures that despite the model's massive 80B parameter count, actual computational requirements remain comparable to much smaller dense models.
Expert routing optimization ensures balanced load distribution across the 512 available experts, preventing performance bottlenecks that could arise from uneven utilization. The shared expert component provides consistent baseline processing for all tokens, while the 10 routed experts deliver specialized capabilities based on input characteristics.
Framework-specific optimizations further enhance these speed improvements. vLLM integration supports the full MTP pipeline with proper tensor parallelization across multiple GPUs. For maximum efficiency, the implementation includes support for flash-linear-attention and causal-conv1d optimizations, which provide additional acceleration for the linear attention components.
Benchmarks and Comparison
The theoretical efficiency gains of Qwen3-Next-80B-A3B translate into impressive real-world performance across diverse benchmark categories, demonstrating its practical value for production deployments. Comprehensive evaluation results show the model achieving 80.6% on MMLU-Pro and 90.9% on MMLU-Redux for knowledge tasks, placing it competitively against much larger models while using significantly fewer computational resources.
Qwen3-Next-80B-A3B-Instruct vs Qwen3-Next-80B-A3B-Thinking Benchmarks
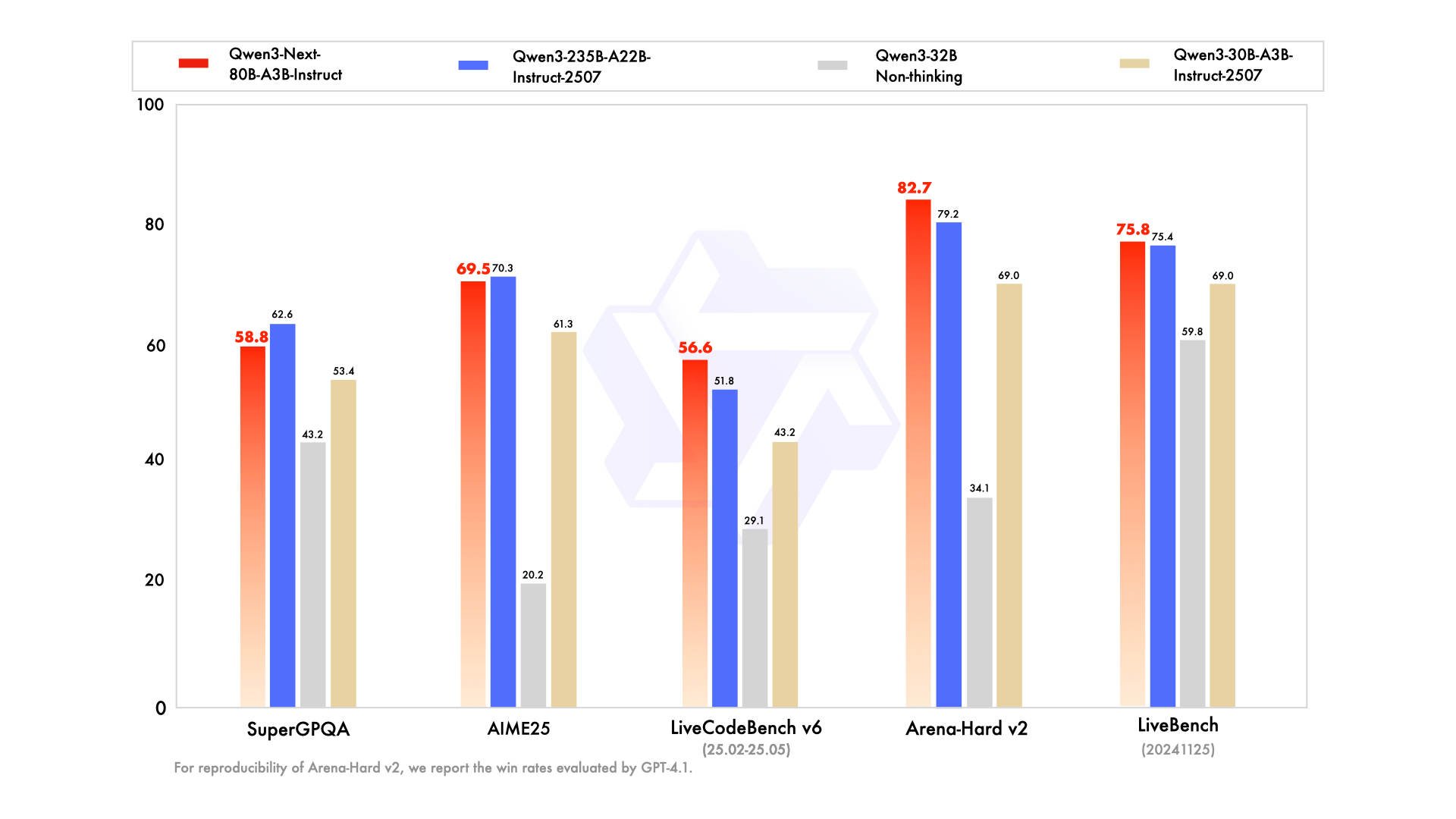
Qwen3-Next-80B-A3B-Instruct Officinal Benchmarks Compared
Qwen3-Next-80B-A3B-Thinking Official Benchmarks Compared
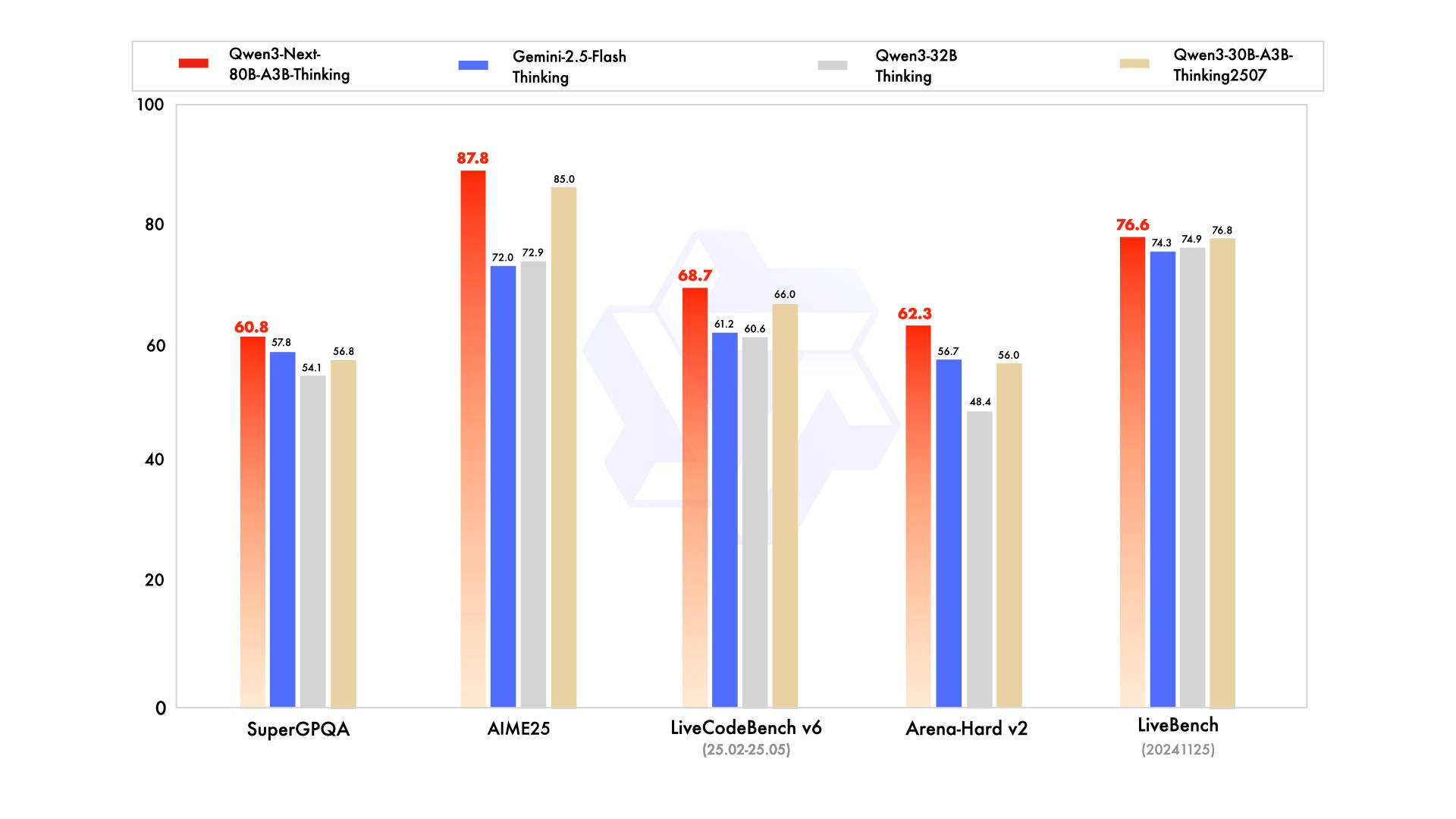
In complex reasoning scenarios, the model demonstrates particular strength with 69.5% accuracy on AIME25 mathematics problems and 54.1% on HMMT25 advanced mathematics competitions. These results approach the performance of Qwen3-235B-A22B-Instruct while utilizing less than 15% of the activated parameters, showcasing the effectiveness of the hybrid architecture for mathematical reasoning tasks.
Coding capabilities represent another area of exceptional performance, with the model achieving 56.6% on LiveCodeBench v6 and 87.8% on MultiPL-E programming benchmarks. These scores surpass the baseline Qwen3-32B model by substantial margins, particularly noteworthy given the model's focus on efficiency optimization. The performance improvements prove especially valuable for developers seeking to deploy local coding assistants without the infrastructure requirements of larger models.
Agent and tool-calling capabilities position Qwen3-Next-80B-A3B as an excellent choice for agentic workflows and automated task execution. The model scores 70.3% on BFCL-v3 function calling benchmarks and demonstrates strong performance across TAU retail and airline scenarios. Integration with Qwen-Agent framework enables sophisticated tool-calling workflows with MCP configuration support, reducing coding complexity for developers building AI-powered applications.
The model achieves 75.8% on MultiIF, 76.7% on MMLU-ProX, and 78.9% on INCLUDE multilingual benchmarks, demonstrating robust cross-lingual understanding without requiring language-specific fine-tuning.
Qwen3-Next-80B-A3B RULER - Context Benchmarks compared

Ultra-long context processing represents perhaps the most compelling real-world application area. The model maintains 91.8% average accuracy across the RULER benchmark suite when extended to 1 million tokens using YaRN scaling. Performance remains strong even at extreme context lengths, with 80.3% accuracy maintained at both 896K and 1M token contexts. This capability enables applications like comprehensive document analysis, extensive codebase understanding, and multi-session conversation continuity that would be less feasible with traditional dense models.
Transforming Local LLMs: The Path Forward
Qwen3-Next-80B-A3B marks a pivotal shift in local LLM deployment, proving that architectural innovation can rival brute-force scaling. Delivering 80B parameter performance at just 3B activation costs, it democratizes access to advanced AI by combining Gated DeltaNet with Gated Attention for unprecedented efficiency. This design challenges the “bigger is better” mindset, showing that smarter architectures can achieve superior results with dramatically reduced resource demands, making high-end AI viable for a far broader range of developers and organizations.
With 10× lower training costs, 10× faster inference, and native 262K context support, Qwen3-Next-80B-A3B unlocks applications once limited by infrastructure, ranging from coding assistants to large-scale document analysis and multilingual systems. Its Apache 2.0 open-source release ensures community-driven innovation, accelerating adoption of efficiency-first design principles across the AI ecosystem. This model stands as proof that the future of AI lies not in scaling endlessly, but in scaling intelligently.
Related Posts
- Best GPUs for LLM Inference 2025
- How to Enable Internet Access for Local LLMs
- Qwen-3 Max vs Qwen-3 235B Comparison
- Best Local LLMs for Coding 2025
- Run Local LLM on Windows Guide
Frequently Asked Questions
What makes Qwen3-Next-80B-A3B different from traditional dense LLMs?
Qwen3-Next-80B-A3B employs an ultra-sparse Mixture-of-Experts architecture that activates only 3.75% of its total parameters per token (3 billion out of 80 billion), compared to dense models that must activate every parameter. This enables 10x training cost reduction and 10x inference speed improvements while maintaining superior performance.
Can I run Qwen3-Next-80B-A3B on consumer GPUs?
Not on a single GPU. The 4 Bit quantized model requires about 50 GB VRAM for proper execution, You would need two consumer GPUs like RTX 4090.
How do the Instruct and Thinking variants differ?
Qwen3-Next-80B-A3B-Instruct focuses on instruction-following and content generation without thinking traces for production environments. Qwen3-Next-80B-A3B-Thinking specializes in complex reasoning with chain-of-thought capabilities, outperforming models like Gemini-2.5-Flash-Thinking across multiple benchmarks.
What inference frameworks support Qwen3-Next-80B-A3B?
The model supports SGLang with MTP for maximum speed, vLLM with tensor parallelism, and other frameworks. SGLang implementation with MTP provides 3-5x speed improvements through multi-token prediction.
How does YaRN scaling work with Qwen3-Next-80B-A3B?
YaRN (Yet Another RoPE Scaling) extends the model's context window beyond 262K tokens up to over 1 million tokens. This scaling technique maintains performance quality even at extreme context lengths, enabling applications that require processing massive document collections or extensive codebases within a single context window.